







Kubernetes&&容器编排调度&&K3s
前言
官网
RKE: Rancher Kubernetes Engine
容器奇谈:探秘 K3s 前世今生,轻舟启航的轻量级 Kubernetes
K3s vs K8s:轻量级和全功能的对决
轻量级 Kubernetes 集群发行版 K3s 完全进阶指南
K3s的优点。
单一二进制文件,内置组件可插拔
K3s 是一个单一的二进制文件,易于安装和配置。该二进制文件的大小在 50 到 100MB 之间(取决于版本),K3s 解压后包含在控制平面和工作节点上运行 Kubernetes 所需的所有组件。这包括作为 CRI 的 containerd,作为 CNI 的 Flannel,作为数据存储的 SQLite,以及用于安装关键资源(如 CoreDNS 和 Traefik Proxy 作为入口控制器)的 manifest。它包含一个负载均衡器,将 Kubernetes 服务连接到主机 IP,使其适用于单节点集群。
控制平面节点在不到 512MB 的 RAM 中运行所有 Kubernetes 组件,而工作节点在不到 50MB 的 RAM 中运行其组件。
K3s 是资源受限环境的优先选择。
单一进程的简单性
与在不同进程中运行组件的传统 Kubernetes 不同,K3s 在单个 Server 或 Agent 进程中运行控制平面、kubelet 和 kube-proxy,并由 containerd 处理容器生命周期功能。
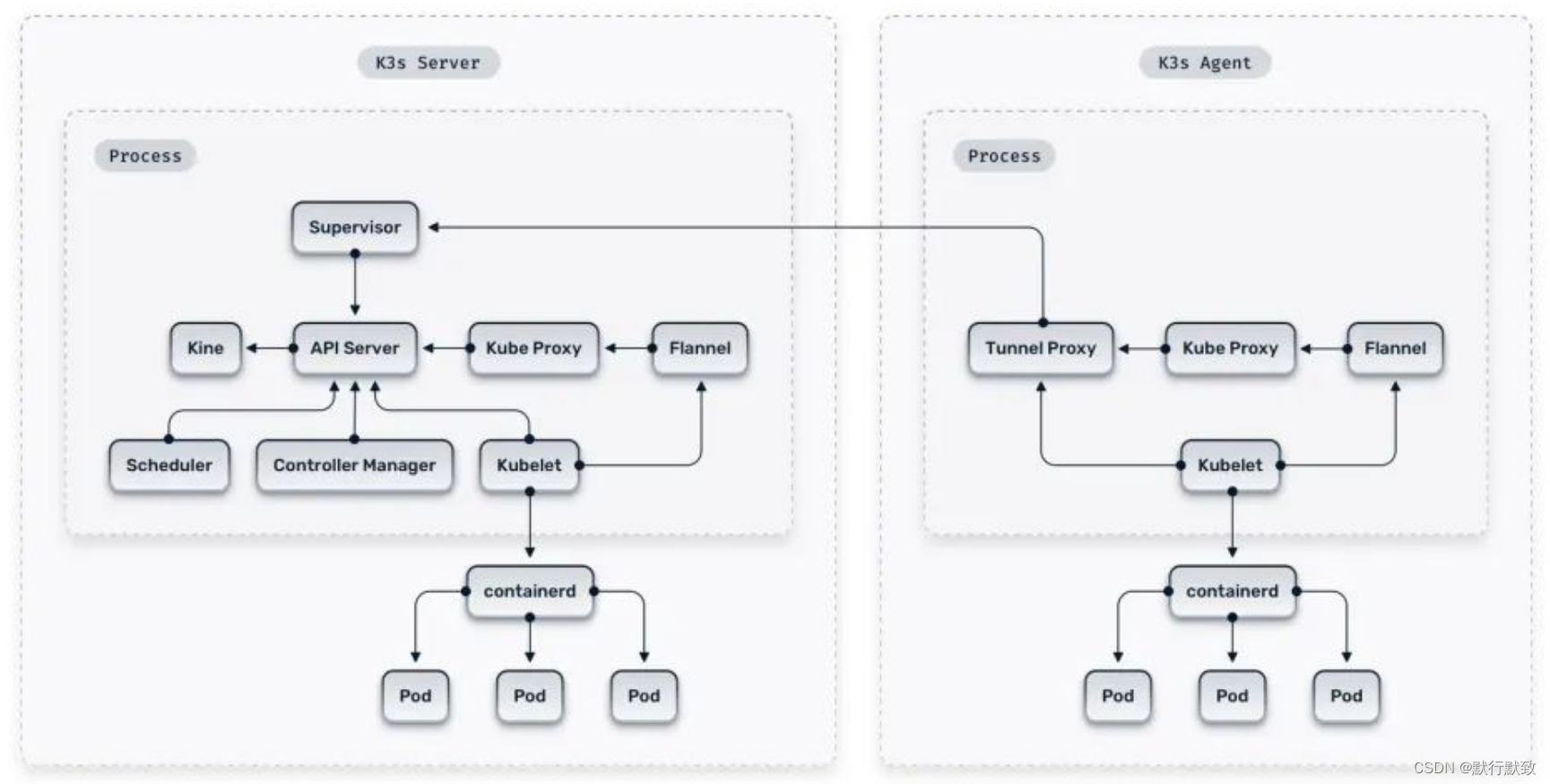
灵活性
K3s 在安装时通过命令行参数或环境变量进行配置。同一二进制文件可以成为控制平面节点,也可以作为工作节点加入现有集群。对于资源充足的环境,它可以将 SQLite 替换为嵌入式 etcd 集群,或者可以使用外部 etcd 集群或类似 MySQL、MariaDB 或 Postgres 的 RDBMS 解决方案。
K3s 将运行时与工作负载分离,因此可以在停止和启动 K3s 进程时,而不会影响正在运行的容器。这使得通过替换二进制文件并重新启动进程来轻松升级 K3s,或通过更改启动文件中的标志并重新启动来重新配置 K3s 成为可能。
尽管 K3s 内置了 containerd,但它仍然支持使用 Docker 作为容器运行时。所有嵌入式的 K3s 组件都可以关闭,使用户可以灵活安装自己的入口控制器、DNS 服务器和 CNI。
兑现 Kubernetes 的无处不在承诺
K3s 如此小巧,可以在许多地方运行,包括可以从端到端运行 K3s。开发人员可以直接使用 K3s,或通过类似 K3d 或 Rancher Desktop 的嵌入式解决方案,而无需在本地工作站上分配多个 CPU 核心和几 GB 的 RAM。
CI/CD 系统可以使用 K3d 在 Docker 内部启动 K3s 集群,并在批准应用程序投入生产之前使用它们来测试应用程序。生产环境可以以 HA 配置运行完整的 K3s 集群,具有多个隔离的控制平面和数据平面节点以及一组工作节点,来将应用程序交付给用户。
环境的一致性确保开发人员创建的内容在生产中运行的结果相同,从而将一致的容器操作应用到集群本身。
比 K8s 更快
在 Kubernetes 需要花费 10 分钟或更长时间进行安装的世界中,K3s 可以在任何 Linux 系统上安装,并在不到一分钟内提供一个可用的集群。其轻量级架构对于运行的工作负载而言也比标准 Kubernetes 更快。
在 K8s 无法运行的地方运行
K3s 小巧的足迹使得在以前 Kubernetes 无法触及的地方进行容器工作负载的编排和运行成为可能,比如在有限或间歇性连接的恶劣环境中运行。
K3s 包含一个 Helm 控制器[4],它将通过 HelmChart 清单安装 Helm 软件包。在安装之前或之后,可以将任何 Kubernetes 清单放置在控制平面节点上的目录中,这些资源将自动安装到集群中。这些功能的结合使得在引导集群的瞬间就具备所需的各个应用程序,无需外部干预。
K3s 已成功用于卫星、飞机、潜艇、车辆、风力发电场、零售场所、智能城市等通常无法运行 Kubernetes 的地方。
K3s 是物联网和边缘计算的更好选择。
升级
K3s 提供简化的集群升级体验。你只需再次运行安装脚本即可下载最新版本并自动完成升级:
curl -sfL https://get.k3s.io | sh -
在每个节点上重复执行此命令将使你的集群升级到最新的稳定版本,无需任何手动干预。
速度
在等效硬件上部署的 K8s 集群和 K3s 集群应该可以以相似的性能运行你的容器,因为它们使用相同的 containerd 运行时。然而,K3s 非常轻巧,它安装和启动控制平面的速度要比 K8s 快得多。
相比之下,上游的 Kubernetes 可能需要几分钟才能启动(而 K3s 通常在一分钟内可用)。这使得 K3s 更适合于临时的集群,例如本地开发和测试环境。你可以快速启动一个集群,使用后再将 K3s 关闭。
安全
K3s 在设计上是安全的,并提供了一个最小的攻击面。所有组件都打包在一个二进制文件中,减少的依赖关系使得安全漏洞的出现可能性较小。
K3s 与 K8s 的比较
Kubernetes适用于大型企业和复杂的部署场景,它具有丰富的功能和灵活性,因此也更加复杂和需要更多的资源。
K3s专注于较小的边缘、IoT 或较小规模的部署,适用于资源受限的环境。
何时选择 K3s?
选择在项目中使用 K3s 还是 K8s 将取决于项目的需求和你可用的资源。如果你想在 Arm 硬件(如 Raspberry Pi)上运行 Kubernetes,那么 K3s 将为你提供完整的 Kubernetes 功能,同时为工作负载留出更多的 CPU 和 RAM。
另一方面,如果你想在具有 24 个 CPU 核心和 128GB RAM 的云实例上运行 Kubernetes,那么 K3s 与 RKE 或 RKE2 等 Kubernetes 发行版相比并没有真正的优势。
如果你在本地运行 Kubernetes,并且不需要所有云提供商的额外功能,那么 K3s 是一个出色的解决方案。你可以将其与外部 RDBMS 或内嵌或外部 etcd 集群一起使用,它将在相同环境中比标准的 Kubernetes 发行版运行得更快。
如果你定期启动和关闭 Kubernetes 集群,用于云环境横向扩展、运行批处理作业或进行持续集成测试,那么你将体会到 K3s 集群上线的速度有多快。
部署
k3s架构图
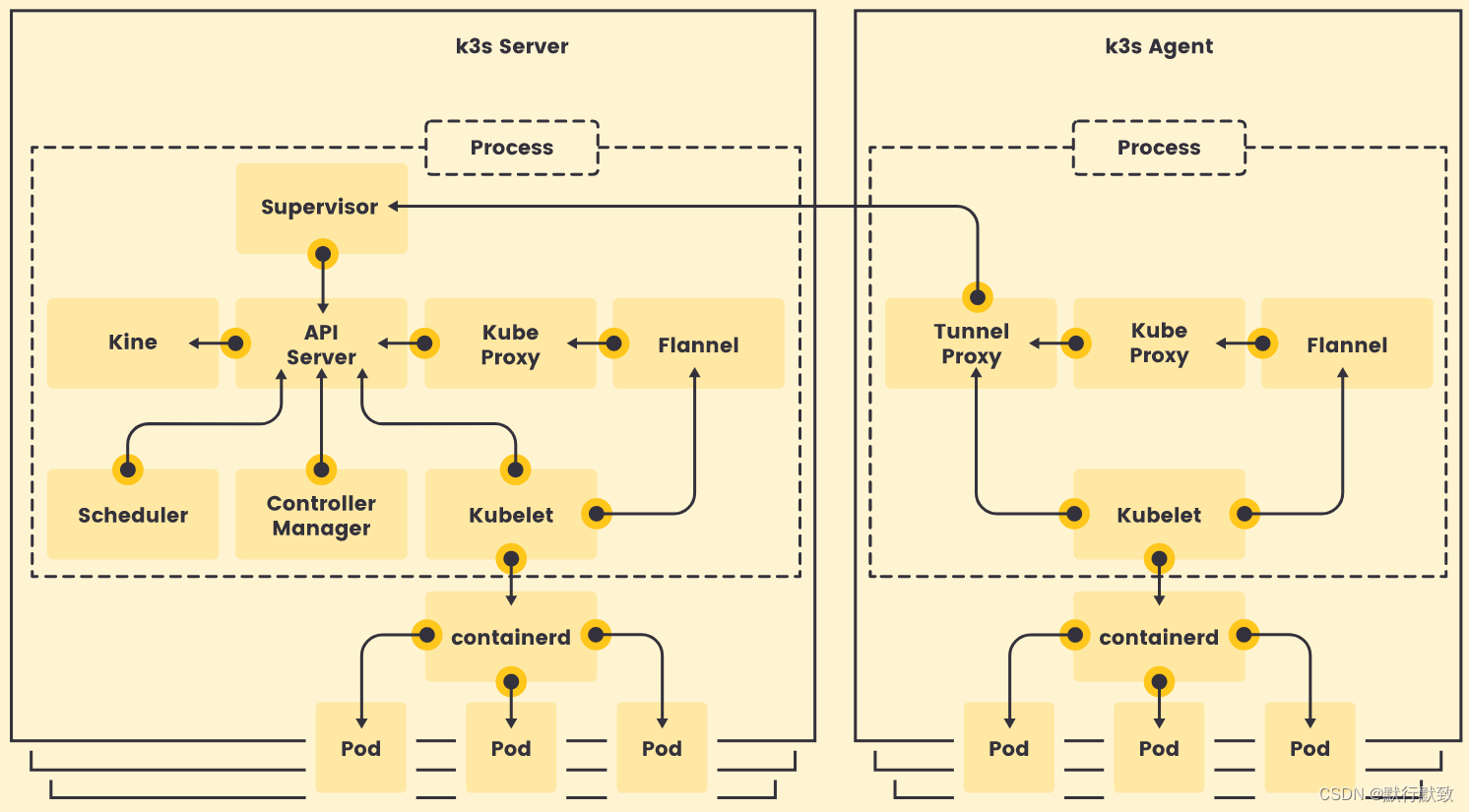
# 运行一个 K3s 集群
hostnamectl set-hostname k3s-master001
hostnamectl set-hostname k3s-node001
cat /etc/hosts
192.168.10.198 k3s-master001
192.168.117.7 k3s-node001
mkdir /opt/k3s;cd/opt/k3s
curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn sh -
# 查看kubeconfig文件
cat /etc/rancher/k3s/k3s.yaml
# 查看token
cat /var/lib/rancher/k3s/server/node-token
xxxxxxxxxxxxx0bf5c85d33a1419axxxxxxxxxxx::server:xxxxxxxxxx673b861xxxxxxxx
# 安装 Agent 节点并将添加到集群
curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn K3S_URL=https://192.168.10.198:6443 K3S_TOKEN=xxxxxxxxxxxxx0bf5c85d33a1419axxxxxxxxxxx::server:xxxxxxxxxx673b861xxxxxxxx sh -
备份和恢复
除了需要备份数据存储本身,还必须备份位于 /var/lib/rancher/k3s/server/token 的 Server Token 文件。
由于 Token 用于加密数据存储内的凭证数据,因此如果还原时没有使用相同的 Token 值,快照将无法使用。
- 如果你采用的是默认(单节点,集群中只允许一个 master 节点)安装方式,K3s 数据存储采取嵌入式 SQLite 数据存储方案。
- 如果你采用外部数据库实现 K3s 的高可用安装,K3s 的数据将存储在外部的数据库中。
- 如果你采用嵌入式 etcd 实现 K3s 的高可用安装,那 K3s 数据将存储在由 K3s 启动的嵌入式 etcd 中。
使用嵌入式 SQLite 数据存储进行备份和恢复
K3s 内置了 SQLite 作为单节点模式下的数据库,这种模式下,K3s 启动之后会将数据存储在主机上的 /var/lib/rancher/k3s/server/db 目录中,所以只需针对这个目录进行备份和恢复即可。
# 备份
cp -rf /var/lib/rancher/k3s/server/db /opt/db
# 恢复
systemctl stop k3s
rm -rf /var/lib/rancher/k3s/server/db
cp -rf /opt/db /var/lib/rancher/k3s/server/db
systemctl start k3s
使用外部数据存储进行备份和恢复
当使用外部数据存储时,备份和恢复操作是在 K3s 之外处理的。对于 K3s 来说,只需要在数据库恢复之后,重启 K3s 服务即可。
K3s 支持 etcd、MySQL、MariaDB、PostgreSQL 作为外部数据存储的数据库,本示例使用 MySQL 作为示例来演示备份和恢复。
# 备份
mysqldump -uroot -p --all-databases --master-data > k3s-dbdump.db
# 停止k3s服务
systemctl stop k3s
# 恢复
mysql -uroot -p < k3s-dbdump.db
systemctl start k3s
使用嵌入式 etcd 数据存储进行备份和恢复
创建快照
默认情况下,K3s 会在 00:00 和 12:00 自动创建快照,并保留 5 个快照。当然,你也可以禁用自动快照或者通过 k3s etcd-snapshot save 来手动创建快照。
快照目录默认为 ${data-dir}/server/db/snapshots。data-dir 的默认值为 /var/lib/rancher/k3s,你可以通过设置 --data-dir 标志来更改。
从快照恢复集群
当 K3s 从备份中恢复时,旧的数据目录将被移动到 ${data-dir}/server/db/etcd-old/。然后 K3s 将尝试通过创建一个新的数据目录来恢复快照,最后使用具有一个 etcd 成员的新 K3s 集群启动 etcd。
示例
有 3 个 K3s Server 节点,分别是 S1、S2和 S3,快照位于 S1 上。
# s1
ls /var/lib/rancher/k3s/server/db/snapshots/
on-demand-ip-172-31-3-36-1688025329
systemctl stop k3s
k3s server \
--cluster-reset \
--cluster-reset-restore-path=/var/lib/rancher/k3s/server/db/snapshots/on-demand-ip-172-31-3-36-1688025329
# s2 s3
systemctl stop k3s
rm -rf /var/lib/rancher/k3s/server/db/
# s1
systemctl start k3s
# s2 s3
systemctl start k3s
# S2 和 S3 虽然使用空的数据目录来启动 K3s 服务,但启动时会自动到 S1 去同步数据,从而完成 S2 和 S3 的恢复。
k3s etcd-snapshot 子命令支持 S3 兼容的 API,这样我们可以将快照自动或手动的上传到 S3 中存储,并且用于 K3s 的数据恢复。
K3s 集群的灾难恢复
当 K3s 主机故障导致无法启动时,如何实现全面的备份和恢复。
示例
主机ip-172-31-3-36 为 K3s server 节点,ip-172-31-6-61 为 K3s agent 节点。
# ip-172-31-3-36
# 备份SQLite数据文件和token文件
cp -rf /var/lib/rancher/k3s/server/db /opt/db
cp /var/lib/rancher/k3s/server/token /opt/
# 卸载K3s server 和 agent
k3s-uninstall.sh
k3s-agent-uninstall.sh
# 恢复K3s server 和 agent
cp -rf /opt/db /var/lib/rancher/k3s/server/db
cp -rf /opt/token /var/lib/rancher/k3s/server/db
curl -sfL https://get.k3s.io | sh -
curl -sfL https://get.k3s.io | K3S_URL=https://172.31.3.36:6443 K3S_TOKEN=3b986d9142401a8570127465c761efee sh -
# 验证
kubectl get nodes
监控k3s
实战指南:使用 kube-prometheus-stack 监控 K3s 集群
# 配置k3s-master001
mkdir -p /etc/rancher/k3s/
cat >/etc/rancher/k3s/config.yaml <<EOL
# /etc/rancher/k3s/config.yaml
kube-controller-manager-arg:
- "bind-address=0.0.0.0"
kube-proxy-arg:
- "metrics-bind-address=0.0.0.0"
kube-scheduler-arg:
- "bind-address=0.0.0.0"
# 公开 etcd metrics
etcd-expose-metrics: true
EOL
curl -sfL https://get.k3s.io | K3S_TOKEN=SECRET sh -s - server --cluster-init
# 配置k3s-node001
mkdir -p /etc/rancher/k3s/
cat >/etc/rancher/k3s/config.yaml <<EOL
# /etc/rancher/k3s/config.yaml
kube-proxy-arg:
- "metrics-bind-address=0.0.0.0"
EOL
curl -sfL https://get.k3s.io | K3S_TOKEN=SECRET sh -s - agent --server https://<ip or hostname of server>:6443
# 检查端口监听状况
ss -lntp | grep -E "10257|10259|10249"
# 将 traefik 的 metrics 端口修改为 9900
cat >/var/lib/rancher/k3s/server/manifests/traefik-config.yaml <<EOL
apiVersion: helm.cattle.io/v1
kind: HelmChartConfig
metadata:
name: traefik
namespace: kube-system
spec:
valuesContent: |-
ports:
metrics:
port: 9900
exposedPort: 9900
EOL
# 编辑配置
vi values.yaml
kubeControllerManager:
enabled: true
endpoints:
- 172.31.38.19
service:
enabled: true
port: 10257
targetPort: 10257
serviceMonitor:
enabled: true
https: false
kubeScheduler:
enabled: true
endpoints:
- 172.31.38.19
service:
enabled: true
port: 10259
targetPort: 10259
serviceMonitor:
enabled: true
https: false
kubeProxy:
enabled: true
endpoints:
- 172.31.38.19
- 172.31.41.39
service:
enabled: true
port: 10249
targetPort: 10249
kubeEtcd:
enabled: true
endpoints:
- 172.31.38.19
alertmanager:
alertmanagerSpec:
storage:
volumeClaimTemplate:
spec:
storageClassName: local-path
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
prometheus:
prometheusSpec:
storageSpec:
## Using PersistentVolumeClaim
##
volumeClaimTemplate:
spec:
storageClassName: local-path
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
grafana:
persistence:
type: pvc
enabled: true
storageClassName: local-path
accessModes: ["ReadWriteOnce"]
size: 1024Mi
# Helm 安装 kube-prometheus-stack
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
kubectl create namespace monitoring
helm install prometheus-community prometheus-community/kube-prometheus-stack --namespace monitoring -f values.yaml
helm -n monitoring upgrade prometheus-community prometheus-community/kube-prometheus-stack -f values.yaml
# 列出所有 namespace 中的 releases
helm list -A
# 列出 monitoring namespace 中的 releases
helm list -n monitoring
# 检查 prometheus stack release 状态
helm status prometheus-community -n monitoring
网络策略
高可用K3s
高可用部署K3S集群
k3s高可用部署实践及其原理
这应该是最适合国内用户的K3s HA方案
混合云部署K3s
多云搭建k3s集群(带wg管理UI)
探索 K3s 简单高效的多云和混合云部署
其他扩展
K3s 部署中解决获取真实 IP 的问题:使用 Calico 实现真实 IP 传递
深入理解 K3s 镜像重写:从配置到实际应用
K3S 集群搭建:裸金属系统中 etcd 和 MetalLB 的实现
保姆级实操教程,如何在树莓派上玩转k3s!
有点 【k3s】年度最佳边缘计算集群方案















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









