









背景引入
方法一
表自连接
with data as (
select 'A' as from_user, 'B' as to_user union all
select 'A' as from_user, 'C' as to_user union all
select 'A' as from_user, 'D' as to_user union all
select 'A' as from_user, 'E' as to_user union all
select 'B' as from_user, 'A' as to_user union all
select 'B' as from_user, 'C' as to_user union all
select 'C' as from_user, 'A' as to_user union all
select 'D' as from_user, 'A' as to_user
)
select
t1.from_user,
t1.to_user,
if(t2.from_user is not null, 1, 0) as is_friend
from data t1 left join data t2 on t2.to_user = t1.from_user and t2.from_user = t1.to_user
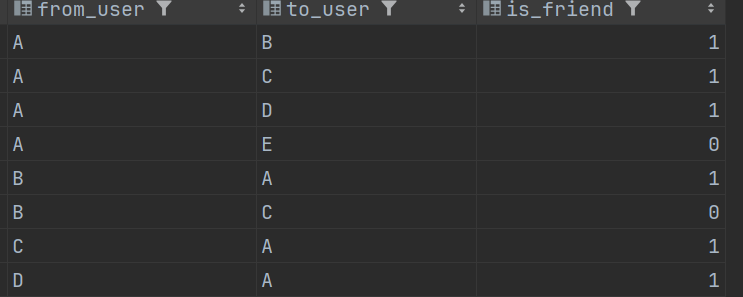
运行结果:
方法二
利用打标
with data as (
select 'A' as from_user, 'B' as to_user union all
select 'A' as from_user, 'C' as to_user union all
select 'A' as from_user, 'D' as to_user union all
select 'A' as from_user, 'E' as to_user union all
select 'B' as from_user, 'A' as to_user union all
select 'B' as from_user, 'C' as to_user union all
select 'C' as from_user, 'A' as to_user union all
select 'D' as from_user, 'A' as to_user
)
-- 方法二,利用打标
select
from_user,
to_user,
is_friend
from (
select
from_user,
to_user,
count(*) over(partition by flag) as is_friend
from (
select
from_user,
to_user,
if(from_user>to_user,concat(from_user,to_user),concat(to_user,from_user)) as flag
from data
)a
)b
where is_friend = 2;
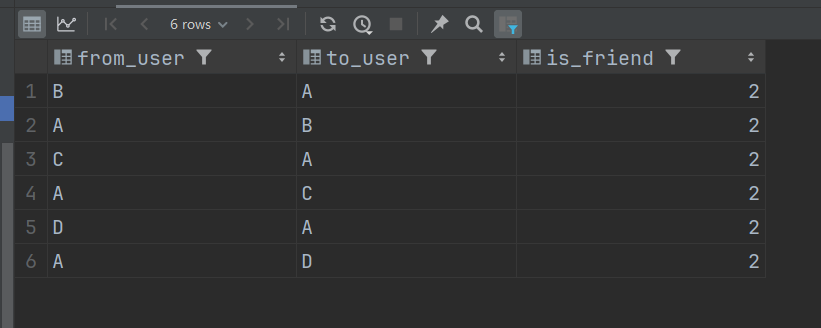
运行结果:
方法对比
第一种方法更加简便理解成本更低。
第二种方法使用了子查询并且利用了标记,大数据的情况下查询效率更加好。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









