






 本文介绍了一个项目,利用Python进行安卓音频捕获,通过声纹识别技术判断与样本的相似度,实现点赞或“不感兴趣”的自动操作。涉及的技术包括Voicemeeter8Setup、Spleeter、Resemblyzer、ffmpeg和ADB工具,以及如何设置相似度阈值和进行屏幕操作。
本文介绍了一个项目,利用Python进行安卓音频捕获,通过声纹识别技术判断与样本的相似度,实现点赞或“不感兴趣”的自动操作。涉及的技术包括Voicemeeter8Setup、Spleeter、Resemblyzer、ffmpeg和ADB工具,以及如何设置相似度阈值和进行屏幕操作。
整个项目实现的功能是:
先捕获安卓的音频,然后进行声纹识别,判断与给定的样本的相似度达到一定的阀值,则点赞否则点击“不感兴趣”,这样,随着抖音推荐算法和程序的运行,推荐的视频越来越接近给定的样本。
项目架构:
- scrcpy 用于捕获音频到Windows系统
- Voicemeeter8Setup.exe(potato版)用于内录
- spleeter Python的人声提取库
- resemblyzer Python的声纹库
- ffmpeg人声提取库的依赖
需要注意的点
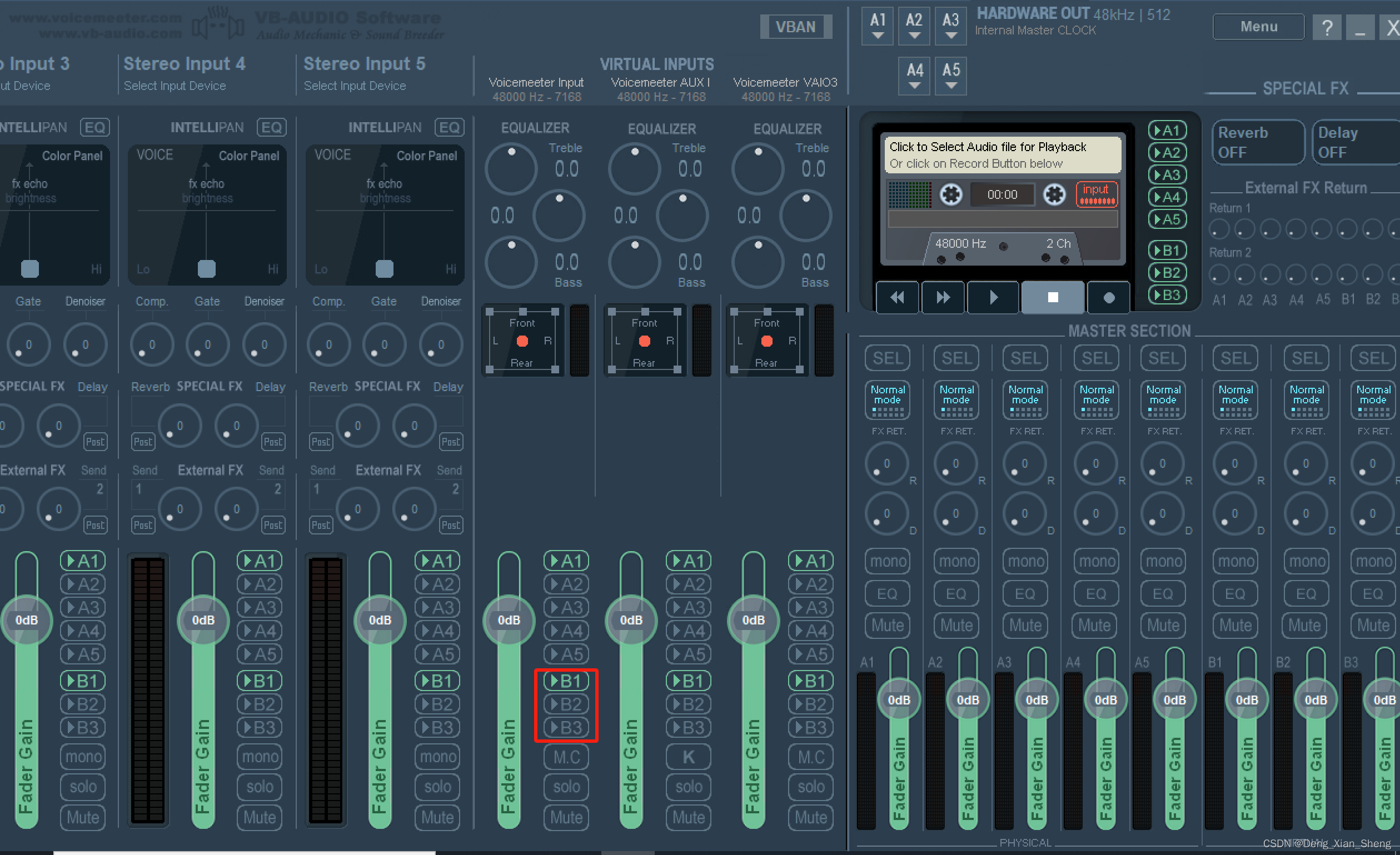
Voicemeeter8Setup
B1、B2、B3,勾选其一,然后用以下Python代码查看当前录音所用的设备以及可用设备列表:
sd.query_devices()
确保使用了以上勾选的,否则需使用device指定设备,例如:
audio_data = sd.rec(int(duration * sampling_rate), samplerate=sampling_rate, channels=2, dtype='float64', device=11)
ADB
adb控制安卓所使用的坐标并不是通用的,按需调整。
若想获取坐标,请在安卓手机的“开发者选项”中,找到“指针位置”(或类似命名的选项,如“显示触摸数据”)并启用它。
如果执行命令出错,则尝试:
adb start-server
scrcpy
scrcpy在2.0版本中开始支持捕获音频,但是需要确保>=安卓11,详情请见:https://github.com/Genymobile/scrcpy/blob/master/doc/audio.md
若手机系统不支持升级到更高版本(安卓11),可使用LineageOS有很多小惊喜
resemblyzer
虽然已经提取了人声,但是声纹库在这上面表现不佳。
如果待比对的声音与给定的声音样本是同一人不同时空的录音,其相似度(余弦相似度)>=0.8,保守一点>=0.85,而即使是>=0.8仍有少数根本不可能相似的音频得到了过高的相似度。
所以,我建议阀值设为>=0.86,即使是会忽略一些“待比对的声音与给定的声音样本是同一人不同时空的录音”但是更保守。
Python
必须使用Python3.8否则无法使用pip安装上spleeter
代码部分:
import random
import time
import librosa
from spleeter.separator import Separator
from resemblyzer import VoiceEncoder
import os
import sounddevice as sd # 导入用于录音的库
import soundfile as sf
from scipy.spatial.distance import cosine
def record_audio(separator, voiceEncoder, duration=5, sampling_rate=48000):
# 使用sounddevice录音
print("开始录音...")
audio_data = sd.rec(int(duration * sampling_rate), samplerate=sampling_rate, channels=2, dtype='float64')
sd.wait() # 等待录音结束
print("录音结束。")
# 写入
sf.write("temp.wav", audio_data, sampling_rate)
# 使用Spleeter提取人声
separator.separate_to_file("temp.wav","output")
librosa_audio, _ = librosa.load("output/temp/vocals.wav", sr=sampling_rate)
# 使用Resemblyzer
return voiceEncoder.embed_utterance(librosa_audio)
def compare_voice(separator, voiceEncoder, embedding1):
embedding2 = record_audio(separator, voiceEncoder)
# 计算两个嵌入之间的相似度
similarity = 1 - cosine(embedding1, embedding2)
print(f"相似度:{similarity}")
# return similarity >= 0.86
return similarity >= 0.70
def swipe_screen():
# 上滑起始坐标
start_x = 559 + random.randint(-1, 1)
start_y = 1435 + random.randint(-1, 1)
# 上滑结束坐标
end_x = 554 + random.randint(-1, 1)
end_y = 500 + random.randint(-1, 1)
# 在200毫秒至500毫秒之间随机选择持续时间
duration = random.randint(200, 500)
# 构造上滑命令字符串
swipe_command = f"C:\\Users\\likewendy\\Downloads\\platform-tools-latest-windows\\platform-tools\\adb.exe shell input swipe {start_x} {start_y} {end_x} {end_y} {duration}"
# 执行上滑命令
os.system(swipe_command)
def click_button(similar):
if similar:
# 原始坐标
# 发现页播放页的喜欢 坐标
# base_x = 1008
# base_y = 865
# 作者页播放页的喜欢 坐标
# base_x = 1000
# base_y = 996
# 在5的范围内随机,确保结果是整数
# x = base_x + random.randint(-1, 1)
# y = base_y + random.randint(-1, 1)
# # 构造命令字符串,使用f-string包含变量
# command = f"C:\\Users\\likewendy\\Downloads\\platform-tools-latest-windows\\platform-tools\\adb.exe shell input tap {x} {y}"
# 点击操作坐标
x = 554 + random.randint(-1, 1)
y = 900 + random.randint(-1, 1)
duration = random.randint(50, 100) # 浮动
# 构造点击命令字符串
command = f"C:\\Users\\likewendy\\Downloads\\platform-tools-latest-windows\\platform-tools\\adb.exe shell input tap {x} {y}"
# 执行命令
os.system(command)
time.sleep(duration / 1000)
os.system(command)
time.sleep(1)
# 上滑操作
swipe_screen()
else:
# 长按操作坐标和持续时间
long_press_x = 484 + random.randint(-1, 1)
long_press_y = 955 + random.randint(-1, 1)
duration = random.randint(1500, 2000) # 浮动
# 构造长按命令字符串
long_press_command = f"C:\\Users\\likewendy\\Downloads\\platform-tools-latest-windows\\platform-tools\\adb.exe shell input swipe {long_press_x} {long_press_y} {long_press_x} {long_press_y} {duration}"
# 执行长按命令
os.system(long_press_command)
# 等待持续时间
time.sleep(1)
# 点击操作坐标
click_x = 543 + random.randint(-1, 1)
click_y = 1533 + random.randint(-1, 1)
# 构造点击命令字符串
click_command = f"C:\\Users\\likewendy\\Downloads\\platform-tools-latest-windows\\platform-tools\\adb.exe shell input tap {click_x} {click_y}"
# 执行点击命令
os.system(click_command)
if __name__ == '__main__':
# 初始化和加载模型(只执行一次)
print("正在加载模型...")
# 人声提取
separator = Separator('spleeter:2stems')
voiceEncoder = VoiceEncoder()
# 用于和其他音频比对的声纹样本
audio, rate = librosa.load("1_dwy_segment_00-26_to_00-52_(Vocals).mp3", sr=None)
embedding = voiceEncoder.embed_utterance(audio)
print("模型加载完成。")
try:
while True:
similar = compare_voice(separator, voiceEncoder, embedding1=embedding)
click_button(similar)
time.sleep(1.5)
except KeyboardInterrupt:
print("用户中断操作,退出程序。")
exit(0)
声明
代码只是一种我自用的demo状态,无法无人值守运行,主要是我对声纹很感兴趣,写了这么个东西。
















 2532
2532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











