





 本文介绍如何利用Jupyter Notebook的代码块运行功能,从爬虫因错误中断的地方重新启动脚本。通过保持浏览器会话打开并调整代码,可以继续爬取数据,特别适用于处理分页和服务器不稳定的情况。尽管自动化这一过程尚未实现,但这是一个有效的临时解决方案。
本文介绍如何利用Jupyter Notebook的代码块运行功能,从爬虫因错误中断的地方重新启动脚本。通过保持浏览器会话打开并调整代码,可以继续爬取数据,特别适用于处理分页和服务器不稳定的情况。尽管自动化这一过程尚未实现,但这是一个有效的临时解决方案。
您是否曾经遇到过刮板遇到错误的情况(可能是服务器错误或刮板块)并且不得不重新开始?
你真幸运! 您可以使用Jupyter从刮板终止的位置重新启动脚本。 我不知道这是如何工作的,但让我给您简要说明如何使用此解决方法。
该解决方案很大程度上取决于Jupyter的“运行代码”功能,在此功能中,我们可以独立于每批代码运行代码块。
从常用的抓取库开始:
Python,硒,熊猫,美丽汤和您的老朋友时光。
是该项目所需的库。
在这个解释中,我不会深入研究源代码,而是将展示我的第一批抓取代码的外观。
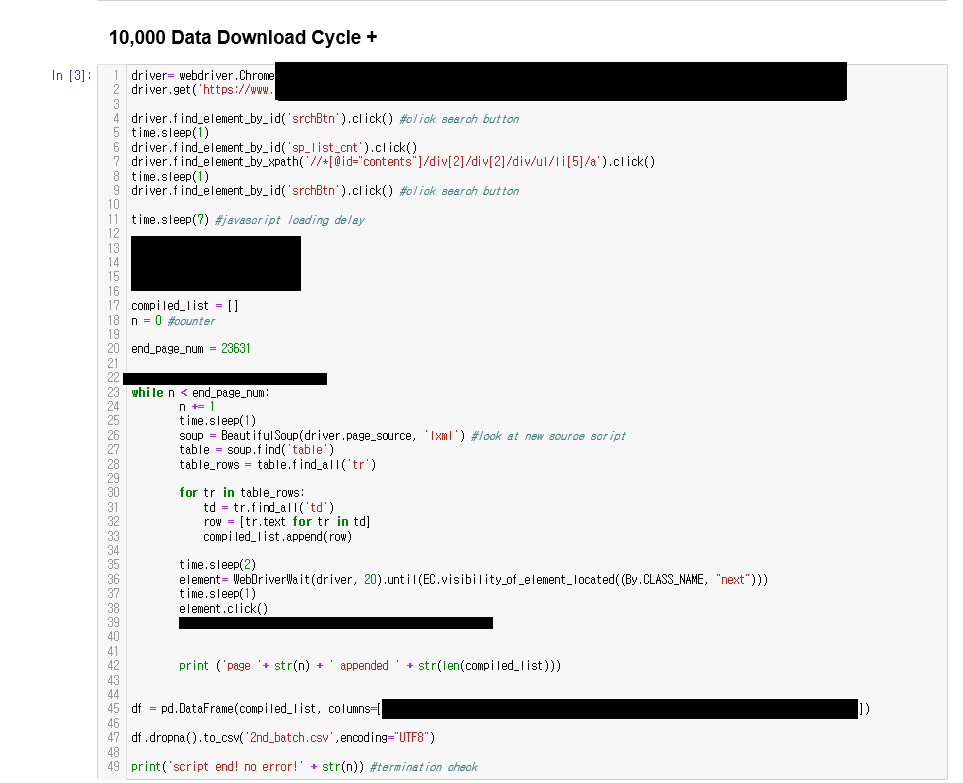
我的代码的简要说明如下:
转到目标站点执行一些操作以使用xpath转到我想使用的特定站点。创建一个名为Compiled_list的数组将javascript中的``地狱''从JavaScript表中剔除(处理具有分页功能的网站不会显示在URL)将数组中的数据``转换''为大熊猫数据框。将大熊猫数据表导出为CSV,并用页面命名它们某些部分由于数据敏感性而被屏蔽
我们在这里...什么? 服务器已关闭...。

抓很多东西的人讨厌这个错误信息
但是就像我在本文的第一部分中所说的那样,创建另一批代码,可以继续您开始使用的代码。
在继续之前 :
1)请勿关闭与您的脚本连接的Chrome浏览器。 如果您这样做,则所有会话/进度都将被删除。
2)请记住检查您抓取的页码,并在下一批代码中进行相应的重新编码。
因此,再次运行该程序……在导出部分中,在设置编号为no的ID号中稍有更改。
在运行此代码块之前,我编辑了设置号码
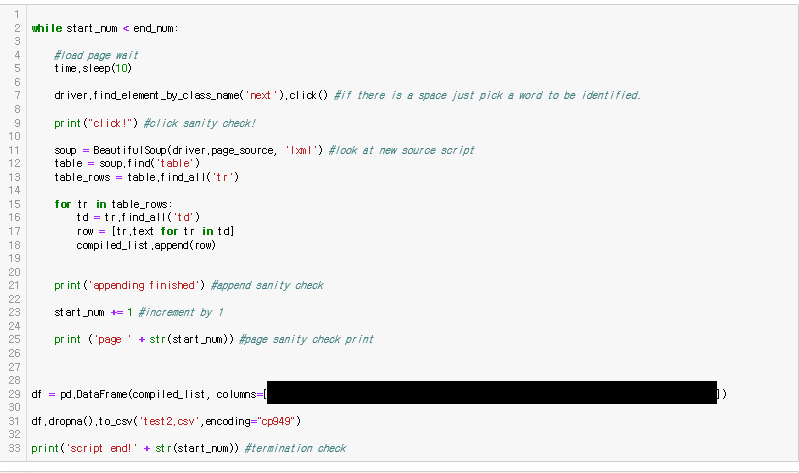
和田田! 我们继续抓取其余的场景

其余代码正在运行:-)
但是,如果网站服务器像我的目标网站一样不稳定,请提防连续错误。 每当您的程序与网站的连接中断时,请重复上述过程。
我无法弄清楚如何使这部分自动化,但是如果您的真棒读者知道答案,请在下面评论。
无论如何,就是伙计们〜jupyter抓取时间机器。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









