






应用于自然语言处理的机器学习数据通常包含文本和数字输入。例如,当您通过twitter或新闻构建一个模型来预测产品未来的销售时,在考虑文本的同时考虑过去的销售数据、访问者数量、市场趋势等将会更有效。您不会仅仅根据新闻情绪来预测股价的波动,而是会利用它来补充基于经济指标和历史价格的模型。 这篇文章展示了如何在scikit-learn(对于Tfidf)和pytorch(对于LSTM / BERT)中组合文本输入和数字输入。
scikit-learn(例如用于Tfidf)
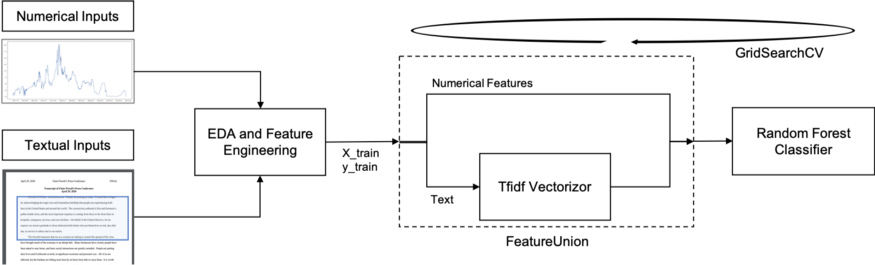
当你有一个包含数字字段和文本的训练dataframe ,并应用一个来自scikit-lean或其他等价的简单模型时,最简单的方法之一是使用sklearn.pipeline的FeatureUnion管道。
下面的示例假定X_train是一个dataframe ,它由许多数字字段和最后一列的文本字段组成。然后,您可以创建一个FunctionTransformer来分隔数字列和文本列。传递给这个FunctionTransformer的函数可以是任何东西,因此请根据输入数据修改它。这里它只返回最后一列作为文本特性,其余的作为数字特性。然后在文本上应用Tfidf矢量化并输入分类器。该样本使用RandomForest作为估计器,并使用GridSearchCV在给定参数中搜索最佳模型,但它可以是其他任何参数。
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipeline, FeatureUnion
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import FunctionTransformer
from sklearn.model_selection import GridSearchCV, StratifiedKFold
# Create Function Transformer to use Feature Union
def get_numeric_data(x):
return [record[:-2].astype(float) for record in x]
def get_text_data(x):
return [record[-1] for record in x]
transfomer_numeric = FunctionTransformer(get_numeric_data)
transformer_text = FunctionTransformer(get_text_data)
# Create a pipeline to concatenate Tfidf Vector and Numeric data
# Use RandomForestClassifier as an example
pipeline = Pipeline([
('features', FeatureUnion([
('numeric_features', Pipeline([
('selector', transfomer_numeric)
])),
('text_features', Pipeline([
('selector', transformer_text),
('vec', TfidfVectorizer(analyzer='word'))
]))
])),
('clf', RandomForestClassifier())
])
# Grid Search Parameters for RandomForest
param_grid = {'clf__n_estimators': np.linspace(1, 100, 10, dtype=int),
'clf__min_samples_split': [3, 10],
'clf__min_samples_leaf': [3],
'clf__max_features': [7],
'clf__max_depth': [None],
'clf__criterion': ['gini'],
'clf__bootstrap': [False]}
# Training config
kfold = StratifiedKFold(n_splits=7)
scoring = {'Accuracy': 'accuracy', 'F1': 'f1_macro'}
refit = 'F1'
# Perform GridSearch
rf_model = GridSearchCV(pipeline, param_grid=param_grid, cv=kfold, scoring=scoring,
refit=refit, n_jobs=-1, return_train_score=True, verbose=1)
rf_model.fit(X_train, Y_train)
rf_best = rf_model.best_estimator_
Scikit-learn提供了很好的api来管理ML管道,它只完成工作,还可以以同样的方式执行更复杂的步骤。
Pytorch(例如LSTM, BERT)
如果您应用深度神经网络,更常见的是使用Tensorflow/Keras或Pytorch来定义层。两者都有类似的api,并且可以以相同的方式组合文本和数字输入,下面的示例使用pytorch。
要在神经网络中处理文本,首先它应该以模型所期望的方式嵌入。有一个dropout 层也是常见的,以避免过拟合。该模型在与数字特征连接之前添加一个稠密层(即全连接层),以平衡特征的数量。最后,应用稠密层输出所需的输出数量。

class LSTMTextClassifier(nn.Module):
def __init__(self, vocab_size, embed_size, lstm_size, dense_size, numeric_feature_size, output_size, lstm_layers=1, dropout=0.1):
super().__init__()
self.vocab_size = vocab_size
self.embed_size = embed_size
self.lstm_size = lstm_size
self.output_size = output_size
self.lstm_layers = lstm_layers
self.dropout = dropout
self.embedding = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, lstm_size, lstm_layers, dropout=dropout, batch_first=False)
self.dropout = nn.Dropout(0.2)
self.fc1 = nn.Linear(lstm_size, dense_size)
self.fc2 = nn.Linear(dense_size + numeric_feature_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
hidden = (weight.new(self.lstm_layers, batch_size, self.lstm_size).zero_(),
weight.new(self.lstm_layers, batch_size, self.lstm_size).zero_())
return hidden
def forward(self, nn_input_text, nn_input_meta, hidden_state):
batch_size = nn_input_text.size(0)
nn_input_text = nn_input_text.long()
embeds = self.embedding(nn_input_text)
lstm_out, hidden_state = self.lstm(embeds, hidden_state)
lstm_out = lstm_out[-1,:,:]
lstm_out = self.dropout(lstm_out)
dense_out = self.fc1(lstm_out)
concat_layer = torch.cat((dense_out, nn_input_meta.float()), 1)
out = self.fc2(concat_layer)
logps = self.softmax(out)
return logps, hidden_state
class BertTextClassifier(nn.Module):
def __init__(self, hidden_size, dense_size, numeric_feature_size, output_size, dropout=0.1):
super().__init__()
self.output_size = output_size
self.dropout = dropout
# Use pre-trained BERT model
self.bert = BertModel.from_pretrained('bert-base-uncased', output_hidden_states=True, output_attentions=True)
for param in self.bert.parameters():
param.requires_grad = True
self.weights = nn.Parameter(torch.rand(13, 1))
self.dropout = nn.Dropout(dropout)
self.fc1 = nn.Linear(hidden_size, dense_size)
self.fc2 = nn.Linear(dense_size + numeric_feature_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input_ids, nn_input_meta):
all_hidden_states, all_attentions = self.bert(input_ids)[-2:]
batch_size = input_ids.shape[0]
ht_cls = torch.cat(all_hidden_states)[:, :1, :].view(13, batch_size, 1, 768)
atten = torch.sum(ht_cls * self.weights.view(13, 1, 1, 1), dim=[1, 3])
atten = F.softmax(atten.view(-1), dim=0)
feature = torch.sum(ht_cls * atten.view(13, 1, 1, 1), dim=[0, 2])
dense_out = self.fc1(self.dropout(feature))
concat_layer = torch.cat((dense_out, nn_input_meta.float()), 1)
out = self.fc2(concat_layer)
logps = self.softmax(out)
return logps
以上代码在前向传播时使用torch.cat将数字特征和文本特征进行组合,并输入到后续的分类器中进行处理。
作者:Yuki Takahashi
deephub翻译组


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









