







向AI转型的程序员都关注公众号 机器学习AI算法工程
本项目开源了经过中文医学指令精调/指令微调(Instruction-tuning) 的大语言模型集,包括LLaMA、Alpaca-Chinese、Bloom、活字模型等。

我们基于医学知识图谱以及医学文献,结合ChatGPT API构建了中文医学指令微调数据集,并以此对各种基模型进行了指令微调,提高了基模型在医疗领域的问答效果。
基于相同的数据,我们还训练了医疗版本的ChatGLM模型: ChatGLM-6B-Med
完整项目代码获取地址:
关注微信公众号 datayx 然后回复 本草 即可获取。
方法
基模型在医学问答场景下效果有限,指令微调是一种高效的使基模型拥有回答人类问题能力的方法。
数据集构建
医学知识库我们采用了公开和自建的中文医学知识库,主要参考了cMeKG。
医学知识库围绕疾病、药物、检查指标等构建,字段包括并发症,高危因素,组织学检查,临床症状,药物治疗,辅助治疗等。知识库示例如下:
{"中心词": "偏头痛", "相关疾病": ["妊娠合并偏头痛", "恶寒发热"], "相关症状": ["皮肤变硬", "头部及眼后部疼痛并能听到连续不断的隆隆声", "晨起头痛加重"], "所属科室": ["中西医结合科", "内科"], "发病部位": ["头部"]}
我们利用GPT3.5接口围绕医学知识库构建问答数据,设置了多种Prompt形式来充分利用知识。
指令微调的训练集数据示例如下:
"问题:一位年轻男性长期使用可卡因,突然出现胸痛、呕吐、出汗等症状,经检查发现心电图反映心肌急性损伤,请问可能患的是什么疾病?治疗方式是什么?"
回答: 可能患的是心肌梗塞,需要进行维拉帕米、依普利酮、硝酸甘油、ß阻滞剂、吗啡等药物治疗,并进行溶栓治疗、低分子量肝素、钙通道阻滞剂等辅助治疗。此外需要及时停用可卡因等药物,以防止病情加重。"
我们提供了模型的训练数据集,共计八千余条,需要注意的是,虽然训练集的构建融入了知识,但是仍存在错误和不完善的地方,后续我们会利用更好的策略迭代更新数据集。
医学文献
此外,我们收集了2023年关于肝癌疾病的中文医学文献,利用GPT3.5接口围绕医学文献的【结论】构建多轮问答数据。在·./data_literature/liver_cancer.json中我们提供了其中的1k条训练样例。目前,训练样本的质量仍然有限,在后续我们会进一步迭代数据,会以公开数据集的形式对外进行发布。训练样本的示例如下:

模型效果对比
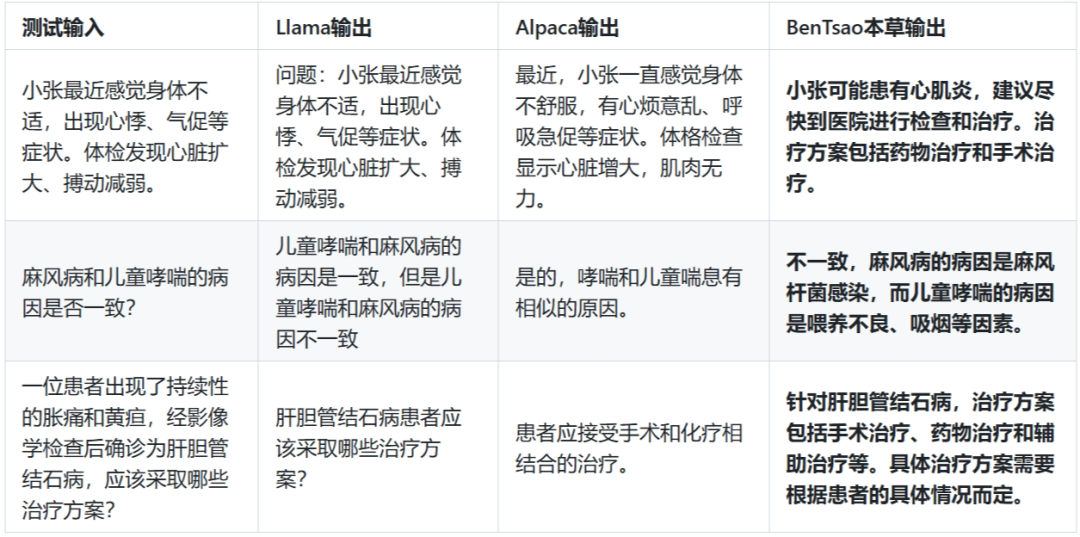
常见问题
Q: 为什么更名为"本草"?
A: 为SCIR实验室大语言模型命名一致性,中文医学大模型名称调整为"本草"。
Q: 为什么是"华驼"而不是"华佗"?
A: 叫”驼“是因为我们的基模型LLaMA是美洲驼,Alpaca是羊驼,受他们名字的启发以及华佗的谐音梗,我们将我们的模型起名为华驼。
Q: 有使用中医理论或者中医数据吗?
A: 目前还没有
Q: 模型运行的结果不同、效果有限
A: 由于生成模型生成多样性的考量,多次运行的结果可能会有差异。当前开源的模型由于LLaMA及Alpaca中文语料有限,且知识结合的方式较为粗糙,请大家尝试bloom-based和活字-based的模型。
Q: 模型无法运行/推理内容完全无法接受
A: 请确定已安装requirements中的依赖、配置好cuda环境并添加环境变量、正确输入下载好的模型以及lora的存储位置;推理内容如存在重复生成或部分错误内容属于llama-based模型的偶发现象,与llama模型的中文能力、训练数据规模以及超参设置均有一定的关系,请尝试基于活字的新模型。如存在严重问题,请将运行的文件名、模型名、lora等配置信息详细描述在issue中,谢谢大家。
Q: 发布的若干模型哪个最好?
A: 根据我们的经验,基于活字模型的效果相对更好一些。
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









