






libsms in an open source C library that implements SMS techniques for analysis, transformation and synthesis of musical sounds based on a sinusoidal plus residual model. It is derived from the original code of Xavier Serra, as part of his PhD thesis. The goal of this library is to organize the many different components of SMS into an efficient, open, and well-documented architecture that can be utilized by various software systems within their own programming styles. See the library documentation below.
Latest Version:
libsms-1.101 - (October 27, 2009)interesting changes (see doc/changes.txt for details)
- Now compiles on Windows (Hurray John!)
- new memory allocation schemes to handle changing window sizes appropriately
- many python test scripts for using pysms
- Mersenne Twister algo for random number generation
- Removed FFTW3 library and now just use OOURA - it is slightly slower but the code is 5x cleaner. Who knows, maybe one day it will be back.
- cepstrum.c functions for descrete cepstrum analysis and spectral enveloping
documentation generated with doxygen. dependencies: scons, libsndfile
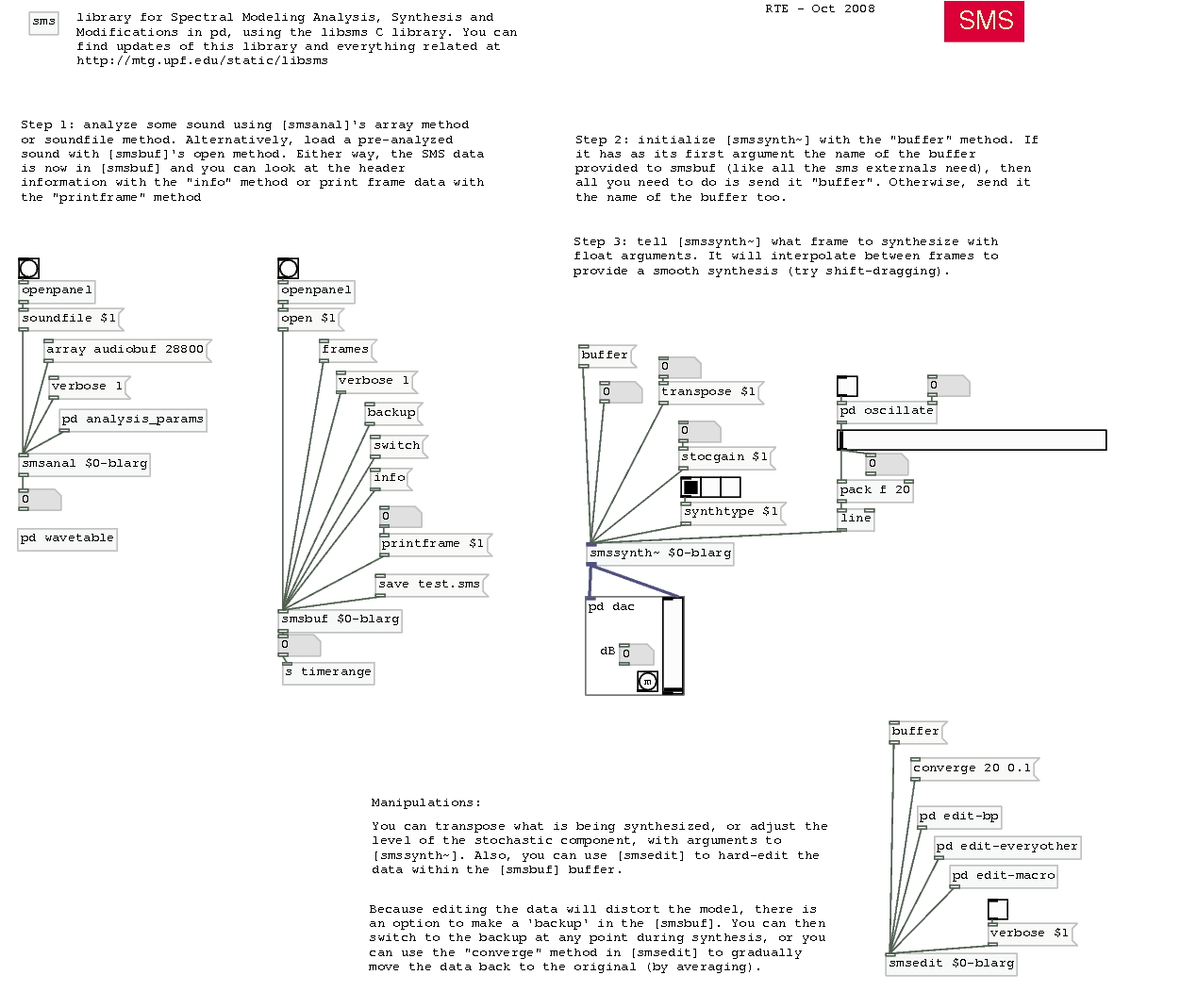
[smspd] external library for Pure Data:
smspd-0.95 - real-time SMS synthesis and editing sure is nice (Nov. 15, 2008)dependencies: libsms (above), Pure Data
externals: you will find these in [smspd]:
- [smsbuf] - main storage place for sms data
- [smsanal] - analysis that works on soundfiles or arrays of audio
- [smssynth~] - real-time synthesis and basic manipulations (i.e. transpose)
- [smsedit] - lowlevel editing of data within the buffer
Please read the included README and email anything you like.
Links:
libsms
1.1
libsms in an open source C library that implements SMS techniques for the analysis, transformation and synthesis of musical sounds based on a sinusoidal plus residual model. It is derived from the original code of Xavier Serra, as part of his PhD thesis. You can read about this and many things related to SMS at the sms homepage: http://mtg.upf.edu/technologies/sms/
Since Janurary 2008, the code Serra wrote, originally for NextStep, has undergone changes to make it useful on modern day platforms. The goal of this library is to be usable in real-time audio applications for performing high-fidelity synthesis of sound models. It should work on most platforms available, although Linux is the only one tested so far. Although the code is in good working order (and quite fast), the algorithms have not been looked at in many years and there is probably many ways to improve them since 1991. So, it will be an ongoing effort to improve this library in many ways: optimizing, improving/verifying the algorithms, adding high-level descriptors, the list goes on and on.. If you would like to comment, suggest, or contribute in any way, send to the following email: rich.eakin@gmail.com
Using libsms and the included tools
This package not only contains a C library for SMS, but a set of tools in various forms for using the library. They are far from complete in implementation, but are in good working condition at this point.
The main idea behind Spectral Modeling Synthesis is that you can seperate different components of a sound that have distinctive spectral components. These components can then be analyzed in a manner more appropriate to their characteristics. To date, there are three main components that can be seperated and represented in a spectral model, 2 of which are accomplished by this library ( hopefully the third will be implemented in due time):
- deterministic: spectra that is well modeled by evolving sinusoidal tracks
- stochastic: spectra that has a random phase, which is characteristic of noise.
- transients: spectra that begins stochastic but evolves into a deterministic signal. This component is not yet implemented in this library, but is nonetheless important to note, as it is analyzed along with the rest of sound you are attempting to model.
There is much to be read at the main UPF SMS page about these components, so i won't say much more about the theory her other than the more information you know about the sound before analysis, the better.
In theory, the analysis is a seperate process from synthesis. This may not be as completely necessary now that computers are fast enough to perform the analysis in real-time (and there are definitally cases where this is desireable), but a good analysis is hardly ever automatic. For this reason, one may have to try several sets of parameters on a given sound type before a good analysis is found. It is also advisable to make every attempt to obtain a good deterministic analysis before expecting anything decent from a stochastic model.
sms.h has all the global declarations and needs to be included in whatever c code will use the library.
Building and Installing
To build the library, a simple "scons" from the main directory should do it. There are a few options you can see with "scons --help". To install the library, type "sudo scons install", which will install the static library libsms.a, the tools, and the manpages for tools. To install the python or pd components, see their sections below.
Command-Line tools
The following tools are included with the libsms package (and installed system-wide if you did a "sudo scons install"). Looking at their sources will give a good explanation on how to use the library.
- smsAnal: analysis a sound file and produce a SMS model, stored in *.sms format
- smsSynth: synthesizes a *.sms format model. Also does basic(time/pitch/stochastic amplitude) manipulations
- smsClean: clean an .sms file, scanning the entire model to connect short tracks into longer ones.
- smsPrint: the contents of a .sms file.
- smsResample: adjust the framerate of *.sms file
Examples
In the examples folder, there are some bash scripts that show analysis and synthesis of different types of sounds. The samples were downloaded from http://www.freesound.org and the url for the sample used is included with each script. They should help you get started with knowing what parameters to use for different characteristic sounds.
Python Module
The SWIG interface file is in the subfolder 'python', which can be used to build a python wrapper. You will of need (the websites are listed here, but it is probably easier to get these from a package manager like apt, yin, or macports):
- SWIG: http://www.swig.org/
- the NumPy python module: http://numpy.scipy.org/)
- the SciPy python module (to run the included test and example scripts): http://www.scipy.org/
to compile and install, type 'scones pythonmodule=yes' (with root permissions) from the main directory.
If everything goes well, you should have '_pysms.so', which is loadable in python using "import sms".
There are some tests and examples within the python directory.
Other Included Files
There is a log at doc/log.org, within the main package. It contains many things done, things to-do, and a wish list of things that would be really nice to-do.
Structure of libsms
These are the most important data structures:
SMS_Header - information that is stored along with data, used from correctly resynthesizing. Also contains space for higher-level descriptors, but they are not currently used.
SMS_AnalParams - everything to compute analysis
SMS_SynthParams - everything to compute synthesis
SMS_ModifyParams - all modifications are set using this
SMS_Data - where the analysis data is kept
The main file for analysis routines is analysis.c. For synthesis, see synthesis.c. From these two files (any by looking at how they are prepared in the command line tools), you can follow different functions of the code.
Info about the coding style used in this library:
- all functions used globally throughout the library are prepended with sms_ and are of the form sms_camelCase
- all data structures are prepended with SMS_ and are of the form SMS_CamelCase
- all global typedefs and defines are prepended with SMS_ and are capitalized
- there are various other static functions within the library that are not of this format, but are not meant to be used globally. Even still, there are some functions that are gobally defined that do not need to be.. but there are other fish to fry at the moment.
Terminology Used:
- tracks vs. trajectories: Throughout various implementations and writings on Spectral Modeling Synthesis, these two terms are used interchangeably for the partial sinusoidal components of a sound, or deterministic sinusoidal decompositinon. In this code only the term 'track' is used for clarity and universality.
- 'frames': the term frame is used because the data is kept in a discrete frame of time, relative to the original analysis. Of course, in synthesis it is not necessary to go frame-by-frame because the synthesiser will interpolate between whatever two frames it is given in succession.
Necessary Third Party Libraries:
- libsndfile: http://www.mega-nerd.com/libsndfile/ - soundfile input and output in various formats
- GSL: http://www.gnu.org/software/gsl/ - GNU Scientific Library (for matrix operations in cepstrum.c)
Generating this Documentation
To regenerate this documentation using doxymacs, type "scons doxygen" from the the main directory. You should then get html documentation in the folder "doc/html/".
Copying
Copyright (c) 2008 MUSIC TECHNOLOGY GROUP (MTG) UNIVERSITAT POMPEU FABRA
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}