







 本文详细介绍了Hadoop的起源、核心组件及其架构。内容涵盖Hadoop的GFS、MapReduce和HDFS架构,强调了其高吞吐、分布式存储管理的特点,并详细阐述了HDFS的读写过程。此外,还提及了Hadoop生态系统中的HBase、Hive、Pig等组件,以及NameNode HA、HDFS Federation和YARN等新特性。
本文详细介绍了Hadoop的起源、核心组件及其架构。内容涵盖Hadoop的GFS、MapReduce和HDFS架构,强调了其高吞吐、分布式存储管理的特点,并详细阐述了HDFS的读写过程。此外,还提及了Hadoop生态系统中的HBase、Hive、Pig等组件,以及NameNode HA、HDFS Federation和YARN等新特性。
1.Hadoop来源
hadoop来源于Google核心技术。
分布式基础设施 :GFS、Chubby和Protocol Buffer
分布式大规模数据处理:MapReduce、Sawzall
分布式数据库:BigTable和Sharding BitTable对应HBase
1.1GFS的架构
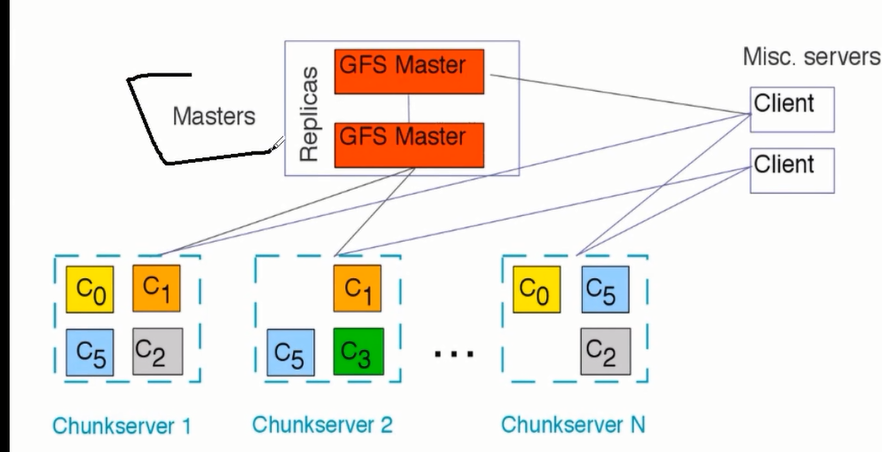
Master 存储数据块信息 双重Master不存在单点问题
Chunkserver存放数据分片信息,会和Master通信确认是否可访问
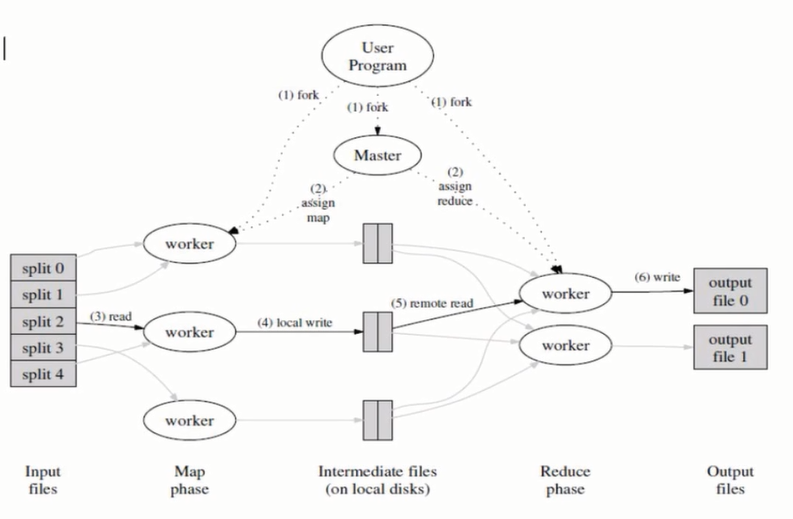
1.2 MapReduce架构
MapReduce是把一个大的任务分成多个小的任务
UserProgram进程分出一个Master进程管理Mapwork和Reducework。master进程负载
2 Hadoop的特点
开源可用、分布式备份复制机制和MapReduce任务监控
3.Hadoop体系结构
hadoop core (HDFS组件、MapReduce组件、Common组件)
3.1 Common组件
基础,提供IO、压缩、RPC通信、序列化
JNI方法调用c/C++编写的native库,加速数据压缩、校验等功能
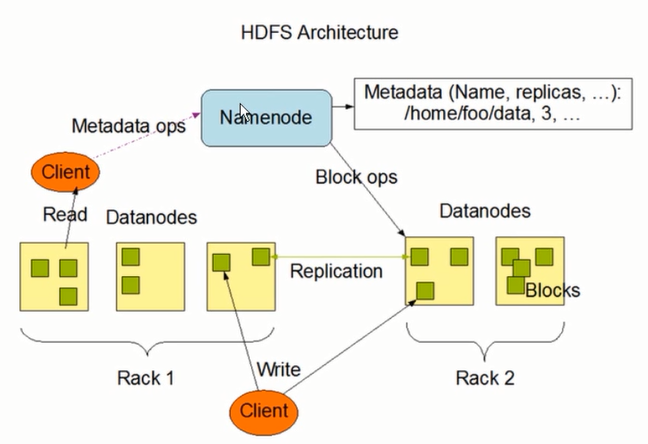
3.2HDFS组件
采用流式数据访问模式,可用来存储超大文件和海量数据,具有高吞吐、方便部署、分布式存储管理的特点
HDFS集群拥有名称节点namenode和数据节点datanode,名称节点保存文件数据块的映射映像信息和整个文件系统的名称空间,而数据节点负责存储和读取 数据文件
HDFS读操作
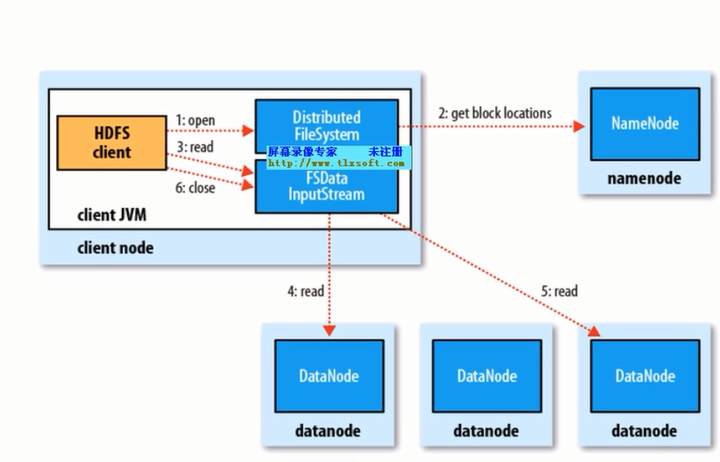
步骤:1HDFS client 通过Distributed FileSystem 的open方法
Distributed 调用rpc来确定文件块位置信息
Distributed FileSystem返回一个FSData inputStream给客户端
客户端通过read函数从数据节点读取数据
存取这数据头文件信息读取最近的数据节点数据信息
HDFS读操作
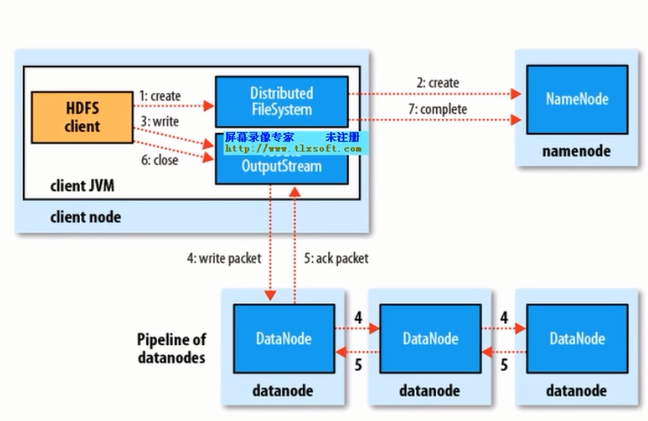
步骤:创建Distributed FIleSystem,向namenode发起请求,生成FsData OutputStream对象,一旦获得
FSData OutputStream对象,client端就回向datanode写数据,datanode将返回一个包写完信息给client端
同时刚被写入datanode将会向其他datanode副本发起写过程。piperline过程向其他副本写过程
3.3MapReduce组件
JobTracker taskTracker MapTask Reduce Task
word count 统计单词次数
input:how do you do
fine
you should say how do you do
map
map负责将每个单词变为key 1
reduce负责将每个key相同的相加
MapReduce流程图
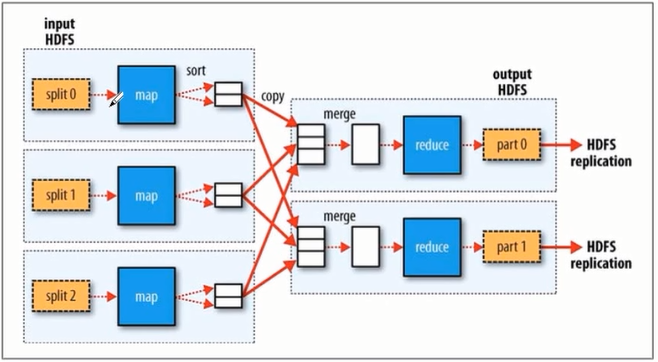

将分片sort 然后copy shuffle 、
partition分区 先map放到内存然后分区,然后merge 作为reduce输入然后远程copy然后merge缓存本地然后输出结果
Hadoop生态系统

HBase列式存储动态模式数据库,随机读写访问可以通过mapreduce处理数据,
hive是数据仓库,数据抽取、转换和加载。类SQL语言HiveQL
Pig 对大型数据分析平台
Oozie工作流引擎,计算作业抽象为动作,控制流节点则用于控制动作之间的关系。
Hcatalog抽象表
zookeeper分布式服务框架,解决分布式计算中的一致性问题,
处理数据管理问题:统一命名服务、状态同步管理,集群管理,分布式应用配置项管理等
Ambari支持监控管理工具
Hadoop版本:新版2.x加入NameNode HA和HDFS Federation和YARN
Hadoop参考:http://hadoop.apache.org/
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









