







1、算法介绍
1.1 LambdaMart的历史演变
Lambdamart是一种用于排序的机器学习算法。像这种在排序问题中用到的机器学习算法,被统称为 Learning to Rank (LTR) 算法,或者 Machine-Learning Rank (MLR) 算法。
LTR 算法通常有三种手段,分别是:Pointwise、Pairwise 和 Listwise。Pointwise 和 Pairwise 类型的 LTR 算法,将排序问题转化为回归、分类或者有序分类问题。Listwise 类型的 LTR 算法则另辟蹊径,将用户查询(Query)所得的结果作为整体,作为训练用的实例(Instance)。
LambdaMART 是一种 Listwise 类型的 LTR 算法,它基于 LambdaRank 算法和 MART (Multiple Additive Regression Tree) 算法,将搜索引擎结果排序问题转化为回归决策树问题。MART 实际就是梯度提升决策树(GBDT, Gradient Boosting Decision Tree)算法。GBDT 的核心思想是在不断的迭代中,新一轮迭代产生的回归决策树模型拟合损失函数的梯度,最终将所有的回归决策树叠加得到最终的模型。LambdaMART 使用一个特殊的 Lambda 值来代替上述梯度,也就是将 LambdaRank 算法与 MART 算法加和起来。
小结:lambdamart算法就是LambdaRank+Mart。其中Mart就是GBDT,网上有非常多的详细介绍,这里就不多费笔墨了。我们着重看一下LambdaRank,而LambdaRank又是由RankNet发展而来。
1.1.2 RankNet
Ranking 常见的评价指标都无法求梯度,因此没法直接对评价指标做梯度下降。
RankNet 的创新之处在于,它将不适宜用梯度下降求解的 Ranking 问题,转化为对概率的交叉熵损失函数的优化问题,从而适用梯度下降方法。
RankNet不去直接去学习每个文档的相关性, 而是去比较两个文档的相关性, 其将相关性规定如下:
P ( u 1 > u 2 ) = 1 ; P ( u 1 = = u 2 ) = 0.5 ; P ( u 1 < u 2 ) = 0 P(u1 > u2) = 1; P(u1 == u2) = 0.5; P (u1<u2) =0 P(u1>u2)=1;P(u1==u2)=0.5;P(u1<u2)=0
所以 1, 0 , -1 就是学习的label。 即不同文档比较下的相对相关性。
具体的相似度衡量公式为:
P
i
j
≡
P
(
U
i
⊳
U
j
)
≡
1
1
+
e
−
σ
(
s
i
−
s
j
)
P_{ij}≡P(Ui⊳Uj)≡\frac{1}{1+e^{−σ(si−sj)}}
Pij≡P(Ui⊳Uj)≡1+e−σ(si−sj)1
其中
s
i
s_i
si,
s
j
s_j
sj是文档
x
i
x_i
xi,
x
j
x_j
xj的评分,通过一个带参数的评分函数得到,这个评分函数其实就是Ranknet最终要求解出的目标。
使用交叉熵作为损失函数:
L
=
(
1
−
S
i
j
)
σ
(
s
i
−
s
j
)
+
l
o
g
(
1
+
e
−
σ
(
s
i
−
s
j
)
)
L = (1−S_{ij})σ(s_i−s_j)+log(1+e^{−σ(s_i−s_j)})
L=(1−Sij)σ(si−sj)+log(1+e−σ(si−sj))
然后使用梯度下降进行求解,但是这里有一个问题,那就是RankNet的优化方向为降低pair-wise error,并不关心最相关的doc是否排在最前面。
以下图为例,这里每条横线代表一条文档,其中蓝色的表示相关的文档,灰色的则表示不相关的文档。RankNet优化过程如图中黑线所示:

看上去逆序对是下降的:13 → 11。但在实际中我们可能更需要将相关性最高的样本尽可能排在最前面,即图中红线所示的更新方向。
于是就有了LambdaRank。
1.1.3 LambdaRank
在讲lambdaRank之前,先看一下RankNet的梯度:
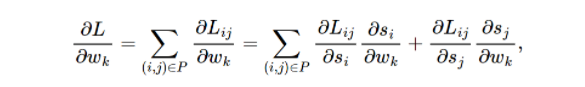
其有如下的对称性:

定义
λ
i
j
\lambda_{ij}
λij

可以把
λ
i
j
\lambda_{ij}
λij看成是Ui和Uj中间的作用力,如果Ui⊳Uj,则Uj会给予Ui向上的大小为|
λ
i
j
\lambda_{ij}
λij|的推动力,而对应地Ui会给予Uj向下的大小为|
λ
i
j
\lambda_{ij}
λij|的推动力。
如何将NDCG等类似更关注排名靠前的搜索结果的评价指标加入到排序结果之间的推动力中去呢?实验表明,直接用|ΔNDCG|乘以原来的λij就可以得到很好的效果,也即:
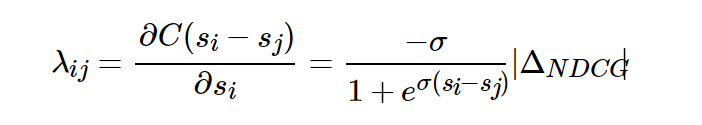
其中|ΔNDCG|是交换排序结果Ui和Uj得到的NDCG差值。NDCG倾向于将排名高并且相关性高的文档更快地向上推动,而排名地而且相关性较低的文档较慢地向上推动。
另外还可以将|ΔNDCG|替换成其他的评价指标。
1.2 LambdaMart原理
前面说过lambdaMart = LambdaRank + MART。
其中,MART是一个算法框架,还需要一个梯度。而LambdaRank正好定义了一个可以将NDCG等指标进行优化的梯度。
组合后的lambdaMart伪代码如下所示:

2、源码解析
参考:
https://www.jianshu.com/p/a23f33b58633















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









