






python爬虫程序仍然在进行中,目前使用urllib、urllib2抓取网页数据,并解决了乱码问题,以及向网站提交表单,并取回网页返回的数据。
后来感觉requests比较简单,于是改成了用requests.

然而现在遇到一个非常蛋疼的问题就是关于网页的隐藏代码如何抓取呢?网页被隐藏代码是指:display:none的部分,在网页源代码看不到,但是在控制台可以看到。
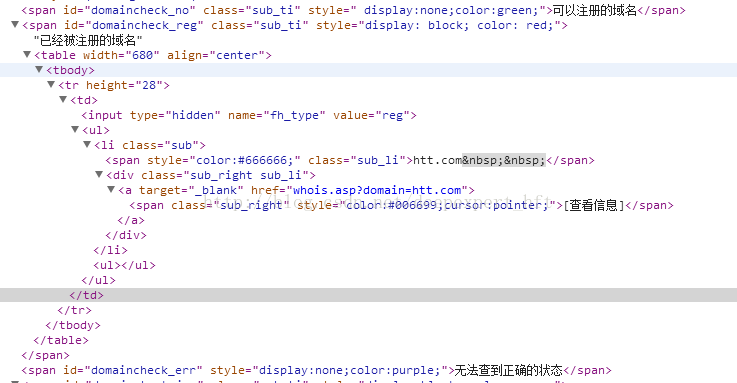

从上面两幅图片可以看出,第一图是网页的源代码,第二是我自己用程序抓取的内容,两幅图有不同的地方就是我抓取的数据有部分被隐藏起来了,我该怎么去区别域名是否可注册呢?目前遇到了一个很大的问题- -...爬虫正在继续奋斗中!
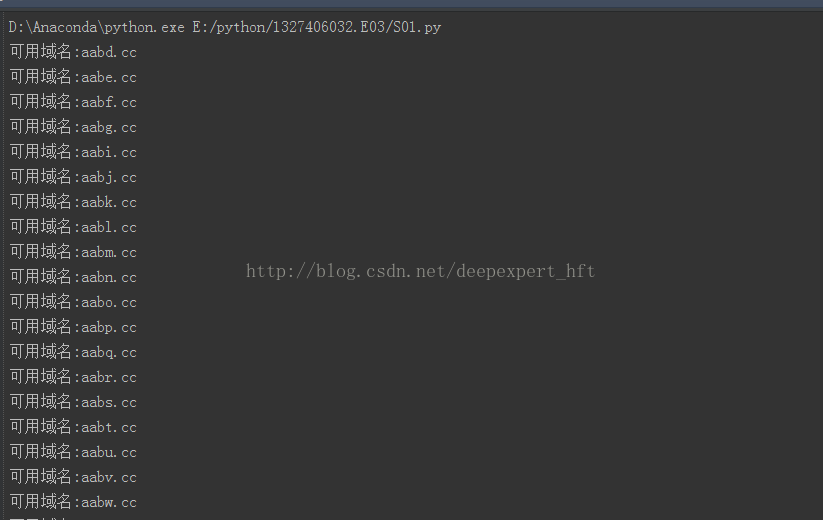
昨天由于提交表单的网址搞错了,一直没有产生结果,今天找到了正确的提交网址,程序已经能够按照我的意愿去执行并产生结果了,自己的第一个完整的python程序终于写好了,遇到了很多问题,也有很多收获,感觉很有成就感.下面附上我程序的一张结果图:

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









