







1、人工智能的概念
人工智能概念,在1956年召开的达特茅斯会议上正式被提出。该会议是由信息学鼻祖克劳德.艾尔伍德.香农(ClaudeElwoodShannon)以及马文.明斯基(Marvin Minsky)、约翰.麦卡锡(JohnMcCarthy)等十位信息学、数学、计算机学的科学先驱,在美国东部的达特茅斯召开的一次具有传奇色彩的学术会议。会上首次出现了“人工智能”(ArtificialIntelligence,Al)这个术语,也是在这次会议上,他们决定,将像人类那样思考的机器称为“人工智能”。
提到“人工智能”不得不提的另一个名字,则是享有“人工智能之父”称号的计算机科学家艾伦.图灵(Alan Turing),他在其论文《Computing Machinery and Intelligence》中提出了著名的“图灵测试”,定义了判定机器是否具有“智能”的方法。
2、从统计理论到大模型,人工智能发展的飞跃
达特茅斯会议以后,截至今日人工智能历经了67年的发展,纵观其历史,大致可分为:统计理论、机器学习、深度学习和大模型四个发展阶段。从大模型阶段开始,其对人类意图的准确理解以及内容生成能力,则标志着人工智能从判别式时代,开始走向生成式时代。
3、从Word2Vec到Transformer,NLP技术浅析
在展开讨论GPT大模型之前,我们把时间稍微往前回溯一下,通过一些案例简要回顾一下Word2Vec、Seq2Seq等早期NLP技术,以及大模型的奠基技术:Transformer结构。
1)Word2Vec:
Word2Vec(Word to Vector)即:词-向量转换,是由托马斯.米科洛夫(Tomas Mikolov)等科学家于2013年在论文《Efficient Estimation of Word Representations in Vector Space》中提出的。
Word2Vec是NLP的重要思想,它提出了一种将自然语言的词语转化为“可计算”的向量的方法,这个过程通常称为“嵌入”(embedding)。
我们来看一个例子,下图将“King”、“Man”和“Women”三个词进行了Word2Vec操作,并对它们的向
量矩阵用颜色进行了可视化,其中每个色块代表一个特征(feature),特征向量用颜色表示:深红色为+2,白色为0,深蓝色为-2。从图中所显示的特征模式我们可以看到,“man”和“woman”两个词的向量矩阵在向量空间中的距离更近(这两个词的语义上相似度更高),而与“king”的距离更远(语义上差异更大)

Word2Vec的表示方法能够将词映射到一个高维的表示语义的空间中,即:词向量空间,使得计算机可以对自然语言进行“理解”和计算。
2)Seq2Seq:
Seq2Seq (Sequence to Sequence),即:“序列到序列”,是伊尔亚.苏茨克维(Ilya Sutskever)等科学家在NIPs 2014发表的论文《Sequence to Sequence Learning with NeuralNetworks》中被首次提出。该论文的一作--一伊尔亚.苏茨克维即现任OpenAI首席科学家,时任GoogleBrain研究科学家。该论文在谷歌学术引用目前已经超过2.1万次,可见其在NLP领域的重要性,在其发表至今近9年的时间里,NLP的发展可以说或多或少受到了该论文思想的影响。
Seq2Seq的思想其实很直观,就是把语言生成任务建模为序列到序列的任务。何为序列?句子就是一个文本序列,模型的输入是一个序列,输出也是一个序列。其提出的初衷,主要是用于翻译任务,后来广泛应用到对话生成、摘要生成等文本生成任务当中。
这种结构的显著特点就是:通过编码器-解码器结构,维系着输入序列和输出序列的一个松散的映射关系,松散主要指,输入输出序列的长度是可变的,且无需严格对应。
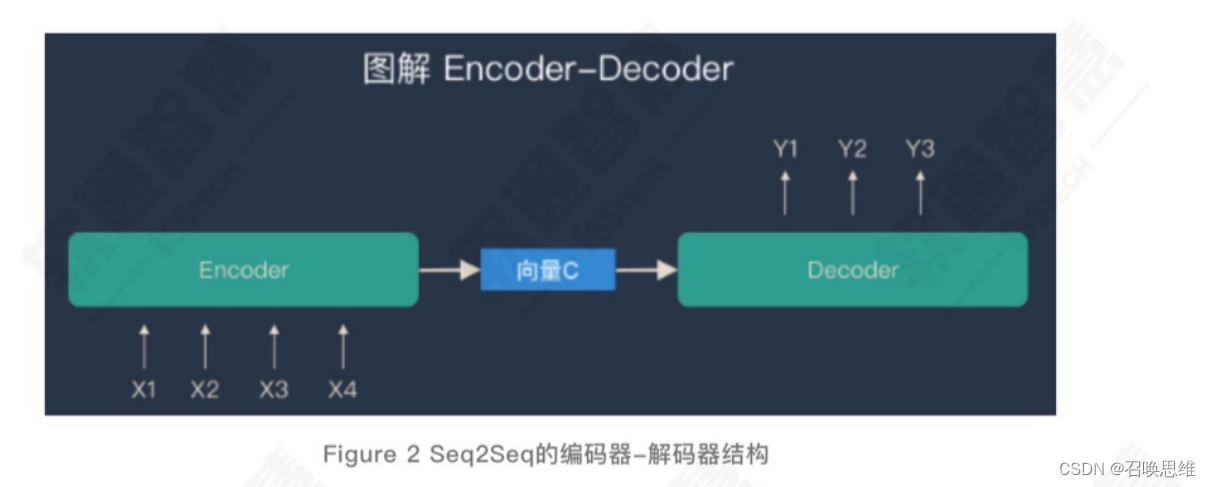
在实现Seq2Seq时,根据应用场景和任务不同,我们可以构建不同的编码器和解码器,这也就意味着序列之间的映射方法不同,如:从一种语言映射到另一种语言,是翻译任务;从一个问题映射到一个答案,是问答系统等等。而编码器和解码器的具体实现,可以是NLP的经典结构循环神经网络(RecurrentNeuralNetwork,RNN),也可以是其改良版本长短期记忆网络(Long Short-Term Memory,LSTM),亦或是“注意力”(Attention)机制。
3)Tranformer:
来到这里,一切开始变得熟悉起来:Transformer结构的本质,其实就是Seq2Seq的编码器-解码器模型加上“注意力”机制,该机制和Transformer结构,是谷歌公司翻译团队在2017发表的论文“AttentionIsAllYou Need”中首次提出。而何为“注意力”?简单地说,注意力能够在句子内部计算字词之间的相关性&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









