







基于OpenPose和Human segmentation的游戏人物解析(附源码)
——基于PaddleHub的真人街霸游戏
街霸(Street Fighter)是大家非常熟悉的一个游戏。小时候我们都会和小伙伴们互相喊着“阿斗根”来发大招。现在借助于Paddlehub提供的视频人物分析技术,我们可以进入到街霸的世界里,虐别人和被虐。

一、游戏展示
b站链接:https://www.bilibili.com/video/BV1qi4y1P7db/
【AI创造营】马老师大战外国大力士RYU,闪电五连鞭一战成名!
二、实现思路
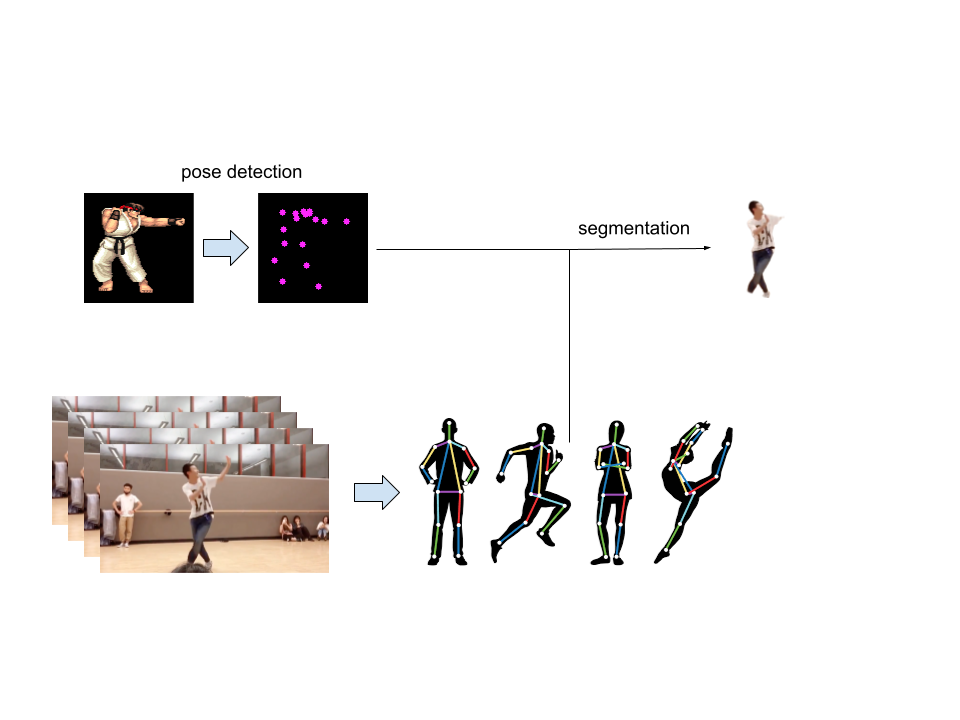
在视频中查找与游戏人物动作最接近的frame,抽取其中的人体部分,生成相应的GIF动图,作为游戏人物的素材。运行时左右侧游戏角色分别为images/RYU1和images/RUYU2.
三、使用
首先通过代码生成对应的*.gif, 然后用新生成的图替换StreetFighter/images/RYU1下的图。
浏览器打开StreetFighter/index.html即可,具体操作说明参见StreetFighter/README。
四、代码
# 导入必要的库
import os, sys
import cv2
from argparse import ArgumentParser
from tqdm import tqdm
import paddlehub as hub
import imageio
import numpy as np
from skimage.measure import label
#设定GPU来激活使用GPU
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 部分动作方向需要调整,比如倒下时的姿态,应该旋转90度后再去查找
angles = {'RYU1_beAttacked_fall_1': 90,
'RYU1_beAttacked_fall_2': 180,
'RYU1_beAttacked_fall_3': 90,
'RYU1_fall_down_0': 90,
'RYU1_fall_down_1': 90,
'RYU1_fall_down_2': 90,
'RYU1_heavy_kick_0': 90,
'RYU1_heavy_kick_1': 90,
'RYU1_heavy_kick_2': 90,
'RYU1_heavy_kick_3': 90,
'RYU1_jump_back_3': 90,
'RYU1_jump_back_4': 180,
'RYU1_jump_back_5': 270,
'RYU1_jump_forward_3': 270,
'RYU1_jump_forward_4': 180,
'RYU1_jump_forward_5': 90,
'RYU1_somesault_up_0': 90,
'RYU1_somesault_up_1': 180,
'RYU1_somesault_up_2': 180,
'RYU1_somesault_up_3': 270}
# 一些图像处理函数
# 等比例缩放
def resize_fix(image, size):
h, w = image.shape[:2]
dw, dh = size
scale = min(float(dw)/w, float(dh)/h)
return cv2.resize(image, (int(w*scale), int(h*scale)))
# 图像旋转(仅支持90 180 270 三种旋转)
def rotate(image, angle):
assert(angle in [0, 90, 270, 180])
if(angle == 0):
return image
elif(angle == 90):
for i in range(3):
image = np.rot90(image)
return image
elif(angle == 180):
return np.rot90(np.rot90(image))
else:
return np.rot90(image)
# 图像padding
def pad(image, scale):
h, w = image.shape[:2]
std_size = int(max(w, h) * scale)
full = np.zeros((std_size, std_size, 3), dtype=np.uint8)
left, top = (std_size-w)//2, (std_size-h)//2
full[top:top+h, left:left+w, :] = image
return full
# 单通道图--> 3通道图
def to3channels(mask):
h, w = mask.shape[:2]
mask3 = np.zeros((h,w,3), dtype=mask.dtype)
mask3[:,:,0] = mask
mask3[:,:,1] = mask
mask3[:,:,2] = mask
return mask3
# 读入GIF(实际是PNG 4通道图格式),并解析动作块(patch)
def read_gif(path):
reader = imageio.get_reader(path)
ims = []
try:
for im in reader:
ims.append(im)
except RuntimeError:
pass
reader.close()
assert(len(ims) == 1)
image = ims[0]
size = image.shape
h, w = image.shape[:2]
frames = []
boxes = []
mask = image[:,:,-1]
label_map, num = label(mask, neighbors=8, background=0, return_num=True)
for label_id in range(1, num+1):
mask = (label_map == label_id)
t, b, l, r = get_bbox(mask)
person_image = np.zeros((h, w, 3), dtype=np.uint8)
np.copyto(person_image, image[:,:,:-1], where=(to3channels(mask)>0))
frames.append(person_image[t:b, l:r, :])
boxes.append([t,b,l,r])
_, frames, bboxes = zip(*sorted(zip([(box[2]+box[3])/2 for box in boxes], frames, boxes)))
return frames, bboxes, size
# 获取mask中前景区域的bounding box
def get_bbox(mask):
h, w = mask.shape
mask[mask > 0] = 255
cols = np.max(mask, axis=0)
rows = np.max(mask, axis=1)
left = np.argmax(cols)
right = w - np.argmax(cols[::-1])
top = np.argmax(rows)
bottom = h - np.argmax(rows[::-1])
return [top, bottom, left, right]
# bounding box 扩大
def enlarge_bbox(bbox, scale, size):
h, w = size
t, b, l, r = bbox
width, height = r-l, b-t
scale = (scale - 1.) / 2.
t -= int(height * scale)
b += int(height * scale)
l -= int(width * scale)
r += int(width * scale)
t = max(0, min(h-1, t))
b = max(0, min(h-1, b))
l = max(0, min(w-1, l))
r = max(0, min(w-1, r))
return [t, b, l, r]
# segmentation的结果可能包含多个人体,仅保留area最大的那个作为结果,即仅使用最大的人作为筛查对象,来确保始终是同一个人在活动
def left_largest_patch(mask):
label_map, num = label(mask, neighbors=8, background=0, return_num=True)
high_val = np.max(mask)
largest_area = -float('inf')
largest_label_id = -1
for i in range(1, num+1):
cur_area = np.sum(label_map==i)
if(cur_area > largest_area):
largest_area = cur_area
largest_label_id = i
mask[label_map!=largest_label_id] = 0
mask[label_map==largest_label_id] = high_val
return mask
# 与left_largest_patch同理,仅保留最大的人的姿态
def select_largest_pose(poses):
pose = None
max_area = -float('inf')
for cur_pose in poses:
temp_pose = cur_pose[cur_pose != -1].reshape(-1,2)
left, top = np.min(temp_pose, axis=0)
right, bottom = np.max(temp_pose, axis=0)
area = (bottom-top)*(right-left)
if(area > max_area):
max_area = area
pose = cur_pose
return pose
# 归一化pose
def normalize(pose):
pose = pose[:, :2]
mask = (pose != -1).reshape(-1,2)
mask_un = (pose == -1).reshape(-1,2)
temp_pose = pose[mask].reshape(-1,2)
cx, cy = np.mean(temp_pose, axis=0)
left, top = np.min(temp_pose, axis=0)
right, bottom = np.max(temp_pose, axis=0)
pose = pose.astype(np.float)
dist = float(min(right-left, bottom-top))
pose[:, 0] -= left
pose[:, 0] /= float(right-left)
pose[:, 1] -= top
pose[:, 1] /= float(bottom-top)
pose[mask_un] = -1
return pose
# 计算两个pose之间的距离,这里-1的点表示在图中不可见,因此应当区别对待
# 对于两个pose中都存在的点,我们计算其L2距离;
# 对于两个pose中不都存在的点,对距离会产生惩罚,因为当其中一个pose中存在该点,而另一个不存在时,二者距离应当更大
def calc_dist(p, q):
assert(p.shape == q.shape)
mask = np.bitwise_and(p != -1, q != -1).reshape(p.shape)
unalign_dist = p.shape[0] - np.sum(mask)/2
p = p[mask].reshape(-1,2)
q = q[mask].reshape(-1,2)
dists = np.linalg.norm(p-q, ord=2, axis=1)
return np.mean(dists) + unalign_dist
# 在pool中查找与q距离最近的pose
def find_best_pose(q, pool):
idx = -1
min_dist = float('inf')
for i, p in enumerate(pool):
dist = calc_dist(q, p)
if(dist < min_dist):
min_dist = dist
idx = i
return idx
# 解析openpose模型的输出,得到固定大小的pose array,其中不可见的点为(-1,-1)
def parse_openpose_result(result):
subset = result['subset']
pts = result['candidate']
if(len(subset) == 0):
return np.zeros((0, 18), dtype=np.float)
poses = np.ones((subset.shape[0], 18, 2), dtype=np.int) * -1
for i in range(subset.shape[0]):
for index, pt_id in enumerate(subset[i,:18]):
pt_id = int(pt_id)
if(pt_id != -1):
poses[i, index, :] = pts[pt_id, :2]
return poses
# 根据输入的gif,返回一个新人物的gif
# image_path : input gif
# pose_estimation: pose detection model of paddlehub
# human_seg: human segmentation model of paddlehub
# pose_pool: the pool of poses extracted from the input video
# image_pool: the pool of frames extracted from the input video
def generate_pose_gif(image_path, pose_estimation, human_seg, pose_pool, image_pool, annotation):
action = image_path.split('/')[-1].split('.gif')[0]
# read query gif
frames, bboxes, size = read_gif(image_path)
gif = np.ones(size, dtype=np.uint8)*255
gif[:,:,-1] = 0
N = len(frames)
for i in range(N):
image = frames[i]
src_bbox = bboxes[i]
angle = angles['%s_%d'%(action, i)] if '%s_%d'%(action, i) in angles else 0
image = rotate(image, angle)
image = pad(image, 1.2)
# read pose from annotations
pose = annotation['%s_%d'%(action, i)]
query_pose = normalize(pose)
idx = find_best_pose(query_pose, pose_pool)
target_image = image_pool[idx]
mask = human_seg.segmentation(images=[target_image], use_gpu=True)[0]['data']
mask[mask > 0] = 255
mask = left_largest_patch(mask)
t, b, l, r = get_bbox(mask)
st, sb, sl, sr = src_bbox
person_image = np.ones((target_image.shape[0], target_image.shape[1], 3), dtype=np.uint8) * 255
np.copyto(person_image, target_image, where=(to3channels(mask)>0))
rgb = resize_fix(rotate(person_image[t:b, l:r, :], (360-angle)%360), (sr-sl, sb-st))
bg = resize_fix(rotate(mask[t:b, l:r], (360-angle)%360), (sr-sl, sb-st))
bg[bg!=0] = 255
offset_x = sl + (sr-sl-rgb.shape[1])//2
offset_y = st + (sb-st-rgb.shape[0])//2
gif[:,:,:-1][offset_y:offset_y+rgb.shape[0],offset_x:offset_x+rgb.shape[1],:] = rgb
gif[:,:,-1][offset_y:offset_y+rgb.shape[0],offset_x:offset_x+rgb.shape[1]] = bg
return gif
def augment(image):
images = []
images.append(image)
#images.append(image[:,::-1,:])
return images
if __name__ == "__main__":
source_dir='/home/aistudio/work/StreetFighter/images/RYU1'
search_video='/home/aistudio/work/mp4/dance.mp4'
dest_dir='/home/aistudio/work/output'
annotation=np.load('/home/aistudio/work/anno.npy', allow_pickle=True)[()]
pose_estimation = hub.Module(name='openpose_body_estimation')
human_seg = hub.Module(name="deeplabv3p_xception65_humanseg")
# 从search_video中抽取pose pool和image pool
reader = imageio.get_reader(search_video)
driving_video = []
step = 1
max_side = 640
index = 0
try:
for im in tqdm(reader):
if(index % step == 0):
image = im[..., ::-1]
h, w = image.shape[:2]
if(max(w, h) > 640):
scale = 640. / max(w, h)
nh, nw = int(h*scale), int(w*scale)
image = cv2.resize(image, (nw, nh))
driving_video.append(image)
index += 1
except RuntimeError:
pass
reader.close()
pose_pool = []
image_pool = []
for image in tqdm(driving_video):
for cur_image in augment(image):
result = pose_estimation.predict(cur_image)
poses = parse_openpose_result(result)
if(len(poses) > 0):
pose = select_largest_pose(poses)
pose_pool.append(normalize(pose))
image_pool.append(cur_image)
if(not os.path.exists(dest_dir)):
os.makedirs(dest_dir)
# 遍历所有gif,分别生成对应的gif
for fname in os.listdir(source_dir):
if(fname.endswith('.gif') and 'fire' not in fname):
print(fname)
gif = generate_pose_gif(os.path.join(source_dir, fname), pose_estimation, human_seg, pose_pool, image_pool, annotation)
dst_path = os.path.join(dest_dir, fname)
temp_path = dst_path.replace('.gif', '.png')
cv2.imwrite(temp_path, gif)
os.rename(temp_path, dst_path)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









