






Hive的元数据迁移
从Mysql导出完整的hive元数据
最简单的方式:从Mysql导出完整的hive元数据。然后把语句在新环境运行。能最大限度的保证hive元数据的完整性,也是最省时间的一种方法。但条件是:1.要保证原环境和新环境的HDFS路径一致,不一致的话需要修改元数据的路径与新环境的路径相同。2.迁移的时候要保证新环境的hive是空的,不然运行时有可能会影响其他的数据,有风险。
用shell脚本导出元数据
这个方案使用show create table获取创建table的sql语句,然后在新集群的hive上面执行对应的语句。可执行下面的shell脚本批量获取语句:
#!/bin/bash
################################
#脚本功能:从旧环境导出元数据语句
#脚本参数:database_array tablename_path createtable_path
#功能实现:将数据表的建表语句打印,形成sql文件
#示 例: sh export_matedata.sh "ods dwd dws" /data/tablename /data/createtable
################################################################################
database_array=$1
tablename_path=$2
createtable_path=$3
for database in ${database_array[@]}
do
#echo $database
hive -e "use $database;show tables;" >$tablename_path/$database.txt
#不需要去掉首行
#sed -i '1d' /data/zyfiles/hivedata/$database.txt
done
for database in ${database_array[@]}
do
cat $tablename_path/$database.txt |while read line
do
hive -e "use $database;show create table $line;" | sed '$ a;'>>$createtable_path/createtable_$database.sql
#如果需要去掉首行,加上下面的语句
# | sed '1d'
echo "use $database;show create table $line"
done
done
#状态
if [ $? -ne 0 ]
then
echo "[ERROR][`date +"%Y-%m-%d %H:%M:%S"`] Failed export hive metadata."
exit 1;
fi
#结束
echo "[INFO][`date +"%Y-%m-%d %H:%M:%S"`] Successfully export hive metadata."
exit 0;
此脚本执行可获取sql执行,运行截图示例如下:
!](https://img-blog.csdnimg.cn/66bdfdd0677b4c5b969a1111a43b0035.png)

下一步:将获取到的createtable_KaTeX parse error: Expected group after '_' at position 36: …。在获取createtable_̲database.sql之后,要将文件里的LOCATION修改为新环境的HDFS地址。
注意:在执行获取到的ddl文件前注意,对应的database需要先创建出来,然后在新集群上面执行下面的语句。
新集群运行示例:
创建对应的database
例:hive -e ‘create database KaTeX parse error: Expected group after '_' at position 43: … -f createtable_̲database.sql
待脚本都运行成功之后,元数据迁移完成。
第二步:hdfs数据文件迁移
对于数据的迁移,可以用hadoop distcp命令进行文件夹的迁移。但前提是保证两个集群网络是连通的状态。CDH版本保持一致。
可用下面的语句:
例:hadoop distcp -updata hdfs://cdh01:8020/user/hive/warehouse/ hdfs://cdh02:8020/user/hive/warehouse/
如果两个环境的CDH有版本差异,低版本向高版本迁移的话,可以加上参数-skipcrccheck:
例:hadoop distcp -skipcrccheck -updata hdfs://cdh01:8020/user/hive/warehouse/ hdfs://cdh02:8020/user/hive/warehouse/
如果环境有Kerberos认证,需要加上参数-D ipc.client.fallback-to-simple-auth-allowed=true:
例:hadoop distcp -D ipc.client.fallback-to-simple-auth-allowed=true -update hdfs://cdh01:8020/user/hive/warehouse/ hdfs://cdh02:8020/user/hive/warehouse/
例如,对某个库进行迁移,执行命令如下:
hadoop distcp -updata hdfs://cdh01:8020/user/hive/warehouse/test.db hdfs://cdh02:8020/user/hive/warehouse/test.db
运行时会形成一个MR任务,成功结果如图:
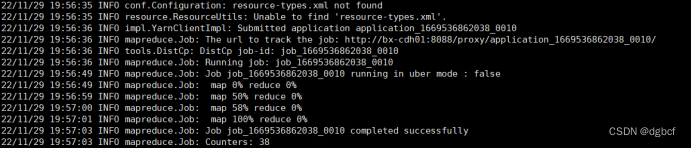
1.参数说明:
cdh01是源环境地址,cdh02是目标环境地址
-updata:迁完元数据,会在新环境中存在空的文件目录,-updata可以将空的文件目录替换掉。-updata会对比两个同名目录,如果有差异,就会更新。
-skipcrccheck:省略crc检查,如果CDH版本一样,可以不加。CDH版本不一致,需要加上。
-D ipc.client.fallback-to-simple-auth-allowed=true:环境有Kerberos认证,运行hadoop distcp会报出客户端配置了安全连接, 但是服务器请求回退到非安全的SIMPLE模式的错误。加上-D ipc.client.fallback-to-simple-auth-allowed=true可以解决。
2.语句运行成功后,查看hdfs是否已经有了迁移的数据文件。如果已经有了,数据迁移完成。
注意:如果两个环境网络不互通,就需要将数据文件先迁出到本地,然后上传到新环境的HDFS相应的目录下。
参考步骤如下:
先将源环境的HDFS数据文件导出到本地命令:
hdfs dfs -get /user/hive/warehouse/test.db /data/warehouse/
然后将数据文件拷贝到新环境的目录下。
将新环境的目录下的数据文件上传到新环境HDFS的相应目录下:
hdfs dfs -put /data/warehouse/test.db /user/hive/warehouse/
第三步:元数据与数据文件关联
因为元数据和数据文件是分开迁移的,需要msck命令将表和数据关联起来,可用下面的脚本完成关联:
#!/bin/bash
################################
#脚本功能:将元数据和数据文件关联
#脚本参数:database_array
#功能实现:将元数据和数据文件关联,行成完成的hive数据表
#示 例: sh msck_repair.sh "ods dwd dws" /data/databases
################################################################################
database_array=$1
tablename_path=$2
for database in ${database_array[@]}
do
cat $tablename_path/$database.txt |while read line
do
hive -e "use $database;msck repair table $line;;"
done
done
#状态
if [ $? -ne 0 ]
then
echo "[ERROR][`date +"%Y-%m-%d %H:%M:%S"`] Be connected with data Failed."
exit 1;
fi
#结束
echo "[INFO][`date +"%Y-%m-%d %H:%M:%S"`] Be connected with data Successful."
exit 0;
运行语句示例,执行:
sh msck_repair.sh “ods dwd dws”
运行结果如图:

风险点
1.DistCp命令迁移注意CDH集群版本差异
2.不同表的元数据存储格式和路径可能存在差异,在新环境创建表时,需要确认好。















 3464
3464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









