







商业实战将归巢网内容构建为本地RAG模型的完整指南01-优雅草卓伊凡
今天卓伊凡收到了老客户归巢网关于对本地RAG模型建立的咨询,这点也让卓伊凡得深入研究下,毕竟老客户肯定不是说着玩的,主要最终实现目的是建立模型开始使用AI智能问答。

一、项目规划与准备阶段
1.1 确定项目范围和技术栈
首先需要明确您希望从归巢网提取哪些内容以及如何使用这些数据:
- 内容范围选择:
-
- 全站抓取 vs 特定栏目(如新闻、产品、论坛等)
- 静态页面 vs 动态生成内容
- 文本内容 vs 多媒体内容
- 技术栈选择:
graph TD
A[数据采集] --> B[文本处理]
B --> C[向量化]
C --> D[存储]
D --> E[检索]
E --> F[生成]
F --> G[部署]1.2 硬件资源评估
根据归巢网的数据量预估所需资源:
| 数据规模 | 推荐配置 | 存储需求 | 处理时间预估 |
| <1万页 | 16GB RAM | 50GB SSD | 2-4小时 |
| 1-10万页 | 32GB RAM | 200GB SSD | 1-2天 |
| >10万页 | 64GB+ RAM | 1TB+ SSD | 1周+ |
二、数据采集与处理
2.1 网站内容爬取
使用专业工具获取归巢网内容:
- 爬虫工具选择:
-
- Scrapy(Python框架)
- BeautifulSoup + Requests(简单页面)
- Puppeteer(处理JavaScript渲染)
- 示例Scrapy爬虫:
import scrapy
from scrapy.linkextractors import LinkExtractor
class GuichaoSpider(scrapy.Spider):
name = 'guichao'
allowed_domains = ['guichao.com']
start_urls = ['https://www.guichao.com']
def parse(self, response):
# 提取正文内容
yield {
'url': response.url,
'title': response.css('h1::text').get(),
'content': ' '.join(response.css('article p::text').getall()),
'last_updated': response.css('.date::text').get()
}
# 跟踪链接
for link in LinkExtractor(allow_domains=self.allowed_domains).extract_links(response):
yield scrapy.Request(link.url, callback=self.parse)- 爬取策略优化:
-
- 设置合理的
robots.txt遵守规则 - 控制请求频率(
DOWNLOAD_DELAY = 2) - 处理分页和动态加载内容
- 设置合理的
2.2 数据清洗与预处理
对抓取的原始数据进行标准化处理:
- 文本清洗流程:
def clean_text(text):
# 移除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 移除特殊字符
text = re.sub(r'[\u200b-\u200f]', '', text)
# 标准化空白字符
text = ' '.join(text.split())
return text.strip()- 内容结构化:
-
- 识别并提取正文核心内容
- 分离元数据(作者、发布时间等)
- 处理多模态内容(图片alt文本等)
- 数据分块策略:
-
- 按语义段落分块(300-500字)
- 重叠窗口设置(50-100字)
- 特殊内容处理(表格、代码块等)
三、向量化与索引构建
3.1 嵌入模型选择
根据中文特性选择合适的嵌入模型:
| 模型名称 | 特点 | 维度 | 中文优化 |
| bge-small-zh | 轻量级 | 512 | 是 |
| text2vec-large-chinese | 高精度 | 1024 | 是 |
| multilingual-e5 | 多语言 | 768 | 部分 |
3.2 构建向量数据库
使用FAISS或Chroma等工具存储向量:
- FAISS索引构建:
import faiss
import numpy as np
# 假设embeddings是numpy数组
d = 768 # 向量维度
index = faiss.IndexFlatIP(d) # 内积相似度
index.add(embeddings)
# 优化索引
quantizer = faiss.IndexFlatL2(d)
index = faiss.IndexIVFPQ(quantizer, d, 100, 8, 4)
index.train(embeddings)
index.add(embeddings)- ChromaDB示例:
import chromadb
client = chromadb.PersistentClient(path="guichao_db")
collection = client.create_collection("guichao_content")
# 批量添加文档
collection.add(
documents=["doc1文本内容", "doc2文本内容", ...],
metadatas=[{"source": "news"}, {"source": "product"}, ...],
ids=["id1", "id2", ...]
)- 元数据关联:
-
- 保留原始URL便于溯源
- 存储时间戳用于时效性过滤
- 添加内容类型标签
四、RAG系统集成
4.1 检索增强生成架构
构建端到端的RAG流程:
sequenceDiagram
用户->>+系统: 输入问题
系统->>+检索器: 问题向量化
检索器->>+向量库: 相似度查询
向量库-->>-检索器: 返回top-k文档
检索器->>+生成模型: 问题+相关文档
生成模型-->>-系统: 生成回答
系统-->>-用户: 返回答案4.2 本地LLM选择与部署
适合中文的本地大语言模型:
- 推荐模型:
-
- ChatGLM3-6B(清华)
- Qwen-7B(阿里通义)
- MiniCPM(面壁智能)
这个部分我们在考虑用清华的,还是阿里的,当然了 关于使用deepseek的也是后面继续提出的方案

阿里
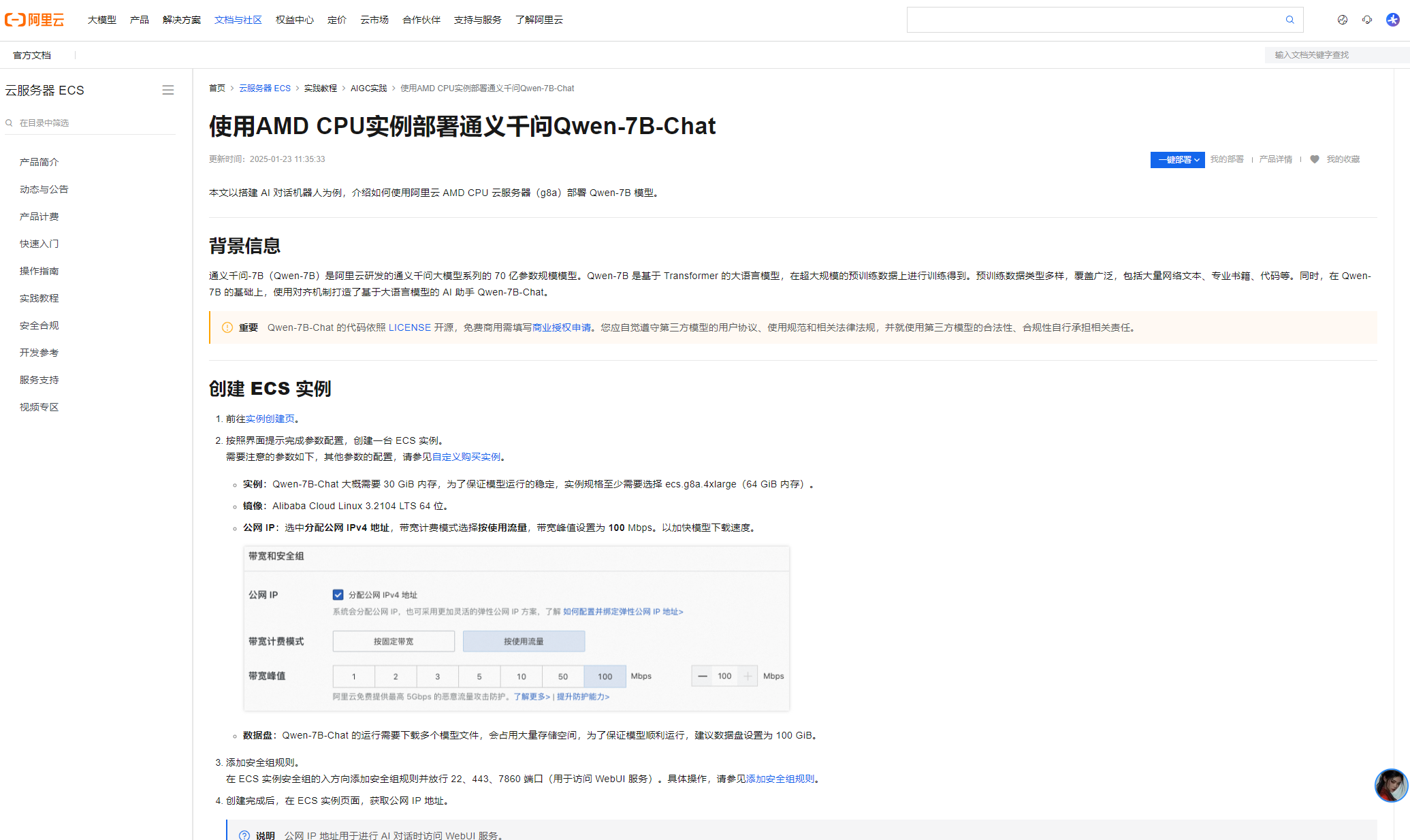
- Ollama部署示例:
# 安装Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 下载模型
ollama pull qwen:7b
# 运行API
ollama serve- LangChain集成:
from langchain_community.llms import Ollama
from langchain_core.prompts import ChatPromptTemplate
llm = Ollama(model="qwen:7b")
prompt = ChatPromptTemplate.from_template("""
基于以下归巢网内容回答问题:
{context}
问题:{question}
""")
chain = prompt | llm五、系统优化与评估
5.1 检索优化策略
提高相关文档召回率:
- 查询扩展:
-
- 同义词扩展
- 问题重写(使用LLM生成变体)
- 混合检索:
def hybrid_search(query):
# 向量检索
vector_results = vector_index.search(query_embedding, k=5)
# 关键词检索
keyword_results = bm25_retriever.search(query, k=5)
# 结果融合
return reciprocal_rank_fusion(vector_results, keyword_results)- 相关性过滤:
-
- 设置相似度阈值(如>0.65)
- 基于元数据过滤过时内容
5.2 生成质量提升
优化回答生成效果:
- 提示工程:
RAG_PROMPT = """
你是一个专业的归巢网助手,请严格根据提供的上下文回答问题。
上下文:
{context}
问题:{question}
要求:
- 回答不超过100字
- 如不清楚请回答"根据归巢网现有信息无法确定"
- 保留专业术语
"""- 后处理:
-
- 事实一致性检查
- 引用来源标注
- 敏感信息过滤
- 评估指标:
-
- 回答相关性(0-5分)
- 事实准确性(%)
- 响应延迟(秒)
六、部署与持续维护
6.1 本地化部署方案
构建可用的端到端系统:
- Docker编排:
# docker-compose.yml
version: '3'
services:
retriever:
image: chromadb/chroma
ports:
- "8000:8000"
llm:
image: ollama/ollama
ports:
- "11434:11434"
api:
build: .
ports:
- "5000:5000"- API接口设计:
from fastapi import FastAPI
app = FastAPI()
@app.post("/ask")
async def ask_question(question: str):
docs = retrieve(question)
answer = generate(question, docs)
return {"answer": answer, "sources": [d.metadata for d in docs]}- 用户界面:
-
- Gradio快速搭建:
import gradio as gr
def respond(message, history):
return chain.invoke({"question": message})
gr.ChatInterface(respond).launch()6.2 持续更新机制
保持内容时效性:
- 增量爬取:
-
- 监控sitemap.xml变化
- 设置每日/每周定时任务
- 版本控制:
-
- 使用DVC管理数据版本
- 保留多个版本的向量索引
- 自动评估:
-
- 定期运行测试问题集
- 监控回答质量变化
七、安全与合规考量
7.1 法律风险规避
确保项目合法合规:
- 版权审查:
-
- 确认归巢网的使用条款
- 考虑合理使用(fair use)范围
- 数据安全:
-
- 用户查询日志加密
- 敏感内容过滤
- 免责声明:
-
- 明确标注信息来源
- 说明AI生成内容的不确定性
7.2 访问控制
保护系统安全:
- 认证机制:
-
- JWT令牌验证
- IP白名单限制
- 限流保护:
-
- 令牌桶算法限流
- 防止高频查询攻击
结语:构建智能知识助手的完整路径
将归巢网转化为本地RAG系统是一个涉及多个技术环节的系统工程。通过本指南介绍的步骤,您可以:
- 完整获取归巢网的优质内容
- 高效组织成可检索的知识库
- 智能响应用户的各种查询
- 安全部署到本地环境
关键成功要素包括:
- 选择适合中文处理的嵌入和生成模型
- 设计合理的检索-生成交互流程
- 建立持续更新的内容机制
最终实现的系统不仅能够提供准确的问答服务,还能确保所有数据都在本地环境中处理,满足数据隐私和安全需求。随着技术迭代,您可以进一步:
- 集成更多归巢网的子站点
- 添加多轮对话能力
- 优化针对专业领域的效果
建议开发过程中使用工具链:
- 数据处理:Scrapy + Unstructured
- 向量存储:ChromaDB + FAISS
- 生成模型:Ollama + LangChain
- 部署监控:FastAPI + Prometheus



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











