







- 当读压力很大的时候,可以考虑添加Slave机器的方式解决(读写分离、一主多备)
- 当Slave机器达到一定的数量、写压力很大时;就得考虑分表分库了。
分区
- 将表的数据均衡分摊到不同的硬盘,系统或是不同服务器存储介子(重点突破硬盘瓶颈)中,实际上还是一张表。分区表
- 水平分区:通过某个属性列来分割。eg:一个包含十年发票记录的表可以被分区为十个不同的分区,每个分区包含的是其中一年的记录
- 单张表的查询很慢。数据量很大。数据分段。对数据的操作往往只涉及一部分数据
分表
- 就是把一张表按一定的规则分解成N个具有独立存储空间的实体表。较少表的宽度或者是数据量。
- 水平分表
- 垂直分表
- 使用场景:
- 单表数据量很大、字段很多
- 当频繁插入或者联合查询时,速度变慢
- 提高单表并发速度,提高io效率、提高写效率,读写锁影响的数据量变小,插入数据库需要重新建立索引的数据减少
分区和分表
- 分区只是一张表中的数据的存储位置发生改变,是逻辑层面进行了水平分割,对于应用程序来说,它仍是一张表。
- 分表后,单表的并发能力提高了,磁盘I/O性能也提高了。
- 当访问量大,且表数据比较大时,两种方式可以互相配合使用。
- 分表重点是存取数据时,如何提高mysql并发 能力上;而分区呢,则是如何突破磁盘的读写能力,
分区分表策略
- Range(范围)
- Hash(哈希)
- 按照时间拆分
- Hash之后按照分表个数取模
- 在认证库中保存数据库配置,就是建立一个DB,这个DB单独保存user_id到DB的映射关系
分库
- 当一个库中的表过多。单台机器容量不够
- 访问量太大,单个实例无法支持
- 一般分库的步骤如下:
垂直分库
- 将系统中不存关联关系或不同业务的数据放在不同库中
- 垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈
- 问题:跨数据库的事务、join查询等问题。
水平分库
- 一般是在垂直拆分后进行
- 将存储的同张表的数据划分到不同的库中(压力分摊到不同的库中)。eg:订单、用户
- 问题:数据路由
读写分离
- 对于时效性不高的数据,可以通过读写分离缓解数据库压力
- 问题:数据同步
分库后的问题
-
分布式事务:
- 加入一个bff成协调多个操作,串行执行,一旦失败就回滚之前的操作
- 将远程分布式事务拆分成一系列的本地事务。步骤:本地修改-》通知其他服务-》其他服务收到消息-》修改
- 通知环节可能出现失败:交给消息中间件解决
- 通知消息重复:消费者端维护一个列表保存已经处理过的消息,本地事务控制来更新这个“消费状态表”
-
跨库join
- 先看能否对库结构调整
- 在每个库中存储一份全局表,表中的数据不经常修改,用于join查询
- 增加冗余字段反范式,避免join。需要注意数据一致性问题
- 使用跨库数据同步,在同一个库中join,但是这样对性能有一定的影响
- 使用rpc rest方式,在业务层获取数据避免join
https://blog.csdn.net/dinglang_2009/article/details/53195835
-
排序、分页、分组:
- 在单库情况下可以冗余一个所有数据的汇总表,用于排序分页,但是当数据量大后将成为瓶颈
- 如果排序使用的字段为分表的字段,则可以直接在相关的表中查询
- 如果排序使用的字段不是分表字段,则需要在每个表中查询出topn,然后在程序汇总找出topn。对于内存消耗很大
https://blog.csdn.net/weixin_38052017/article/details/73740167
-
可以选用第三方的数据库中间件(Atlas,Mycat,TDDL,DRDS)
数据库架构演进
- 单库单表
- 单库多表:当需要添加一列的时候,mysql会锁表,期间所有的读写操作只能等待
- 多库多表:单库存储io上遇到瓶颈
单表问题
- 单个表数据量越大,读写锁,插入操作重新建立索引效率越低。
- 单个数据库服务器压力过大
- 读写速度遇到瓶颈
数据分片
- 确定数据在多台存储设备上分布的技术:数据分布均匀,访问负载均衡,扩缩容数据迁移少
- 将数据集划分成相互独立、正交的数据子集,然后将数据子集分布到不同的节点上
分片方式
- 使用Key或Key的哈希值来计算Key的分布
- 划分号段:缺点是数据可能分布不均匀、数据热度不同导致各个设备的负载不均衡,扩容也不够灵活,只能成倍地增加设备
- 取模:Hash(Key)%N就可以确定数据所在的设备编号。缺点:扩容的时候,会产生大量的数据迁移
- 检索表:在检索表中存储Key和设备的映射关系。缺点:需要存储检索表的空间可能比较大
- 一致性哈希的算法: 简单而巧妙,很容易做到数据均分布,其单调性也保证了扩缩容的数据迁移是比较少的。
虚拟服务器
- 一个VServer是一个逻辑上的存储服务器,是分布式存储系统的一个存储单元,一台物理设备上可以部署多个VServer,一个VServer支持一个写进程和多个读进程
- 提高单机性能,只有一个写进程,不需要锁。存储资源(内存、硬盘)划分为多个存储单元,这样就支持多个写进程同时工作。
- 扩展能力较好,可以根据实体机的性能决定部署vserver的数量
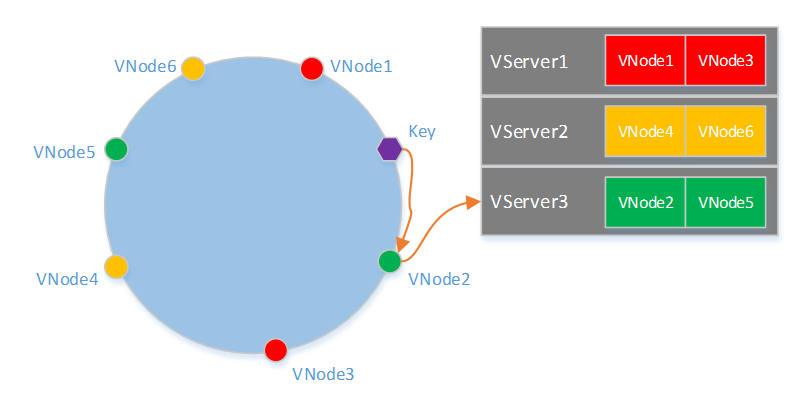
一致性哈希算法
- 在一个hash环上
- 将vserver映射到多个vnode,每个vnode负责hash环上的一段hash值
- 将存储的key映射到hash环上,看该位置由哪个vnode进行负责
https://images2015.cnblogs.com/blog/37882/201607/37882-20160708154631014-1597691155.png
数据库分区、分表、分库、分片:https://blog.csdn.net/qq_28289405/article/details/80576614
分区和分片的区别:https://blog.csdn.net/iie_libi/article/details/75086663
CAP定律
- “CAP定律”中的“一致性”、“可用性”和“分区容错性”三者是不可能的
- 在互联网领域的绝大多数的场景,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}