






数据采样
抽样方法:简单随机抽样、分层抽样、整体抽样、系统抽样
简单随机抽样 从sashelp数据集中air数据文件中选取30个数据
Proc Surveyselect Data = sashelp.air Out=test1 Noprint Sampsize = 30; #按指定数量抽取 Run;
Proc Surveyselect Data = sashelp.air Out=test1 Noprint
Samprate = 0.3; #按比例抽取
Run;
输出文件

数据探索
数字特征的探索:均值、频数、最大值、最小值、众数、中位数、方差、标准差
数字分布的探索:是否服从正态分布
连续型变量分布
means过程
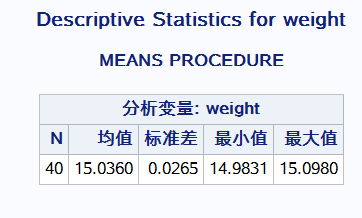
Proc means data = Data.b_rise maxdec =4; #保留小数位数 var weight; #指定分析变量 默认有均值、标准差、最大值、最小值 title'Descriptive Statistics for weight'; run;
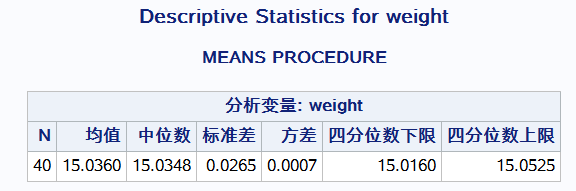
Proc means data = Data.b_rise maxdec =4 n mean median std var q1 q3; var weight; title'Descriptive Statistics for weight'; run;
univariate过程
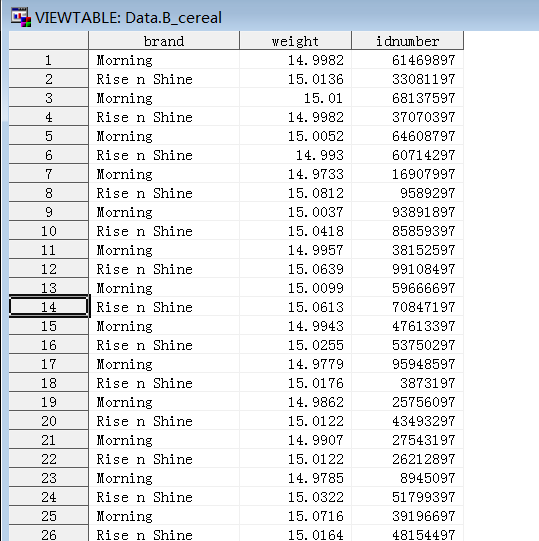
1、weight在每个brand值上的分布状况
2、wight在每个brand值上是否服从正态分布
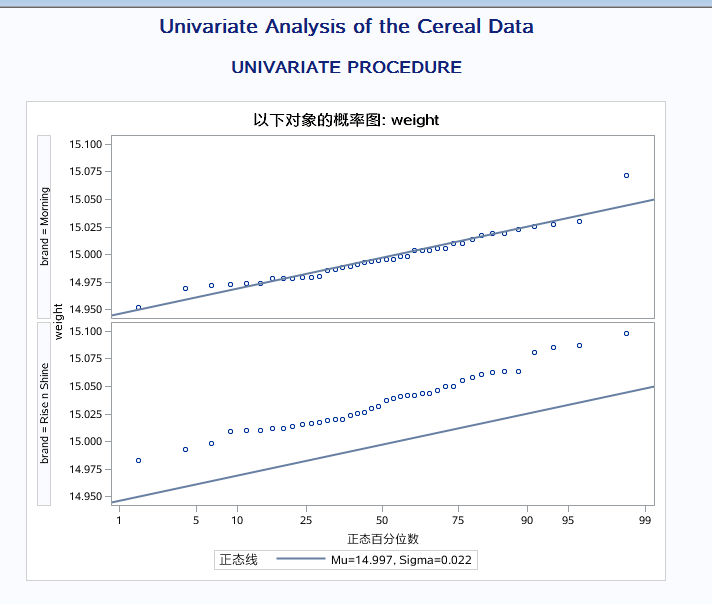
proc univariate data = Data.B_cereal; class brand; var weight; probplot weight / normal(mu = est sigma=est color=blue w=1); #pb图来检验是否服从正态分布
假设服从normal 在曲线附近 表明实际分布和理论分布相差不大 title'Univariate Analysis of the Cereal Data'; run;
图形化展示
boxplot过程
proc sort data=data.b_cereal out=b_cereal; by brand; #先将brand中分两类数据输出 run; proc boxplot data = b_cereal; plot weight*brand / cboxes = black BOXSTYLE=schematic; 输出一个盒状图 run;
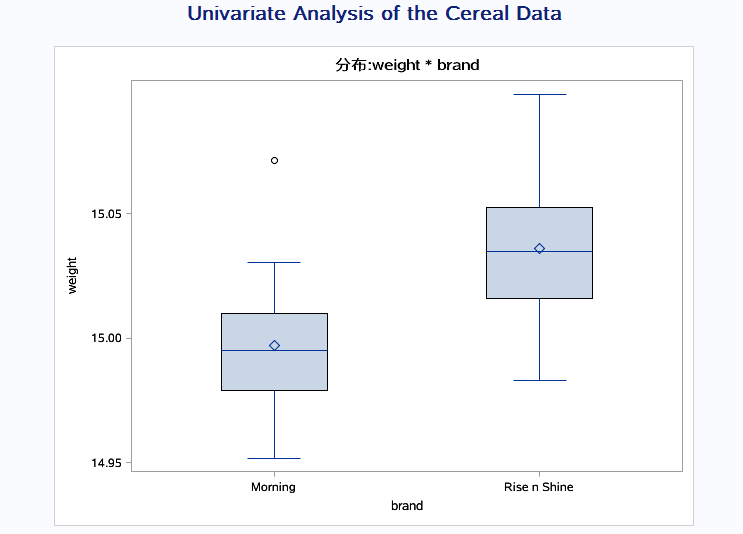
盒装图 上四分位数 下四分位数
离散型变量
计算各个类型的占比
在每个组合上占比
proc freq data = data.color; weight count; 频数变量
tables Eyes Hair Eyes*Hair / out=FreqCnt outexpect sparse; title'eye and hair color of europen children'; run;
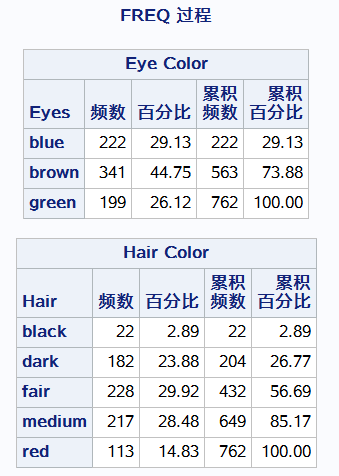
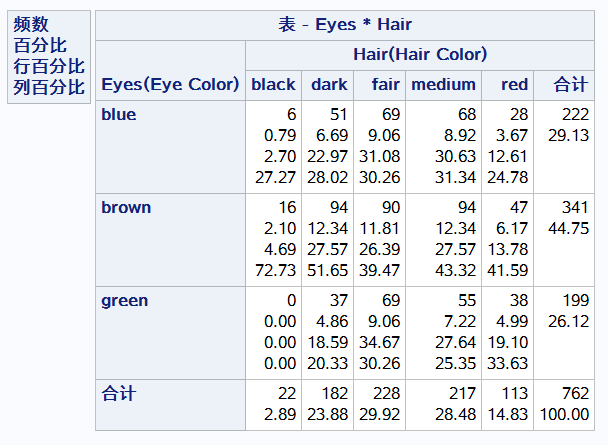
缺失值补充
单一插补和多重插补
单一插补:从其预测分布中取一个值填充缺失值
插补方法:业务逻辑;均值法;最小邻居法;回归法
单一插补往往会低估估计量的方差
多重插补是一种以模拟为基础的方法,对每个缺失值产生m个合理的插补值,这样插补后,得到m组完全数据,使用标准的完全数据方法分析每组数据并融合分析结果。二次估计
单一插补法 根据中位数来插 缺失值全部填充成中位数
proc stdize data=data.mi reponly method = median 采用什么方法 out = imputed; var acctage; run;
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









