







开工前的资源准备
1、电脑安装VMware Fusion,并安装centos 7
2、下载需要的工具包
一、虚拟机配置联网
3台虚拟机都安装完毕处于原始状态,这个时候虚拟机还是处于不可联网的状态,需要配置虚拟机处于可以联网,配置方式如下:
设置 -> 网络适配器 -> 与我的mac共享(NAT模式)
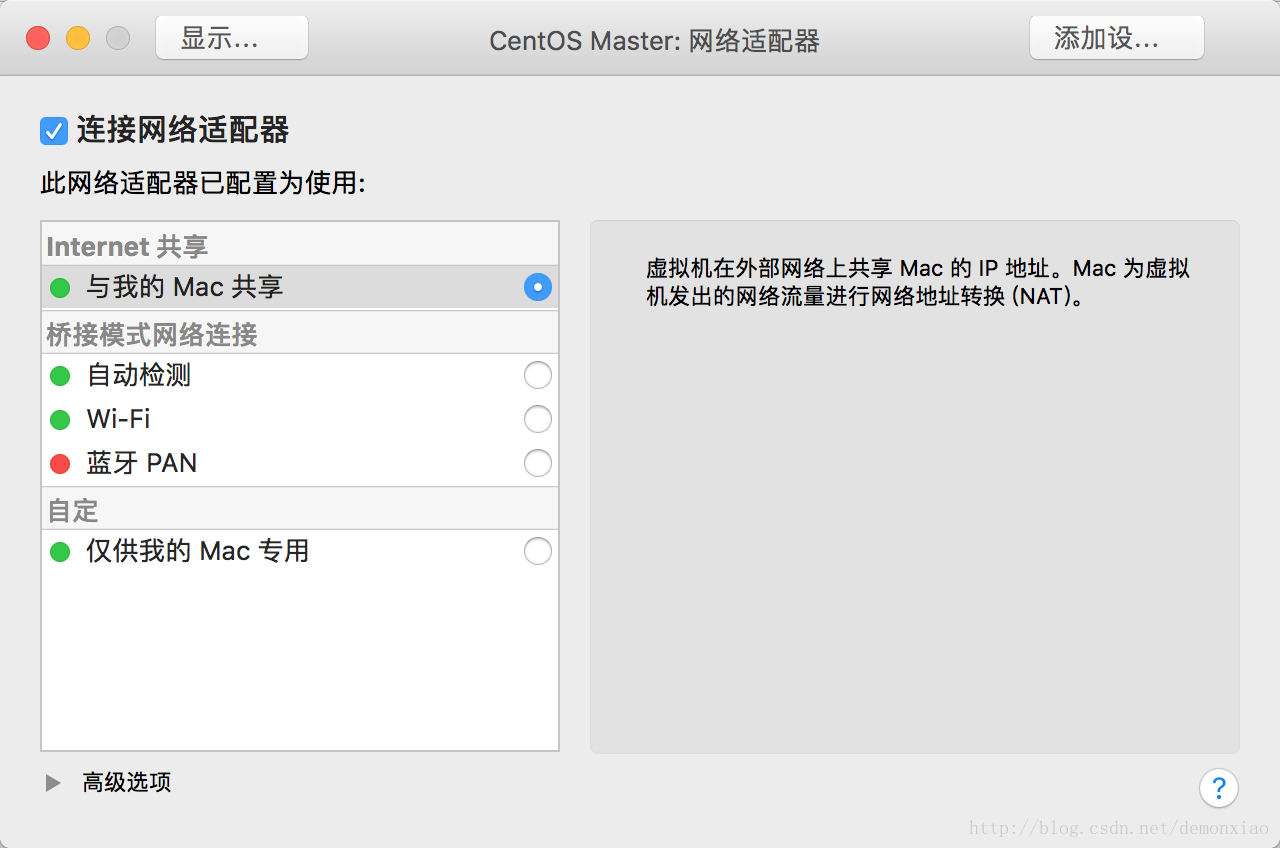
设置完之后,打开mac的终端,输入命令:
cat /Library/Preferences/VMware\ Fusion/vmnet8/nat.conf这个时候在终端窗口中会显示出一大串。我们需要的是其中最前面的一块:

在这边,记住这个IP地址,因为后续配置虚拟机上网都的时候会用到。
接着到Mac的系统偏好设置中,打开网络,点击右下角的高级按钮,在新出现的对话框中,选择DNS,然后记下这个DNS地址。

接下来到虚拟机中,输入一下命令:
vi /etc/sysconfig/network-scripts/ifcfg-eno16777736打开网卡配置,默认网卡配置如截图显示:
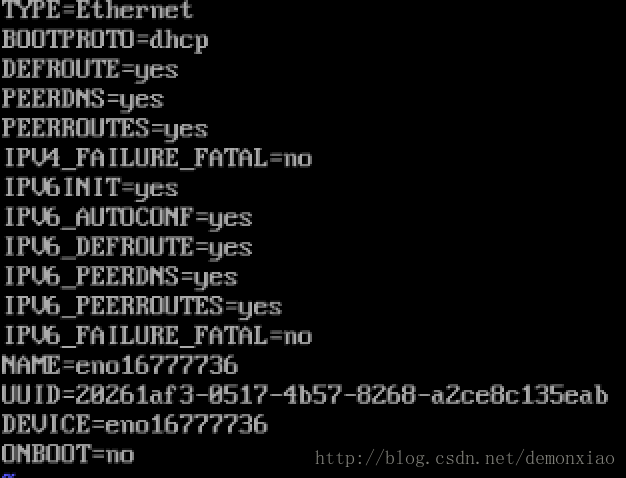
这个时候,我们应该改的东西有:
BOOTPROTO=static
ONBOOT=yes在后面加上:
IPADDR=172.16.134.252
NETMASH=255.255.255.0
PREFIX=24
IPV6_PRIVACY=no
DNS1=172.16.52.184
GATEWAY=172.16.134.2其中GATEWAY就是刚刚我们查询到的IP,DNS1则是查询到的DNS地址。
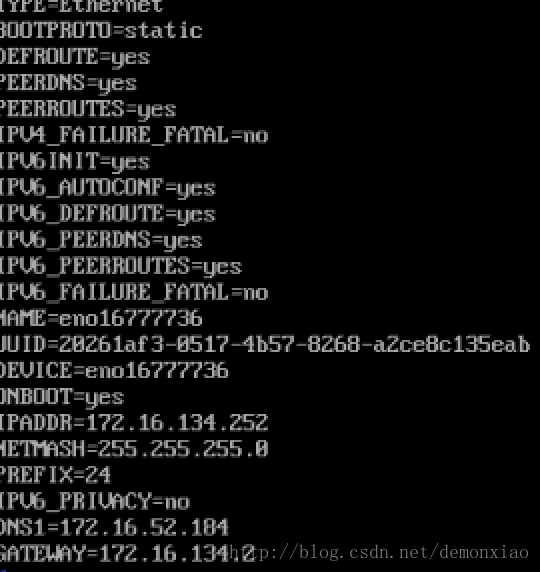
保存完之后,输入下列命令重启网卡:
service network restart重启之后ping一下看是否能通:

这个时候网络已经能连接通了,在剩下的两台虚拟机中也是做相同的配置。注意IP别搞混了。
二、新增配置用户
用root用户登录,然后创建一个登录名为hadoop的用户,并修改对应的密码:
useradd -m hadoop -s /bin/bash
passwd hadoop
完成之后。修改用户的对应权限:
visudo打开后直接输入 :98 可以跳转到对应的行数,在原有的root后面把hadoop用户的权限也加上:

保存退出即可,这个时候就可以直接su hadoop切换到hadoop用户了。(其他两台服务器也是同样的操作)
三、配置ssh免密登录
切换到hadoop用户后,输入下列命令生成公私钥:
ssh-keygen -t rsa这边会询问,直接三个回车就完成生成操作了。
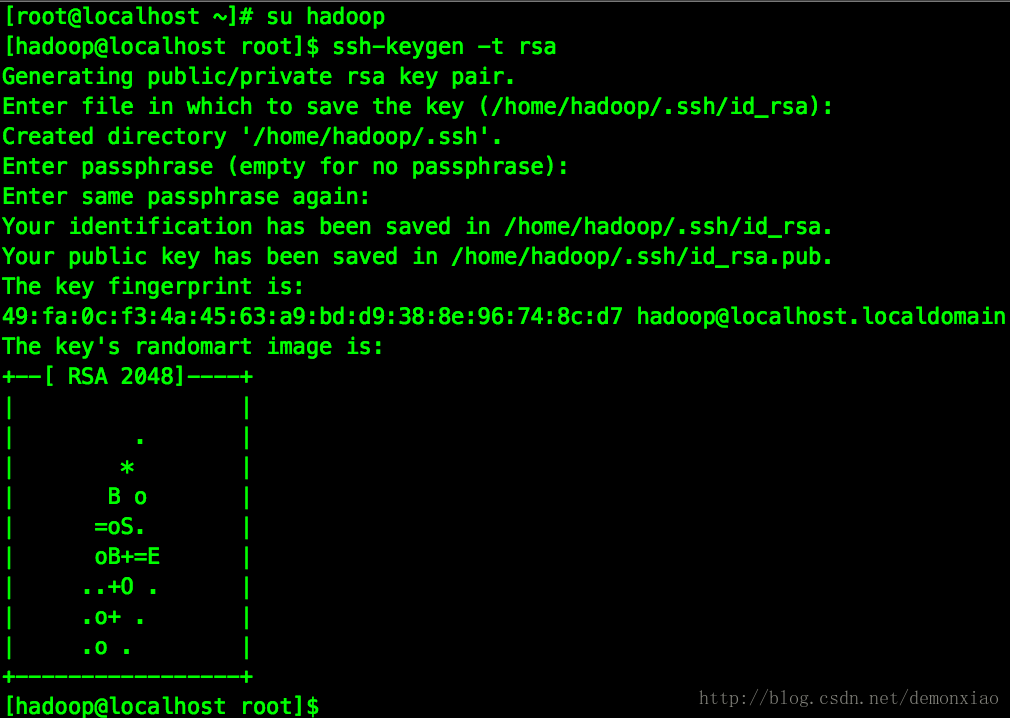
这个时候在 ~/.ssh/目录下就会生成对应的公私钥:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1931
1931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









