







1. 前言
我们知道排序在很多应用场景中属于一个非常核心的模块,最直接的应用就是搜索引擎。当用户提交一个query,搜索引擎会召回很多文档,然后根据文档与query以及用户的相关程度对文档进行排序,这些文档如何排序直接决定了搜索引擎的用户体验。其他重要的应用场景还有在线广告、协同过滤、多媒体检索等的排序。
LambdaMART是Learning To Rank的其中一个算法,适用于许多排序场景。它是微软Chris Burges大神的成果,最近几年非常火,屡次现身于各种机器学习大赛中,Yahoo! Learning to Rank Challenge比赛中夺冠队伍用的就是这个模型[1],据说Bing和Facebook使用的也是这个模型。
本文先简单介绍LambdaMART模型的组成部分,然后介绍与该模型相关的其他几个模型:RankNet、LambdaRank,接着重点介绍LambdaMART的原理,然后介绍LambdaMART的开源实现软件包Ranklib,最后以搜索下拉提示的个性化推荐场景说明LambdaMART的应用。
2. 符号说明
在展开介绍之前先说明本文用到的符号所代表的含义:
| 符号 | 说明 |
| q | 用户提交的查询请求 |
| d | 需要排序的文档 |
| D | 一次请求召回的待排序文档集 |
| s | 模型计算得到的文档得分 |
| (i, j) | 文档 |
| P | 所有的文档pair集合 |
| |
|
| | 文档pair下标集合,对每个 |
| |
|
| |
|
| |
|
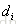 和
和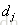 组成的有序pair
组成的有序pair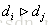
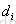 排在
排在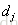 之前
之前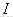
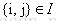 ,有
,有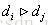
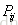
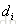 排在
排在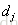 之前的预测概率
之前的预测概率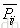
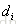 排在
排在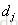 之前的真实概率,实际如果
之前的真实概率,实际如果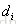 排在
排在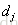 之前则为1,否则为0
之前则为1,否则为0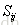
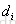 与
与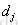 的真实序关系,取值范围{0,
的真实序关系,取值范围{0, 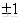 }:0表示
}:0表示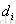 与
与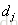 的相关性一样,谁排在前面没关系;1表示
的相关性一样,谁排在前面没关系;1表示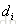 比
比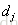 更相关,排在
更相关,排在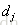 前面;-1则相反,表示
前面;-1则相反,表示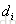 排在
排在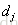 后面
后面3. LambdaMART说文解字
LambdaMART模型从名字上可以拆分成Lambda和MART两部分,表示底层训练模型用的是MART(Multiple Additive Regression Tree),如果MART看起来比较陌生,那换成GBDT(GradientBoosting Decision Tree)估计大家都很熟悉了,没错,MART就是GBDT。Lambda是MART求解过程使用的梯度,其物理含义是一个待排序的文档下一次迭代应该排序的方向(向上或者向下)和强度。将MART和Lambda组合起来就是我们要介绍的LambdaMART。
4. 神奇的Lambda
为什么LambdaMART可以很好的应用于排序场景?这主要受益于Lambda梯度的使用,前面介绍了Lambda的意义在于量化了一个待排序的文档在下一次迭代时应该调整的方向和强度。
但Lambda最初并不是诞生于LambdaMART,而是在LambdaRank模型中被提出,而LambdaRank模型又是在RankNet模型的基础上改进而来。如此可见RankNet、LambdaRank、LambdaMART三个的关系很不一般,是一个神秘的基友群,下面我们逐个分析三个基友之间的关系[2]。
5. RankNet
RankNet[3]是一个pairwise模型,它把排序问题转换成比较一个(i, j) pair的排序概率问题,即比较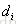
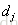
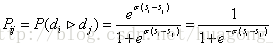
可以看到这其实就是逻辑回归的sigmoid函数[4],由于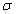
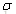
然后用交叉熵[5]作为损失函数来衡量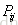
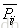
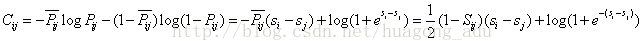
该损失函数有以下几个特点:
1) 当两个相关性不同的文档算出来的模型分数相同时,损失函数的值大于0,仍会对这对pair做惩罚,使他们的排序位置区分开
2) 损失函数是一个类线性函数,可以有效减少异常样本数据对模型的影响,因此具有鲁棒性
Ranknet最终目标是训练出一个算分函数s=f(x:w),使得所有pair的排序概率估计的损失最小:
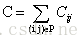
RankNet采用神经网络模型优化损失函数,采用梯度下降法[6]求解:

排序问题的评价指标一般有NDCG[7]、ERR[8]、MAP[9]、MRR[10]等,这些指标的特点是不平滑、不连续,无法求梯度,因此无法直接用梯度下降法求解。RankNet的创新点在于没有直接对这些指标进行优化,而是间接把优化目标转换为可以求梯度的基于概率的交叉熵损失函数进行求解。因此任何用梯度下降法优化目标函数的模型都可以采用该方法,RankNet采用的是神经网络模型,其他类似boosting tree等模型也可以使用该方法求解。
6. LambdaRank

图1 pairwise error
如图 1所示,每个线条表示文档,蓝色表示相关文档,灰色表示不相关文档,RankNet以pairwise error的方式计算cost,左图的cost为13,右图通过把第一个相关文档下调3个位置,第二个文档上条5个位置,将cost降为11,但是像NDCG或者ERR等评价指标只关注top k个结果的排序,在优化过程中下调前面相关文档的位置不是我们想要得到的结果。图 1右图左边黑色的箭头表示RankNet下一轮的调序方向和强度,但我们真正需要的是右边红色箭头代表的方向和强度,即更关注靠前位置的相关文档的排序位置的提升。LambdaRank[11]正是基于这个思想演化而来,其中Lambda指的就是红色箭头,代表下一次迭代优化的方向和强度,也就是梯度。
受LambdaNet的启发,LambdaRank对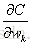
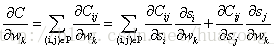
其中
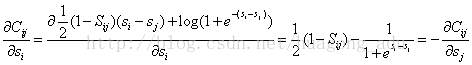
代入上式得
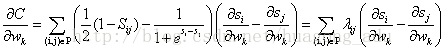
其中令
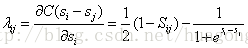
对于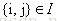
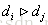
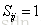
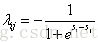
因此,对每个文档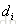
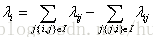
同时LambdaRank还在Lambda中引入评价指标Z (如NDCG、ERR等),把交换两个文档的位置引起的评价指标的变化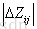
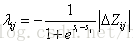
可以看出,LambdaRank不是通过显示定义损失函数再求梯度的方式对排序问题进行求解,而是分析排序问题需要的梯度的物理意义,直接定义梯度,可以反向推导出LambdaRank的损失函数为:
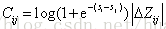
LambdaRank相比RankNet的优势在于分解因式后训练速度变快,同时考虑了评价指标,直接对问题求解,效果更明显。
7. LambdaMART
LambdaRank重新定义了梯度,赋予了梯度新的物理意义,因此,所有可以使用梯度下降法求解的模型都可以使用这个梯度,MART就是其中一种,将梯度Lambda和MART结合就是大名鼎鼎的LambdaMART[12]。
MART[13][14]的原理是直接在函数空间对函数进行求解,模型结果由许多棵树组成,每棵树的拟合目标是损失函数的梯度,在LambdaMART中就是Lambda。LambdaMART的具体算法过程如下:

可以看出LambdaMART的框架其实就是MART,主要的创新在于中间计算的梯度使用的是Lambda,是pairwise的。MART需要设置的参数包括:树的数量M、叶子节点数L和学习率v,这3个参数可以通过验证集调节获取最优参数。
MART支持“热启动”,即可以在已经训练好的模型基础上继续训练,在刚开始的时候通过初始化加载进来即可。下面简单介绍LambdaMART每一步的工作:
1) 每棵树的训练会先遍历所有的训练数据(label不同的文档pair),计算每个pair互换位置导致的指标变化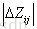
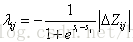
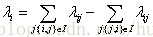
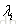
2) 创建回归树拟合第一步生成的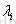
3) 对第二步生成的回归树,计算每个叶子节点的数值,采用Newton step求解,即对落入该叶子节点的文档集,用公式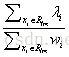
4) 更新模型,将当前学习到的回归树加入到已有的模型中,用学习率v(也叫shrinkage系数)做regularization。
LambdaMART具有很多优势:
1) 适用于排序场景:不是传统的通过分类或者回归的方法求解排序问题,而是直接求解
2) 损失函数可导:通过损失函数的转换,将类似于NDCG这种无法求导的IR评价指标转换成可以求导的函数,并且富有了梯度的实际物理意义,数学解释非常漂亮
3) 增量学习:由于每次训练可以在已有的模型上继续训练,因此适合于增量学习
4) 组合特征:因为采用树模型,因此可以学到不同特征组合情况
5) 特征选择:因为是基于MART模型,因此也具有MART的优势,可以学到每个特征的重要性,可以做特征选择
6) 适用于正负样本比例失衡的数据:因为模型的训练对象具有不同label的文档pair,而不是预测每个文档的label,因此对正负样本比例失衡不敏感
8. Ranklib开源工具包
Ranklib[15]是一个开源的Learning ToRank工具包,里面实现了很多Learning To Rank算法模型,其中包括LambdaMART,其源码的算法实现流程大致如下:

该工具包定义的数据格式如下:
label qid:$id $feaid:$feavalue $feaid:$feavalue … #description
每行代表一个样本,相同查询请求的样本的qid相同,label表示该样本和该查询请求的相关程度,description描述该样本属于哪个待排序文档,用于区分不同的文档。
该工具包是用Java实现的,在空间使用上感觉有些低效,但整体设计还是挺好的,Ranker的接口设计的很好,值得学习借鉴。
另外还有很多其他的LambdaMART的开源实现,有兴趣的可以参考[16][17][18]
9. LambdaMART应用
最后我们以一个实际场景来介绍LambdaMART的应用。现在很多搜索引擎都有一个下拉提示的功能,学术上叫QAC(Query Auto-Completion,query自动补全),主要作用是在用户在搜索引擎输入框输入query的过程中输出一系列跟用户输入query前缀相匹配的query,供用户选择,减少用户的输入,让用户更加便捷的搜索。
Milad Shokouhi[19]发现有一些query的热度有明显的用户群倾向,例如,当不同用户输入i时,年轻的女性用户倾向于搜instagram,而男性用户则倾向于搜imdb,所以可以对query的下拉提示做个性化排序。
Milad Shokouhi使用LambdaMART模型作为个性化排序模型,使用了用户的长期历史、短期历史、性别、年龄、所处地域、提示query的原始排序位置等特征,最终效果提升了9%,效果非常明显。
Milad Shokouhi的工作说明LambdaMART可以应用于个性化排序,且效果非常不错。
10. 总结
本文在一些相关书籍、paper和开源代码的基础上,简单梳理了LambdaMART的来龙去脉,简单总结:Lambda在RankNet出炉,在LambdaRank升华,在LambdaMART发扬光大,青出于蓝而胜于蓝,模型的数学推导和实际效果都非常漂亮,只要涉及到排序的场景都可以适用,是排序场景的“万金油”。
参考文献:
[1] Learning to Rank Using an Ensemble ofLambda-Gradient Models
[2] From RankNet to LambdaRank to LambdaMART: AnOverview
[3] Learning to Rank using Gradient Descent
[4] Wikipedia-Sigmoid Function
[6] Wikipedia-Gradient Descent
[7] Wikipedia-NDCG
[8] Expected Reciprocal Rank for Graded Relevance
[9] Wikipedia-MAP
[10] Wikipedia-MRR
[11] Learning to Rank with Nonsmooth CostFunctions
[12] Adapting boosting for information retrievalmeasures
[13] Greedy function approximation: A gradientboosting machine
[14] The Elements of Statistical Learning
[15] RankLib
[16] jforests
[17] xgboost
[18] gbm
[19] Learning to Personalize QueryAuto-Completion
转载请注明出处,本文转自:http://blog.csdn.NET/huagong_adu/article/details/40710305















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









