






一、进程
IO操作(例如从端口、硬盘等读数据)不占用CPU,计算操作占用CPU,在线程中来回切换要占用资源,所以python中的多线程不适合计算操作密集型的任务,适合IO操作密集型的任务,对于计算密集型的任务,可以用多进程来解决(对于多核的CPU,对于一个进程下的线程,即使有多个核,同一时间也只有一个核对一个线程进行操作,但多个核可以同时对多个进程进行操作,可以每个核对一个进程下的线程进行操作)
import multiprocessing import threading import time def thread_run(): print(threading.get_ident()) # 获取线程的线程号 def run_process(name): time.sleep(1) print("hello %s!" %name) t = threading.Thread(target=thread_run) t.start() if __name__ == '__main__': for i in range(10): p = multiprocessing.Process(target=run_process,args=('process %s' %i,)) p.start()
每一个进程都是由一个父进程启动的
import multiprocessing import threading import time import os def info(title): print(title) print('module name: ',__name__) # 获取模块名 print('parent process: ',os.getppid()) # 获得父进程号,每个进程都是由父进程产生的 print('process id: ',os.getpid()) # 获得本身进程的进程号 def f(name): info('\033[31;1mchild process function f\033[0m') print("hello %s!" %name) if __name__ == '__main__': info('\033[32;1mmain process\033[0m') p = multiprocessing.Process(target=f,args=('test_process',)) p.start()
main process
module name: __main__
parent process: 8292
process id: 8348
child process function f
module name: __mp_main__
parent process: 8348
process id: 9108
hello test_process!
进程之间的数据是独立的,数据不能直接被访问,但可以通过下面方式进行进程之间的相互通信
import multiprocessing def f(obj_q): obj_q.put([27,'zhushanwei','educated']) if __name__ == '__main__': q = multiprocessing.Queue() # 生成一个进程的队列 p = multiprocessing.Process(target=f,args=(q,)) # 子进程的参数为父进程设置的进程队列(必须为进程队列,线程队列queue.Queue不行), # 这样子进程可以与父进程共享队列中的数据 p.start() print(q.get()) p.join()
[27, 'zhushanwei', 'educated']
import multiprocessing def f(conn): conn.send([27,'zhushanwei','educated']) # 向父进程发送数据 conn.send([25,'fj','educated']) print("from parent_conn: ",conn.recv()) # 接收父进程发来的数据 if __name__ == '__main__': parent_conn,child_conn = multiprocessing.Pipe() # 生成一个进程管道,有父进程和子进程两个链接返回值 p = multiprocessing.Process(target=f,args=(child_conn,)) # 把子进程链接作为参数传入进程中 p.start() print(parent_conn.recv()) # 父进程接收从子进程发来的数据,子进程发送多少次,父进程接收多少次 print(parent_conn.recv()) parent_conn.send("山有木兮木有枝") p.join()
[27, 'zhushanwei', 'educated']
[25, 'fj', 'educated']
from parent_conn: 山有木兮木有枝
import multiprocessing import os def f(dd,ll): dd[1] = '1' dd['2'] = 2 dd['zhu'] = 'shanwei' dd[os.getpid()] = int(os.getpid()) + 1 ll.append(1) ll.append(os.getpid()) if __name__ == '__main__': with multiprocessing.Manager() as manager: # 生成一个manager,可用于对数据的修改,等同于manager=multiprocessing.Manager() d = manager.dict() # 生成一个可以在进程之间进行操作的字典 l = manager.list(range(5)) # 生成一个可以在进程之间进行操作的列表 p_list = [] # 生成一个列表,用于放进程 for i in range(10): p = multiprocessing.Process(target=f,args=(d,l)) p.start() p_list.append(p) for j in p_list: j.join() print(d) print(l)
{'zhu': 'shanwei', 1: '1', 8548: 8549, 6568: 6569, 7836: 7837, 9072: 9073, 7344: 7345, 3048: 3049, 5128: 5129, 7224: 7225, 6808: 6809, '2': 2, 2172: 2173}
[0, 1, 2, 3, 4, 1, 6808, 1, 9072, 1, 6568, 1, 3048, 1, 7836, 1, 7344, 1, 2172, 1, 8548, 1, 7224, 1, 5128]
由于每个进程都需要独立的数据,同一进程过多则会造成资源占用量过大,所以需要进程池来限制进程的数量
import multiprocessing import os import time def foo(i): time.sleep(2) print("process: ",os.getpid()) return 'process%s' %i def bar(arg): print("--process done-- ",arg,os.getpid()) if __name__ == '__main__': print(os.getpid()) pool_test = multiprocessing.Pool(3) # 定义一个进程池,参数为允许放入进程池中的进程的最多个数 for i in range(5): # pool_test.apply(func=foo,args=(i,)) # 把进程放入进程池中,有两个方法apply和apply_async,apply是进程串行,apply_async是进程并行 pool_test.apply_async(func=foo,args=(i,),callback=bar) # callback为回调,即执行完前边的func=foo,父进程再调用执行callbake=bar, # 其中bar中的参数为foo函数中的返回值 print('end') pool_test.close() # 关闭进程池 pool_test.join() # 必须先关闭再join,并且join这行代码不能省略,如果注释则程序会直接关闭
7696
end
process: 7944
--process done-- process0 7696
process: 4180
--process done-- process1 7696
process: 8636
--process done-- process2 7696
process: 7944
--process done-- process3 7696
process: 4180
--process done-- process4 7696
协程,又称微线程,是一种用户态的轻量级线程


所以若程序遇到阻塞操作,例如IO操作,协程就切换控制
import greenlet import gevent # 手动切换协程 def test1(): print(12) gre2.switch() print(34) gre2.switch() def test2(): print(56) gre1.switch() print(78) gre1 = greenlet.greenlet(test1) # 生成一个协程 gre2 = greenlet.greenlet(test2) gre1.switch() # 切换/启动gre1这个协程 # 自动切换协程 def f1(): print("f1 running...") gevent.sleep(3) print("go on f1 running...") def f2(): print("f2 running...") gevent.sleep(2) print("go on f2 running...") def f3(): print("f3 running...") gevent.sleep(1) print("go on f3 running...") gevent.joinall([gevent.spawn(f1), # 生成协程 gevent.spawn(f2), gevent.spawn(f3)])
12
56
34
78
f1 running...
f2 running...
f3 running...
go on f3 running...
go on f2 running...
go on f1 running...
通过协程,实现多并发爬取网页
import greenlet import gevent import time from gevent import monkey from urllib import request monkey.patch_all() # 把当前所有的IO操作做上标记,这样gevent才能识别程序中的IO操作,才能串行执行 def scrip_url(url): print("GET: %s" %url) respon = request.urlopen(url) # 打开网页 data = respon.read() # 读取网页的数据 # f = open("url_data.html",'wb') # f.write(data) # 保存数据 # f.close() print("%s bytes received from %s" %(len(data),url)) # 串行执行 url_list = ['https://www.python.org/','https://www.yahoo.com/','https://github.com/'] c_time = time.time() for url_t in url_list: scrip_url(url_t) print("串行时间为:%s" %(time.time()-c_time)) # 异步执行 a_time = time.time() gevent.joinall([gevent.spawn(scrip_url,'https://www.python.org/'), gevent.spawn(scrip_url,'https://www.yahoo.com/'), gevent.spawn(scrip_url,'https://github.com/')]) print("并行时间为:%s" %(time.time()-a_time))
GET: https://www.python.org/
48725 bytes received from https://www.python.org/
GET: https://www.yahoo.com/
480761 bytes received from https://www.yahoo.com/
GET: https://github.com/
55394 bytes received from https://github.com/
串行时间为:6.311866521835327
GET: https://www.python.org/
GET: https://www.yahoo.com/
GET: https://github.com/
48725 bytes received from https://www.python.org/
55394 bytes received from https://github.com/
479781 bytes received from https://www.yahoo.com/
并行时间为:2.3351285457611084
通过协程,实现多并发的socket
import gevent from gevent import monkey import socket monkey.patch_all() # 把当前所有的IO操作做上标记,这样gevent才能识别程序中的IO操作,才能串行执行 # server服务器端 def server(port): s = socket.socket() s.bind(('0.0.0.0',port)) s.listen(50) while True: cli,addr = s.accept() gevent.spawn(handle_conn,cli) # 把handle方法和链接实例对象,传入协程 def handle_conn(conn): try: while True: data = conn.recv(1024) print("data: ",data) conn.send(data) if not data: conn.shutdown(socket.SHUT_WR) # 没有数据,关闭连接 except Exception as error: print(error) finally: conn.close() if __name__ == '__main__': server(80001) # 客户端 host,port = 'localhost',8001 ss = socket.socket(socket.AF_INET,socket.SOCK_STREAM) ss.connect((host,port)) while True: msg = input(">>: ",encoding='utf-8') ss.send(msg) data = ss.recv(1024) print("received: ",data) ss.close()
二、事件驱动和异步IO



在一个线程下,物种模式的IO操作的阻塞情况如下
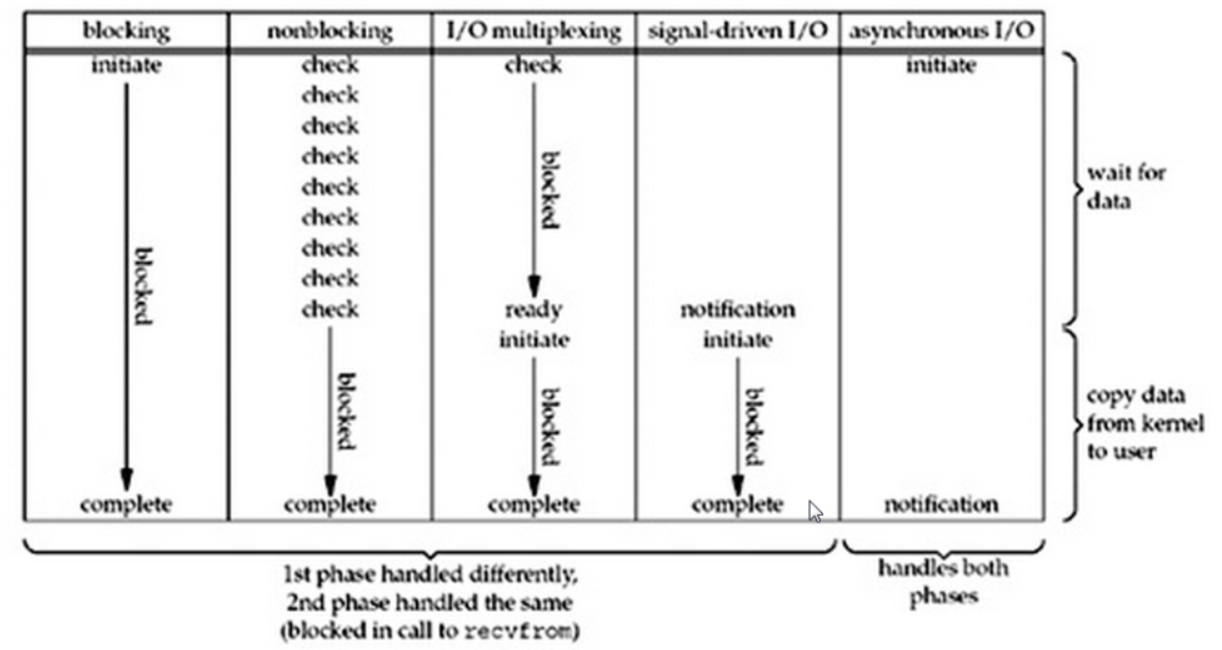
对于多路复用的IO来说,有select、poll、epoll三种方式

用多路复用的IO模拟服务器端的socket多并发,以select为例
import select import queue import socket # 服务器端 server_test = socket.socket() server_test.bind(("localhost",9999)) server_test.listen(1000) server_test.setblocking(False) # 只有设置在IO操作不阻塞,才能用IO多路复用 inputs = [server_test] # 存放要监听的链接,初始化时为server端本身的链接 outputs = [] # 存放有监听到数据返回的链接 msg_dic = {} # 字典用于存放服务器端给客户端连接发送的数据,每个键对应一个链接 while True: readable,writeable,exceptional = select.select(inputs,outputs,inputs) # 利用select来同时监听多个客户端发来的链接,第一个参数为需要监听的链接, # 第二参数为有数据返回的链接,第三个参数为监听可能有错误的链接, # 第一参数和第三参数为同一个列表,返回值为三个列表,第一个列表存放监听到的链接, # 第二个列表存放有数据返回的链接,第三个列表存放出现异常(例如断开)的链接 print(readable,writeable,exceptional) for r in readable: # 循环查看监听到的链接,查看哪个链接是活动的 if r is server_test: # 如果活动的server_test,证明客户端有新链接接入 conn,addr = r.accept() print("有一个新的链接:",addr) inputs.append(conn) # 把这个新链接放入到要监听的列表中 msg_dic[conn] = queue.Queue() # 初始化字典,每有一个客户端连接,就把链接放入字典,同时生成这个链接的一个队列, # 队列用于存放服务器端要发给这个链接的数据 else: data_test = r.recv(1024) # 如果活动的不是server_test,证明是客户端的链接,有数据传入,接收数据 print("接收数据:",data_test) # r.send(data_test) # 把数据发送给客户端 # 也可以把数据放入链接对应的队列中 msg_dic[r].put(data_test) # 把数据放入链接对应列表 outputs.append(r) # 把有数据返回的活动链接放入到outputs列表中,利用select进行监听,下一次循环放入到writeable列表中 for w in writeable: # 循环查看writeable列表,是否有要返回数据的链接 data_to_client = msg_dic[w].get() # 从链接对应的队列中取回数据 w.send(data_to_client) # 给对应的客户端连接发送数据 outputs.remove(w) # 发送完毕从outputs列表中移除这个链接,避免下一次循环时重复监听、发送数据 for e in exceptional: # 循环exceptional列表,查看是否有错误链接存在 if e in outputs: outputs.remove(e) # 如果错误链接存在于outputs列表中,则移除 inputs.remove(e) # 所有链接都在inputs列表中,直接移除,不用判断 del msg_dic[e] # 从字典中删除这个链接,及其对应的队列
import socket # 客户端 host_test = "localhost" port_test = 9999 s_test = socket.socket(socket.AF_INET,socket.SOCK_STREAM) s_test.connect((host_test,port_test)) while True: msg_test = bytes(input(">>: "),encoding='utf-8') s_test.send(msg_test) data_test = s_test.recv(1024) print(data_test)
python中有封装好的关于多路复用IO的模块selector,模块默认用epoll方法,若不支持epoll(例如,windows不支持epoll),者使用select方法
import selectors import socket
# 服务器端 def accept(sock,mask): conn,addr = sock.accept() print("conn: ",conn," addr: ",addr) conn.setblocking(False) sel.register(conn,selectors.EVENT_READ,read) # 向新连接中注册read回调函数 def read(conn,mask): data = conn.recv(1024) if data: print("data: ",data, "to: ",conn) conn.send(data) else: print("closing: ",conn) sel.unregister(conn) # 取消注册 conn.close() sel = selectors.DefaultSelector() # 设置一个select的实例对象 sock = socket.socket() sock.bind(("localhost",9999)) sock.listen(1000) sock.setblocking(False) sel.register(sock,selectors.EVENT_READ,accept) # 向对象中注册accept回调函数 while True: events = sel.select() # 默认阻塞,有活动的链接就返回后动的链接列表 for key,mask in events: callback = key.data # 相当于服务器端的accept callback(key.fileobj, mask) # key.fileobj相当于文件句柄,socket.socket()
import socket import sys # 客户端 host_test = "localhost" port_test = 9999 # socks = [socket.socket(socket.AF_INET,socket.SOCK_STREAM), # socket.socket(socket.AF_INET,socket.SOCK_STREAM), # socket.socket(socket.AF_INET,socket.SOCK_STREAM), # socket.socket(socket.AF_INET,socket.SOCK_STREAM), # socket.socket(socket.AF_INET,socket.SOCK_STREAM),] socks = [socket.socket(socket.AF_INET,socket.SOCK_STREAM) for i in range(400)] msg = [b'zhushanwei', b'is', b'handsome'] for s in socks: s.connect((host_test,port_test)) for message in msg: for s in socks: s.send(message) data = s.recv(1024) print("%s received %s" %(s.getsockname(),data)) if not data: print(sys.stderr,'close socket: ',s.getsockname())
三、RabbitMQ消息队列
线程队列只能在一个进程之内的线程之间进行通信,进程队列可以父进程和子进程、同一个父进程下的子进程之间进行通信,而RabbitMQ可以在不同进程之间进行通信,一个进程看作生产者,另一个进程看作消费者,若有多个消费者,生产者发送的数据会被消费者逐个接收,每次有一个消费者接收数据,当消费者接收到数据,调用callback函数进行数据的处理,当一个消费者处理数据中途停止时,如果参数no_ack=False,或者不写(默认为False),则会把数据自动转到下一个消费者,若消费者处理数据过程中止则进行转移到下一个,直到所有消费者都停止,生成者把数据保留到队列中,当消费者重新启动时,生产者把数据继续传给新的消费者进行处理,也可以在回调函数中加入ch.basic_ack(delivery_tag=method.delivery_tag),来手动确认数据是否处理完,对于不同的硬件配置,处理的速度不同,若对消费者进行平均的数据发送,在同一时间内有的会处理不完,所以需要按处理量和速度来对消费者发送数据,rabbitMQ是对消费者队列进行检测,若队列中还有数据没有处理,就不再发送数据
import pika # 生产者 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) # 相当于建立一个socket channel = connection.channel() # 声明一个管道,相当于开辟一条路 channel.queue_declare(queue='task_q',durable=True) # 声明一个队列,并给队列命名,参数durable=True,保证生产者端停止重启后原来的队列还在 channel.basic_publish(exchange='', routing_key='task_q', # 队列名称 body='hello world!', # 发送消息的内容 properties=pika.BasicProperties(delivery_mode=2) # 保证生成者端消息持久化,当停止重启服务时,原来发送的数据还存在,消费者还能接收处理这些数据 ) print("[x] send 'hello world!'") connection.close()
import pika import time # 消费者 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='task_q',durable=True) # 声明从哪个管道收消息 def callback(ch,method,properties,body): print(ch,method,properties) time.sleep(30) print("[x] received %s" %body) ch.basic_ack(delivery_tag=method.delivery_tag) # 手动确认数据是否处理完
channel.basic_qos(prefetch_count=1) # 队列缓存中最多有1条数据
channel.basic_consume(callback,queue='task_q',no_ack=False) # 接收消息,如果收到消息就调用callback函数来处理消息,no_ack为不确认数据是否处理完毕
print("[*] waiting for message. To exit press Ctrl+C")
channel.start_consuming() # 接收完发送的数据之后,会一直等待,下一次数据发送会再次接收
[x] send 'hello world!'
[*] waiting for message. To exit press Ctrl+C
<pika.adapters.blocking_connection.BlockingChannel object at 0x000000D9C40D2A58> <Basic.Deliver(['consumer_tag=ctag1.557dec1cdc8b4f90ac0a89193d3ab6d2', 'delivery_tag=1', 'exchange=', 'redelivered=False', 'routing_key=test_q'])> <BasicProperties>
[x] received b'hello world!'
以上是一对一的发送,即生产者发送一条数据,只有一个消费者接受,若要多个消费者接收需要用到exchange
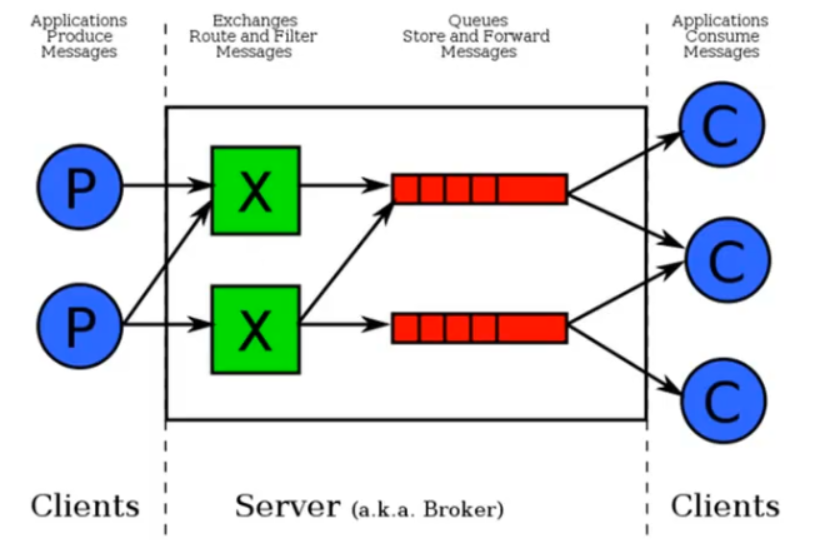



fanout类型广播模型,具有实时性,生产者发送数据,同一时间消费者若没有接收,则以后也接收不到此时生产者发送的数据,只能接收同一时刻生产者发送的数据
import pika # 生产者 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs', # 给exchange命名 type='fanout' # 定义exchange的类型 ) # 声明一个广播 msg = "hello world!" channel.basic_publish(exchange='logs', routing_key='', # 广播fanout模式不需要通道 body=msg ) print("[x] send message: %s" %msg) connection.close()
import pika # 消费者 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs', type='fanout') result = channel.queue_declare(exclusive=True) # 生成queue的对象,exclusive为唯一性,不指定queue的名称,会随机分配一个名字,exclusive=True会使使用此queue的消费者断开后,自动删除queue queue_name = result.method.queue # 用queue的对象,生成一个队列的名称 print("random queue name: ",queue_name) channel.queue_bind(exchange='logs',queue=queue_name) # 将随机生成的queue绑定到要接收数据的exchange上 print("[*] waiting for logs. To exit press Ctrl+C") def callback(ch,method,properties,body): print("[x] received %s" %body) channel.basic_consume(callback,queue=queue_name,no_ack=True) print("[*] waiting for message. To exit press Ctrl+C") channel.start_consuming() # 接收完发送的数据之后,会一直等待,下一次数据发送会再次接收
服务器端向客户端发送数据,数据流是单向的,如何把客户端执行的结果再反向对服务器端发送,变为双向流的数据传输,利用remote procedure call,RPC操作,让客户端既是生产者又是消费者
import pika # 生产者 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n): if n==0: return 0 elif n==1: return 1 else: return fib(n-1)+fib(n-2) def on_request(ch,method,props,body): n = int(body) print("[*] fib(%s)" %n) response = fib(n) ch.basic_publish(exchange='', routing_key=props.reply_to, properties=pika.BasicProperties(correlation_id=props.correlation_id), body=str(response)) ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(on_request,queue='rpc_queue') # 通过接收命令,调用回调函数on_request发送数据(发送通道为props.reply_to), # 然后通过rpc_queue接收客户端发送的数据 print("[x] waiting RPC requests") channel.start_consuming()
import pika import uuid # 消费者 class FibnacciRpcClient(object): def __init__(self): # 实例化对象先接收数据 self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True) self.callback_queue = result.method.queue self.channel.basic_consume(self.on_response, no_ack=True, queue=self.callback_queue) def on_response(self,ch,method,props,body): if self.corr_id == props.correlation_id: self.response = body def call(self,n): # 实例化对象调用这个函数来发送数据 self.response = None self.corr_id = str(uuid.uuid4()) self.channel.basic_publish(exchange='', routing_key='rpc_queue', properties=pika.BasicProperties( reply_to=self.callback_queue, correlation_id=self.corr_id ), body=str(n)) while self.response is None: self.connection.process_data_events() # 非阻塞版start_consuming() return int(self.response) fibonacci_rpc = FibnacciRpcClient() print("[x] requesting fib(30)") response = fibonacci_rpc.call(30) print("[*] got %s" %response)
direct类型广播模型
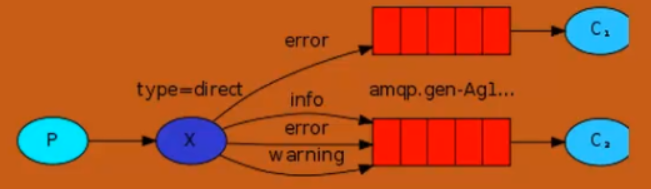
import pika import sys # 生产者 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', # 给exchange命名 type='direct' # 定义exchange的类型 ) # 声明一个广播 severity = sys.argv[1] if len(sys.argv[1])>1 else 'info' msg = ' '.join(sys.argv[2:]) or "hello world!" channel.basic_publish(exchange='direct_logs', routing_key=severity, # 广播direct模式的routing_key为自己设定的重要程度 body=msg ) print("[x] send message: %s" %msg) connection.close()
import pika import sys # 消费者 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', type='direct') result = channel.queue_declare(exclusive=True) # 生成queue的对象,exclusive为唯一性,不指定queue的名称,会随机分配一个名字,exclusive=True会使使用此queue的消费者断开后,自动删除queue queue_name = result.method.queue # 用queue的对象,生成一个队列的名称 print("random queue name: ",queue_name) severities = sys.argv[1:] if not severities: sys.stderr.write("user: %s [info] [warnning] [error] \n" %sys.argv[0]) sys.exit(1) for severity in severities: channel.queue_bind(exchange='direct_logs',queue=queue_name,routing_key=severity) # 将随机生成的queue绑定到要接收数据的exchange上 print("[*] waiting for logs. To exit press Ctrl+C") def callback(ch,method,properties,body): print("[x] received %s" %body) channel.basic_consume(callback,queue=queue_name,no_ack=True) print("[*] waiting for message. To exit press Ctrl+C") channel.start_consuming() # 接收完发送的数据之后,会一直等待,下一次数据发送会再次接收
topic类型广播

import pika import sys # 生产者 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', # 给exchange命名 type='topic' # 定义exchange的类型 ) # 声明一个广播 rout_key = sys.argv[1] if len(sys.argv[1])>1 else 'anonymous.info' msg = ' '.join(sys.argv[2:]) or "hello world!" channel.basic_publish(exchange='topic_logs', routing_key=rout_key, # 广播direct模式的routing_key为自己设定的重要程度 body=msg ) print("[x] send message: %s" %msg) connection.close()
import pika import sys # 消费者 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') result = channel.queue_declare(exclusive=True) # 生成queue的对象,exclusive为唯一性,不指定queue的名称,会随机分配一个名字,exclusive=True会使使用此queue的消费者断开后,自动删除queue queue_name = result.method.queue # 用queue的对象,生成一个队列的名称 print("random queue name: ",queue_name) bind_keys = sys.argv[1:] if not bind_keys: sys.stderr.write("user: %s [bind_key]...\n" %sys.argv[0]) sys.exit(1) for bind_key in bind_keys: channel.queue_bind(exchange='topic_logs',queue=queue_name,routing_key=bind_key) # 将随机生成的queue绑定到要接收数据的exchange上 print("[*] waiting for logs. To exit press Ctrl+C") def callback(ch,method,properties,body): print("[x] received %s" %body) channel.basic_consume(callback,queue=queue_name,no_ack=True) print("[*] waiting for message. To exit press Ctrl+C") channel.start_consuming() # 接收完发送的数据之后,会一直等待,下一次数据发送会再次接收
生产者端

消费者端1

消费者端2

四、redis

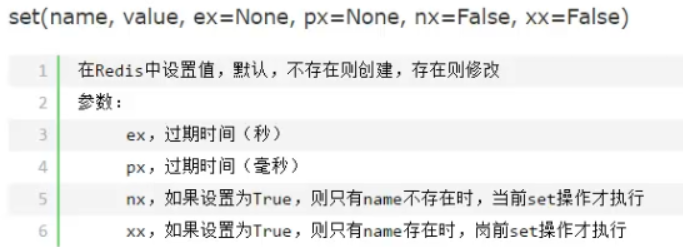
import redis ''' # redis链接 r = redis.Redis(host='localhost',port=6379) r.set('foo','bar') print(r.get('foo')) ''' # 为了避免每次建立连接、断开的开销,需要建立一个连接池 pool = redis.ConnectionPool(host='localhost',port=6379) r = redis.Redis(connection_pool=pool) r.set('foo','bar') print(r.get('foo'))
在CMD命令窗口下运行 redis-server.exe redis.conf 启动redis服务的doc窗口,不用关闭,因为服务需要一直执行,关闭服务,直接关闭窗口就行
redis对于string的操作




 就是把原来key的value替换为新的值,并返回原来的值,name要存在
就是把原来key的value替换为新的值,并返回原来的值,name要存在
 即功能为对key的value进行切片操作
即功能为对key的value进行切片操作
 即对key的value进行替换,从value的索引位置offset开始,用新的value依次替换字符,若新的value太长则向后添加
即对key的value进行替换,从value的索引位置offset开始,用新的value依次替换字符,若新的value太长则向后添加
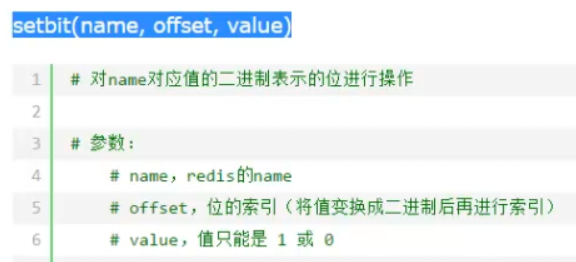 即把key的value字符按照ASCII码转为二进制依次排列,在按照位的索引改变value,然后再转为字符
即把key的value字符按照ASCII码转为二进制依次排列,在按照位的索引改变value,然后再转为字符


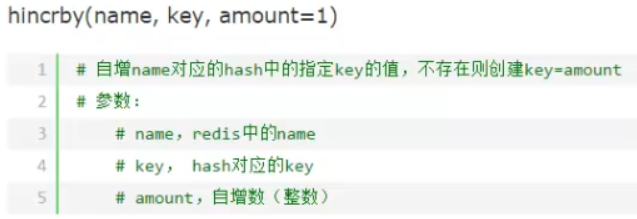
 即key不存在时,对应的value设为1,若存在则其value加1自增
即key不存在时,对应的value设为1,若存在则其value加1自增

 即在key对应的value后面追加字符串,功能相当于字符串合并
即在key对应的value后面追加字符串,功能相当于字符串合并
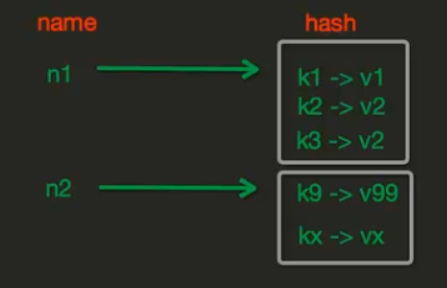
redis的hash操作,hash的内存中的存储格式如下



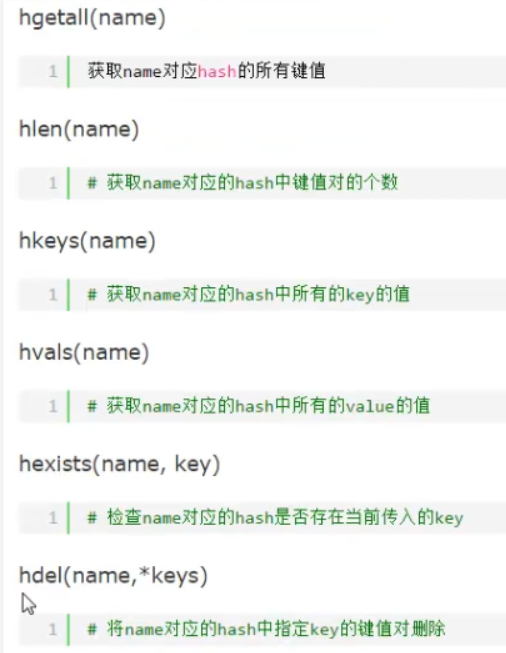
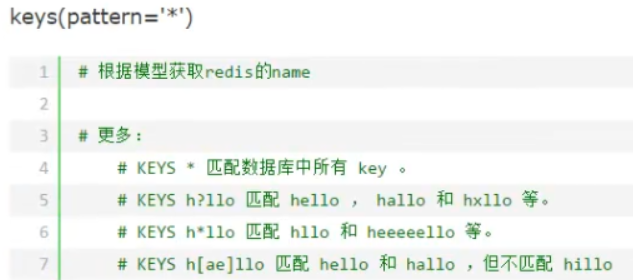
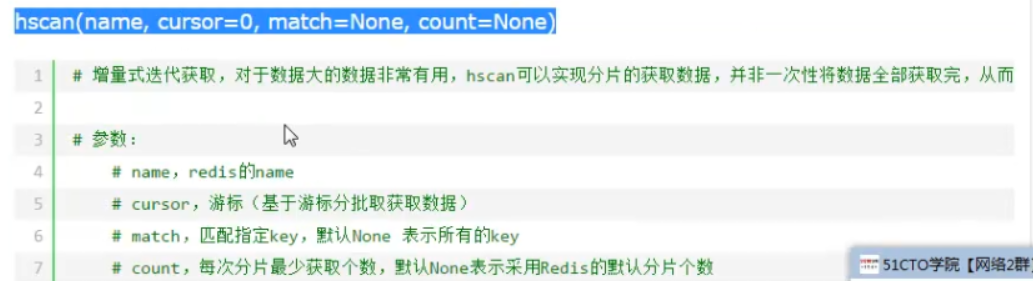 其中匹配规则可以进行模糊匹配,例如 match = *k、k*、*k*
其中匹配规则可以进行模糊匹配,例如 match = *k、k*、*k*
redis的列表的操作





 参数 num 在 value 的前面
参数 num 在 value 的前面




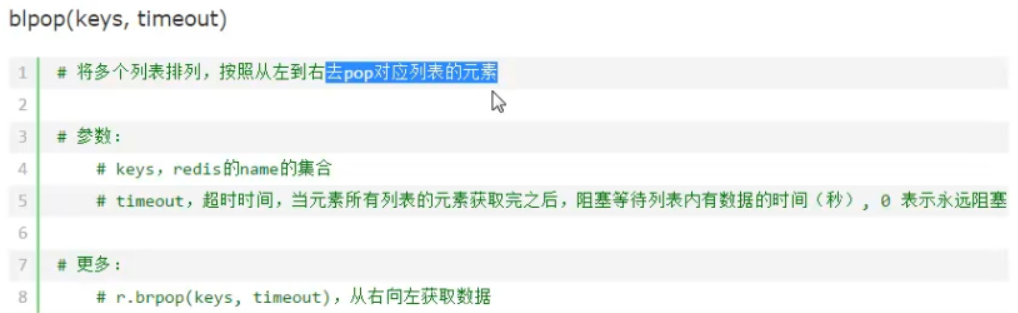

redis的集合set操作
 向name中添加元素,没有name则新建
向name中添加元素,没有name则新建

 获取集合元素之间的差集,keys为集合的名称
获取集合元素之间的差集,keys为集合的名称
 将keys之间的差集放入dest这个集合中
将keys之间的差集放入dest这个集合中
 获取集合元素的交集
获取集合元素的交集
 将keys之间的交集放入dest这个集合中
将keys之间的交集放入dest这个集合中







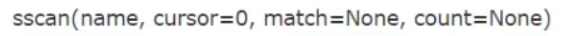 从name中找出符合条件match的值,用法类似于hscan
从name中找出符合条件match的值,用法类似于hscan




 自增 name 中元素 value 对应的分数
自增 name 中元素 value 对应的分数
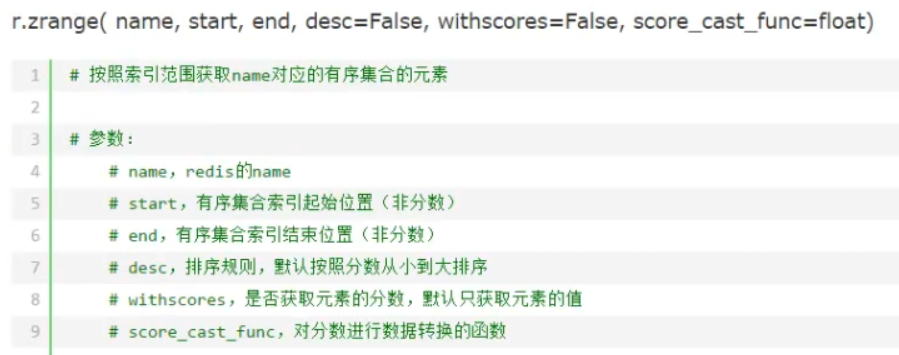




 只要有相同的value就进行aggregate操作
只要有相同的value就进行aggregate操作
 只要有相同的value就进行aggregate操作
只要有相同的value就进行aggregate操作
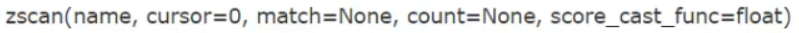 从name中找出符合条件match的值,用法类似于hscan
从name中找出符合条件match的值,用法类似于hscan
redis其他常用操作



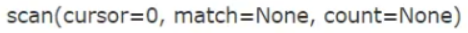

import redis import time # 为了避免每次建立连接、断开的开销,需要建立一个连接池 pool = redis.ConnectionPool(host='localhost',port=6379) r = redis.Redis(connection_pool=pool) pipe = r.pipeline(transaction=True) pipe.set('sex','man') time.sleep(10) pipe.set('name','zhushanwei') time.sleep(10) pipe.set('hobby','game') pipe.execute() # 利用管道一次执行

import redis # 发布者 class RedisHelper(object): def __init__(self): self.__connection = redis.Redis(host='localhost') self.chan_sub = 'fm104.5' # 接收频道 self.chan_pub = 'fm104.5' # 发布频道 def public(self,msg): # 发布函数 self.__connection.publish(self.chan_pub,msg) return True def subscribe(self): # 订阅函数 sub = self.__connection.pubsub() # 开始订阅,相当于打开收音机 sub.subscribe(self.chan_sub) # 调节频道 sub.parse_response() # 准备接受,再次调用parse_response()才能接收 return sub obj = RedisHelper() obj.public('hello world!')
import redis # 订阅者 class RedisHelper(object): def __init__(self): self.__connection = redis.Redis(host='localhost') self.chan_sub = 'fm104.5' # 接收频道 self.chan_pub = 'fm104.5' # 发布频道 def public(self,msg): # 发布函数 self.__connection.publish(self.chan_pub,msg) return True def subscribe(self): # 订阅函数 sub = self.__connection.pubsub() # 开始订阅,相当于打开收音机 sub.subscribe(self.chan_sub) # 调节频道 sub.parse_response() # 准备接受,再次调用parse_response()才能接收 return sub # sub包含message标识、频道、信息 obj = RedisHelper() redis_sub = obj.subscribe() # 订阅 while True: meg = redis_sub.parse_response() # 再次调用parse_response()接收 print(meg[2]) # meg为[b'message', b'fm104.5', b'hello world!']
b'hello world!'
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









