






前言:
学习python3爬虫有一段时间了,熟悉了爬虫的一些基本原理和基本库的使用,本次就准备利用requests库和正则表达式来抓取猫眼电影排行TOP100的相关内容。
1、本次目标:
爬取猫眼电影排行TOP100的电影相关信息,包括:名称、图片、演员、时间、评分,排名。提取站点的URL为http://maoyan.com/board/4,提取的结果以文本形式保存下来。
2、准备工作
只需要安装好requests库即可。
安装方式有很多种,这里只简单的介绍一下通过pip这个包管理工具来安装。
在命令行界面中输入pip3 install requests即可完成安装。(无论是windows、linux、还是mac,都可以使用该方式)
完成之后可以导入requests模块进行测试:
>python Python 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:04:45) [MSC v.1900 32 bit (Intel)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import requests >>>
如果没有错误提示,就证明已经成功安装了。
3、抓取分析
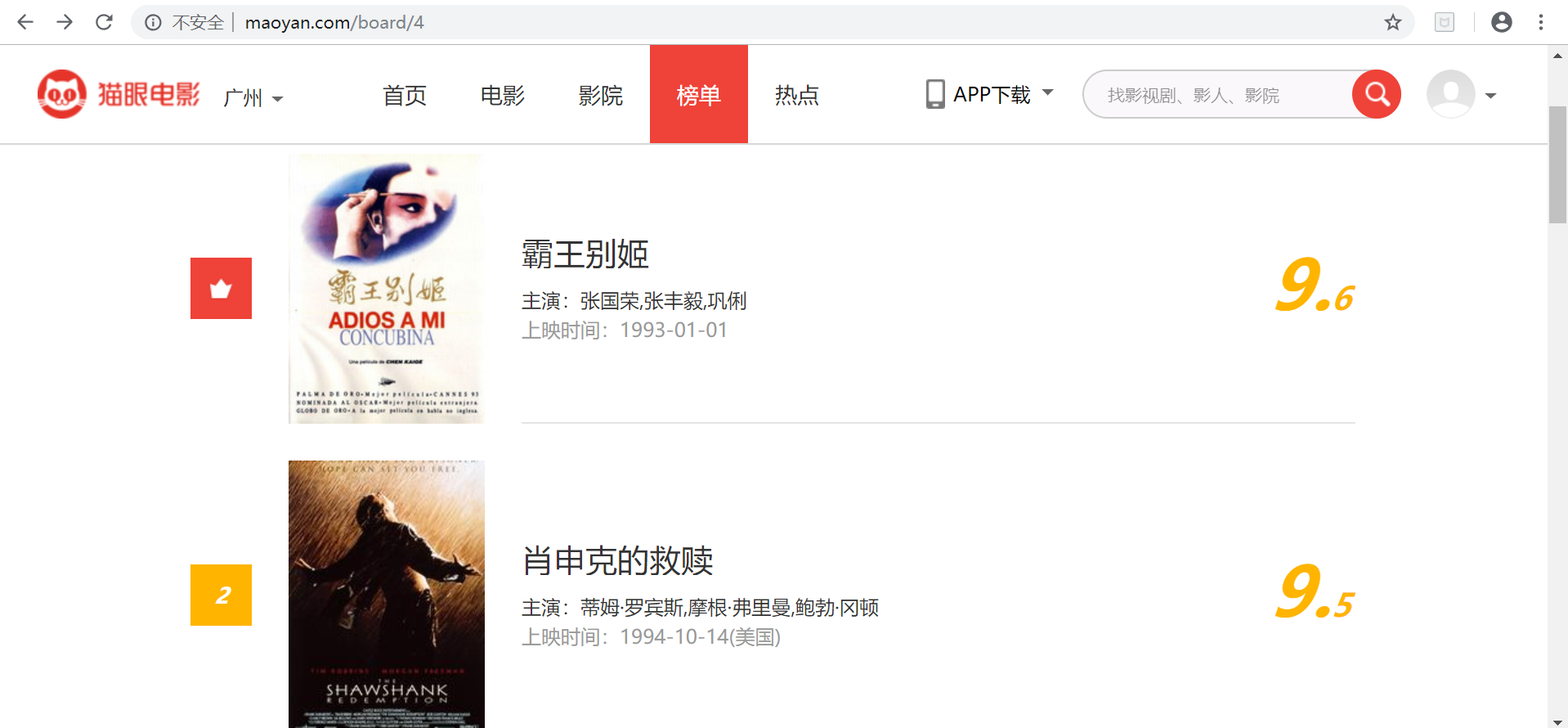
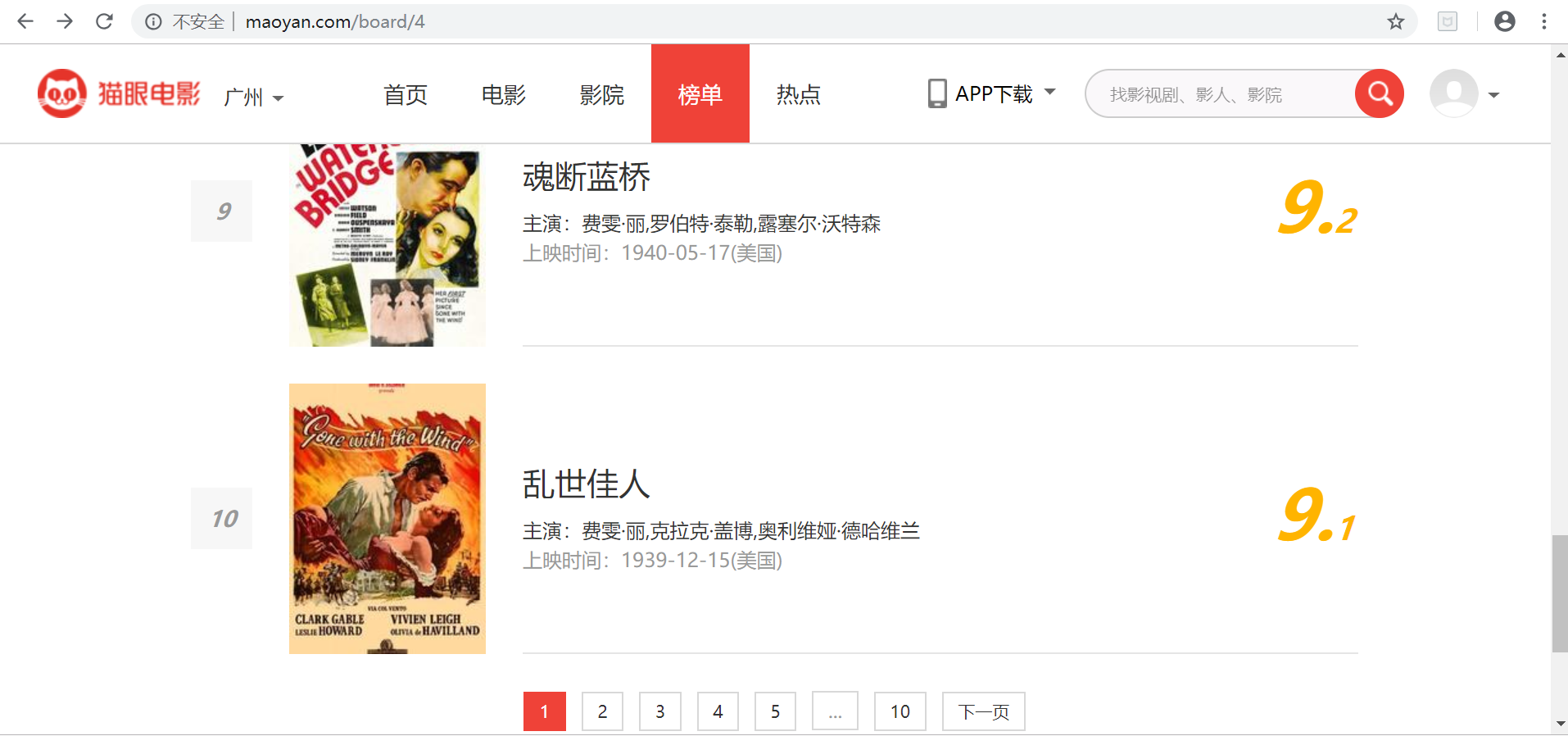
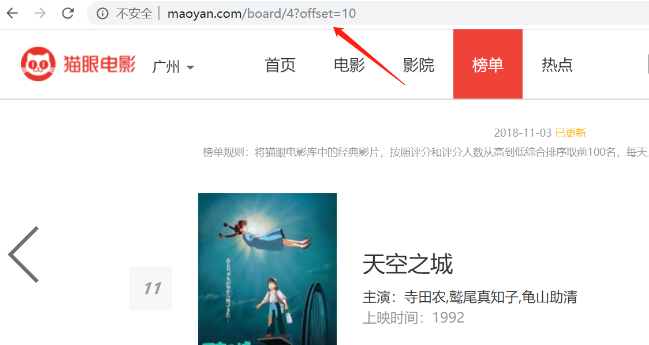
首先进入目标站点http://maoyan.com/board/4,如下图,可以看到有电影的排名、演员、时间、评分等信息,翻到页面底部,如下图,可以发现,每个页面有10部电影,点击下一页可看到站点的URL变为了http://maoyan.com/board/4?offset=10,如下图,里面是排名11-20的电影。也就是说要获取TOP100的电影信息,只需要请求offset=0,10,20...90的页面,然后再利用正则表达式爬取每一页所需要的电影信息即可。
4、抓取页面
这里构建一个get_one_page()函数,用来抓取每一个单独页面的内容,初步代码实现如下:
1 import requests 2 3 4 def get_one_page(): 5 url = 'http://maoyan.com/board/4' 6 headers = { 7 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' 8 '(KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' 9 } 10 response = requests.get(url=url, headers=headers) 11 print(response.text) 12 13 14 get_one_page()
代码运行之后,就获取到了页面的源代码,接下来就运用正则表达式提取出所需要的信息。
5、正则提取
回到网页,按F12在开发者模式下的NETWORK监听组件中查看到源代码,如下图。


在源代码中可以看到电影的相关信息,这里用红色箭头从上至下分别标记出了电影的排名、图片、电影名、演员、上映时间以及评分所在的位置。接下来只需要为每一部分的信息写出对应的正则表达式即可获取到相应的信息。
先以电影排名为例,可以看到每一个电影部分的所有信息都包含在<dd>..</dd>节点中,而电影排名的信息是在class为board-index的i节点中,所以这里利用非贪婪的匹配原则提取该节点内的信息,正则表达式可写为:<dd>.*?"board-index.*?>(.*?)</i>
接下来获取电影图片。可以看到电影图片的信息在img data-src的a节点中,正则表达式可写为:<dd>.*?data-src="(.*?)".*?</a>
同样,电影名称的信息在name为标志位title=""的a节点中,正则表达式可写为:<dd>.*?class="name".*?title="(.*?)".*?</a>
按照以上方法,最后可以得到完整的正则表达式为:<dd>.*?board-index.*?>(\d+?)</i>.*?data-src="(.*?)".*?</a>.*?class="name".*?title="(.*?)".*?</a>.*?class="star".+?(.*?)</p>.*?class="releasetime".+?(.*?)</p>.*?class="integer".+?(.*?)</i>.*?"fraction".+?(.*?)</i>.*?</dd>
接下来只需要构建一个解析页面的函数parse_one_page(),用来得到所需要的电影信息,代码实现如下:
1 def parse_one_page(html): 2 pattern = re.compile( 3 r'<dd>.*?board-index.*?>(\d+?)</i>' 4 r'.*?data-src="(.*?)".*?</a>' 5 r'.*?class="name".*?title="(.*?)".*?</a>' 6 r'.*?class="star".+?(.*?)</p>' 7 r'.*?class="releasetime".+?(.*?)</p>' 8 r'.*?class="integer".+?(.*?)</i>' 9 r'.*?"fraction".+?(.*?)</i>.*?</dd>', re.S 10 ) 11 re_lists = re.findall(pattern, html) 12 for re_list in re_lists: 13 yield { 14 'index': re_list[0], 15 'image': re_list[1], 16 'title': re_list[2], 17 'actor': re_list[3].strip()[3:], 18 'time': re_list[4].strip()[5:], 19 'score': re_list[5] + re_list[6] 20 }
# 这里用compile()方法,将正则字符串构建成正则对象,以便复用。其中re.S,表示(.)这个通配符能够匹配到包括换行符在内的所有字符。yield迭代返回一个包含电影全部信息的字典。关于yield的知识链接:http://www.runoob.com/w3cnote/python-yield-used-analysis.html
代码输出结果如下:
{"index": "1", "image": "http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c", "title": "霸王别姬", "actor": "张国荣,张丰毅,巩俐", "time": "1993-01-01", "score": "9.6"}
{"index": "2", "image": "http://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@160w_220h_1e_1c", "title": "肖申克的救赎", "actor": "蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿", "time": "1994-10-14(美国)", "score": "9.5"}
{"index": "3", "image": "http://p0.meituan.net/movie/54617769d96807e4d81804284ffe2a27239007.jpg@160w_220h_1e_1c", "title": "罗马假日", "actor": "格利高里·派克,奥黛丽·赫本,埃迪·艾伯特", "time": "1953-09-02(美国)", "score": "9.1"}
{"index": "4", "image": "http://p0.meituan.net/movie/e55ec5d18ccc83ba7db68caae54f165f95924.jpg@160w_220h_1e_1c", "title": "这个杀手不太冷", "actor": "让·雷诺,加里·奥德曼,娜塔莉·波特曼", "time": "1994-09-14(法国)", "score": "9.5"}
{"index": "5", "image": "http://p1.meituan.net/movie/f5a924f362f050881f2b8f82e852747c118515.jpg@160w_220h_1e_1c", "title": "教父", "actor": "马龙·白兰度,阿尔·帕西诺,詹姆斯·肯恩", "time": "1972-03-24(美国)", "score": "9.3"}
{"index": "6", "image": "http://p1.meituan.net/movie/0699ac97c82cf01638aa5023562d6134351277.jpg@160w_220h_1e_1c", "title": "泰坦尼克号", "actor": "莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩", "time": "1998-04-03", "score": "9.5"}
{"index": "7", "image": "http://p0.meituan.net/movie/da64660f82b98cdc1b8a3804e69609e041108.jpg@160w_220h_1e_1c", "title": "唐伯虎点秋香", "actor": "周星驰,巩俐,郑佩佩", "time": "1993-07-01(中国香港)", "score": "9.2"}
{"index": "8", "image": "http://p0.meituan.net/movie/b076ce63e9860ecf1ee9839badee5228329384.jpg@160w_220h_1e_1c", "title": "千与千寻", "actor": "柊瑠美,入野自由,夏木真理", "time": "2001-07-20(日本)", "score": "9.3"}
{"index": "9", "image": "http://p0.meituan.net/movie/46c29a8b8d8424bdda7715e6fd779c66235684.jpg@160w_220h_1e_1c", "title": "魂断蓝桥", "actor": "费雯·丽,罗伯特·泰勒,露塞尔·沃特森", "time": "1940-05-17(美国)", "score": "9.2"}
{"index": "10", "image": "http://p0.meituan.net/movie/230e71d398e0c54730d58dc4bb6e4cca51662.jpg@160w_220h_1e_1c", "title": "乱世佳人", "actor": "费雯·丽,克拉克·盖博,奥利维娅·德哈维兰", "time": "1939-12-15(美国)", "score": "9.1"}
这样就成功得将猫眼TOP1-10的电影抓取下来了,接下来只需要获取剩余页面,用同样的方式即可。
6、页面获取
根据上面的分析可知,只需要分别请求URL为http://maoyan.com/board/4?offset=0,10,20...90的页面。所以这里构建一个url_list()函数,设置一个offset参数来标记页面。代码实现如下:
1 def url_list(offset): 2 if offset == 0: 3 page_url = 'http://maoyan.com/board/4' 4 return page_url 5 6 else: 7 page_url = 'http://maoyan.com/board/4' + '?offset=' + str(offset) 8 return page_url
7、保存数据
对于抓取到的数据,这里构建一个write()函数,直接将数据写入文本文件中。通过JSON库里的dumps()方法实现字典的序列化,并指定ensure_ascii参数为False,这样可以保证输出结果是中文形式而不是Unicode编码。代码实现如下:
1 def write(final_result): 2 with open('猫眼电影top100.txt', 'a', encoding='utf-8') as file: 3 file.write(json.dumps(final_result, ensure_ascii=False) + '\n')
8、整合代码
构建一个主函数main(),整合所有函数功能,完成抓取。
在主函数中,首先定义一个包含0、10、20...90的offset_list列表,遍历列表中的每一个offset值得到每一个页面URL的值;然后传给get_one_page()函数来得到每一个页面;再将得到页面的响应体传给parse_one_page()解析出电影信息;最后把解析出的电影信息写入文本文件中保存。代码实现如下:
1 def main(): 2 offset_list = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90] 3 for offset in offset_list: 4 url = url_list(offset) 5 html = get_one_page(url) 6 result = parse_one_page(html) 7 for i in range(10): 8 final_result = next(result) 9 print(final_result) 10 write(final_result)
9、完整代码
到此为止,猫眼电影TOP100的爬虫就全部完成了,最后稍微整理完善,附上完整代码如下:
1 import requests 2 import re 3 import json 4 import time 5 from requests.exceptions import RequestException 6 7 8 # 抓取单个页面 9 def get_one_page(url): 10 try: 11 headers = { 12 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' 13 '(KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' 14 } 15 response = requests.get(url=url, headers=headers) 16 if response.status_code == 200: 17 return response.text 18 return None 19 except RequestException: 20 return None 21 22 23 # 解析单个页面 24 def parse_one_page(html): 25 # 正则表达式 26 pattern = re.compile( 27 r'<dd>.*?board-index.*?>(\d+?)</i>' 28 r'.*?data-src="(.*?)".*?</a>' 29 r'.*?class="name".*?title="(.*?)".*?</a>' 30 r'.*?class="star".+?(.*?)</p>' 31 r'.*?class="releasetime".+?(.*?)</p>' 32 r'.*?class="integer".+?(.*?)</i>' 33 r'.*?"fraction".+?(.*?)</i>.*?</dd>', re.S 34 ) 35 re_lists = re.findall(pattern, html) 36 for re_list in re_lists: 37 yield { 38 'index': re_list[0], 39 'image': re_list[1], 40 'title': re_list[2], 41 'actor': re_list[3].strip()[3:], 42 'time': re_list[4].strip()[5:], 43 'score': re_list[5] + re_list[6] 44 } 45 46 47 # 获取所有URL 48 def url_list(offset): 49 if offset == 0: 50 page_url = 'http://maoyan.com/board/4' 51 return page_url 52 53 else: 54 page_url = 'http://maoyan.com/board/4' + '?offset=' + str(offset) 55 return page_url 56 57 58 # 保存数据 59 def write(final_result): 60 with open('猫眼电影top100.txt', 'a', encoding='utf-8') as file: 61 file.write(json.dumps(final_result, ensure_ascii=False) + '\n') 62 63 64 # 主函数 65 def main(): 66 offset_list = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90] 67 for offset in offset_list: 68 url = url_list(offset) 69 html = get_one_page(url) 70 result = parse_one_page(html) 71 for i in range(10): 72 final_result = next(result) 73 print(final_result) 74 write(final_result) 75 76 77 if __name__ == '__main__': 78 main() 79 time.sleep(1) # 延时等待
10、运行结果
最后运行代码,得到结果如下:
{'index': '1', 'image': 'http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', 'title': '霸王别姬', 'actor': '张国荣,张丰毅,巩俐', 'time': '1993-01-01', 'score': '9.6'}
{'index': '2', 'image': 'http://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@160w_220h_1e_1c', 'title': '肖申克的救赎', 'actor': '蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿', 'time': '1994-10-14(美国)', 'score': '9.5'}
{'index': '3', 'image': 'http://p0.meituan.net/movie/54617769d96807e4d81804284ffe2a27239007.jpg@160w_220h_1e_1c', 'title': '罗马假日', 'actor': '格利高里·派克,奥黛丽·赫本,埃迪·艾伯特', 'time': '1953-09-02(美国)', 'score': '9.1'}
{'index': '4', 'image': 'http://p0.meituan.net/movie/e55ec5d18ccc83ba7db68caae54f165f95924.jpg@160w_220h_1e_1c', 'title': '这个杀手不太冷', 'actor': '让·雷诺,加里·奥德曼,娜塔莉·波特曼', 'time': '1994-09-14(法国)', 'score': '9.5'}
{'index': '5', 'image': 'http://p1.meituan.net/movie/f5a924f362f050881f2b8f82e852747c118515.jpg@160w_220h_1e_1c', 'title': '教父', 'actor': '马龙·白兰度,阿尔·帕西诺,詹姆斯·肯恩', 'time': '1972-03-24(美国)', 'score': '9.3'}
{'index': '6', 'image': 'http://p1.meituan.net/movie/0699ac97c82cf01638aa5023562d6134351277.jpg@160w_220h_1e_1c', 'title': '泰坦尼克号', 'actor': '莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩', 'time': '1998-04-03', 'score': '9.5'}
...
{'index': '96', 'image': 'http://p1.meituan.net/movie/36a893c53a13f9bb934071b86ae3b5c492427.jpg@160w_220h_1e_1c', 'title': '爱·回家', 'actor': '俞承豪,金艺芬,童孝熙', 'time': '2002-04-05(韩国)', 'score': '9.0'}
{'index': '97', 'image': 'http://p1.meituan.net/movie/9bff56ed3ea38bb1825daa1d354bc92352781.jpg@160w_220h_1e_1c', 'title': '黄金三镖客', 'actor': '克林特·伊斯特伍德,李·范·克里夫,埃里·瓦拉赫', 'time': '1966-12-23(意大利)', 'score': '8.9'}
{'index': '98', 'image': 'http://p1.meituan.net/movie/ed50b58bf636d207c56989872a91f4cf305138.jpg@160w_220h_1e_1c', 'title': '我爱你', 'actor': '宋在浩,李顺才,尹秀晶', 'time': '2011-02-17(韩国)', 'score': '9.0'}
{'index': '99', 'image': 'http://p1.meituan.net/movie/a1634f4e49c8517ae0a3e4adcac6b0dc43994.jpg@160w_220h_1e_1c', 'title': '迁徙的鸟', 'actor': '雅克·贝汉,Philippe Labro', 'time': '2001-12-12(法国)', 'score': '9.1'}
{'index': '100', 'image': 'http://p0.meituan.net/movie/3e5f5f3aa4b7e5576521e26c2c7c894d253975.jpg@160w_220h_1e_1c', 'title': '英雄本色', 'actor': '狄龙,张国荣,周润发', 'time': '2017-11-17', 'score': '9.2'}
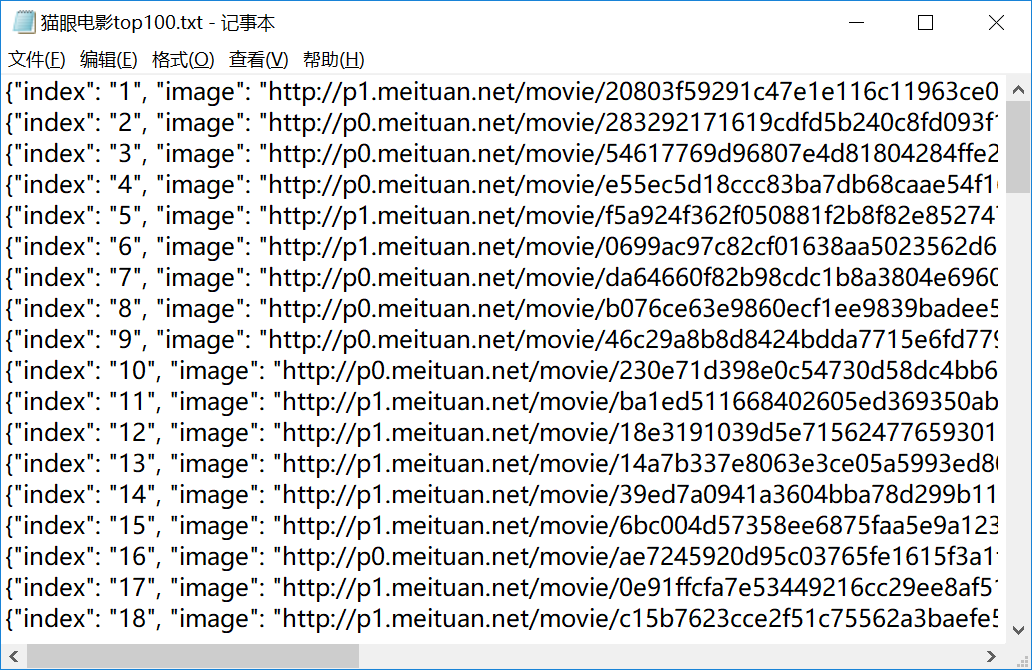
可以看到,电影信息已经全部成功爬取下来,并且保存到了文本文件中。抓取猫眼电影排行TOP100,大功告成!
结语:
学习爬虫的时间不长,写篇博客也算是对知识的温习和对自己成长的记录,有不足之处希望能谅解并且指出。














 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









