









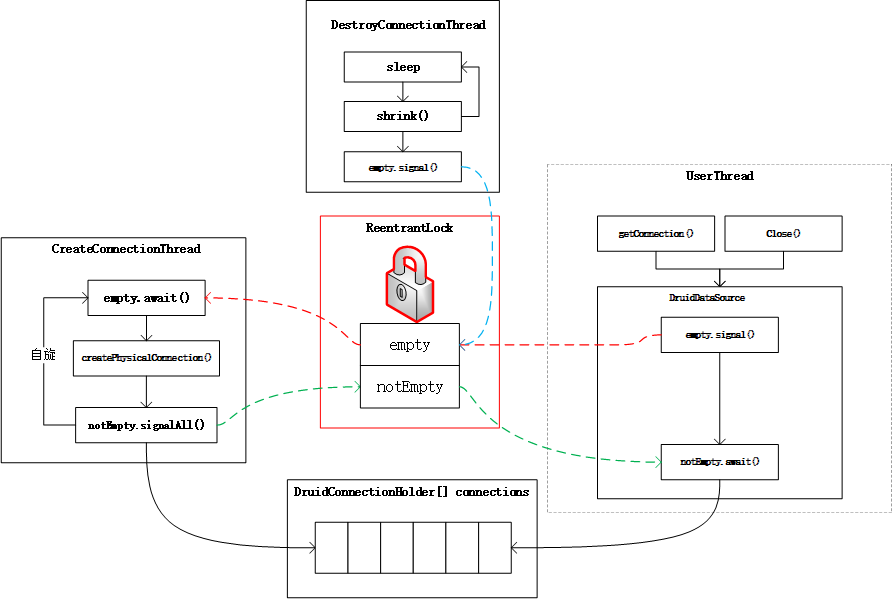
DruidDataSource数据库连接池的的本质,实际上是一个利用ReentrentLock和两个Condition组成的生产者和消费者模型。
1.DruidDataSource中的锁
在DruidAbstractDataSource类中,定义了一个非常重要的锁,几乎所有的线程都使用到了这个锁。
//可重入锁 lock
protected ReentrantLock lock;
//非空条件变量
protected Condition notEmpty;
//空条件变量
protected Condition empty;
这三个变量通过构造函数初始化,可以指定采用公平锁或者非公平锁。
public DruidAbstractDataSource(boolean lockFair){
lock = new ReentrantLock(lockFair);
notEmpty = lock.newCondition();
empty = lock.newCondition();
}
看到这个数据结构,很自然就能想到,在前面学习线程同步的时候,通过Condition实现生产者和消费者模型。
生产者和消费者的任何操作都需要获得lock,之后生产者根据empty条件变量await。当连接池中连接被消耗,触发empty的通知的时候。
阻塞在empty上的生产者开始创建连接。创建完成之后,发送notEmpty的sigal信号,触发在notEmpty上的消费者来获取连接进行消费。这是Druid连接池的基本原理。
而连接的缓冲区位于DruidDataSource中的DruidConnectionHolder[]数组中。
2.DruidDataSource中的线程
在DruidDataSource的源码中,定义了如下线程:
2.1 CreateConnectionThread
该线程通过init方法中通过createAndStartCreatorThread();启动。
protected void createAndStartCreatorThread() {
if (createScheduler == null) {
String threadName = "Druid-ConnectionPool-Create-" + System.identityHashCode(this);
//启动线程
createConnectionThread = new CreateConnectionThread(threadName);
createConnectionThread.start();
return;
}
initedLatch.countDown();
}
而CreateConnectionThread线程启动之后,在run方法中 ,执行过程伪代码:
//死循环:
for (;;) {
// addLast
//获得锁
lock.lockInterruptibly();
//根据emptyWait 判断是否能够创建连接
if (emptyWait) {
empty.await();
}
//同时需要控制防止创建超过maxActive数量的连接
if (activeCount + poolingCount >= maxActive) {
empty.await();
continue;
}
//创建真实连接
connection = createPhysicalConnection();
//非空信号,通知消费线程来获取
notEmpty.signal();
//解锁 这一步在finally中
lock.unlock();
}
当然,创建线程的代码逻辑远比上述逻辑要复杂。因为要处理创建过程中的各种异常。中间还需要涉及若干个方法。
从中不难看出,每个线程池DruidDataSource都由一个唯一的CreateConnectionThread线程,这个线程负责创建连接,起到生产者的作用。
这个线程在DriudDataSource启动的时候通过init方法启动。
2.2 DestroyConnectionThread
DestroyConnectionThread是线程池中的销毁线程,当线程池中出现空闲连接超过配置的空闲连接数,或者出现一些不健康的连接,那么线程池将会通过DestroyConnectionThread线程将连接回收。
DestroyConnectionThread线程同样也是通过init方法调用createAndStartDestroyThread()启动。
protected void createAndStartDestroyThread() {
destroyTask = new DestroyTask();
//如果连接非常多,单个销毁线程的效率会比较低,如果回收过程出现阻塞等情况,那么此时可以自定义一个destroyScheduler线程持,通过这个线程池配置定始调用回收。
//这个地方如果需要使用需要自行配置destroyScheduler并配置参数,这与启动过程的createScheduler类似
if (destroyScheduler != null) {
long period = timeBetweenEvictionRunsMillis;
if (period <= 0) {
period = 1000;
}
destroySchedulerFuture = destroyScheduler.scheduleAtFixedRate(destroyTask, period, period,
TimeUnit.MILLISECONDS);
initedLatch.countDown();
return;
}
String threadName = "Druid-ConnectionPool-Destroy-" + System.identityHashCode(this);
//启动销毁线程
destroyConnectionThread = new DestroyConnectionThread(threadName);
destroyConnectionThread.start();
}
实际上DestroyConnectionThread线程的run方法中,仍然是执行的是DestroyTask的run方法:
这个run方法只是增加了sleep时间。然后自旋调用 destroyTask.run();
public void run() {
initedLatch.countDown();
//死循环,自旋调用
for (;;) {
// 从前面开始删除
try {
if (closed || closing) {
break;
}
//sleep时间
if (timeBetweenEvictionRunsMillis > 0) {
Thread.sleep(timeBetweenEvictionRunsMillis);
} else {
Thread.sleep(1000); //
}
if (Thread.interrupted()) {
break;
}
//调用 destroyTask.run()
destroyTask.run();
} catch (InterruptedException e) {
break;
}
}
}
destroyTask.run()方法的本质,最终调用的是shrink方法。
@Override
public void run() {
shrink(true, keepAlive);
if (isRemoveAbandoned()) {
removeAbandoned();
}
}
shrink方法的过程比较复杂,后面会详细分析,其伪代码如下:
//获得锁
lock.lockInterruptibly();
//计算removeCount evictCount keepAliveCount等
//如果evictCount大于0 关闭连接
DruidConnectionHolder item = evictConnections[i];
Connection connection = item.getConnection();
JdbcUtils.close(connection);
//如果回收之后小于最小空闲连接
if (activeCount + poolingCount <= minIdle) {
//通知可以创建新连接了
empty.signal();
}
//解锁
lock.unlock();
当然,shrink的过程远比上述代码复杂,再shrink的过程中,由于回收线程是定始运行,因此不需要await,这个方法中只需要消费连接之后,发送empty.signal();即可。
2.3 LogStatsThread
LogStatsThread是DruidDataSource的日志打印线程。
这个线程同样是再init方法启动的时候,通过调用createAndLogThread方法启动。
private void createAndLogThread() {
if (this.timeBetweenLogStatsMillis <= 0) {
return;
}
//启动LogStatsThread线程
String threadName = "Druid-ConnectionPool-Log-" + System.identityHashCode(this);
logStatsThread = new LogStatsThread(threadName);
logStatsThread.start();
this.resetStatEnable = false;
}
其run方法为定始为timeBetweenLogStatsMillis的自旋调用,定期输出logStats统计的DruidDataSource统计信息。
public void run() {
try {
for (;;) {
try {
logStats();
} catch (Exception e) {
LOG.error("logStats error", e);
}
Thread.sleep(timeBetweenLogStatsMillis);
}
} catch (InterruptedException e) {
// skip
}
}
2.4 CreateConnectionTask
CreateConnectionTask虽然不是一个线程,但是这与创建连接的线程有关,CreateConnectionTask是用于系统启动初始化的时候使用的。
如果一个系统需要非常多的数据源,在最开始的逻辑init方法中,是每个数据源逐个创建连接。这样会造成系统启动非常慢。如果连接池一多,可能还会导致OOM.
因此,就不得不采用异步的方式来初始化线程池。这个问题可以参考issues-4270。
作者专门定义了一个createScheduler线程池,可以在多个连接池中共享,这样就能支持配置数万个连接的场景。
CreateConnectionTask的逻辑与init中的同步初始化方法类似。在此不做详细的代码分析。
2.5 DestroyTask
DestroyTask与CreateConnectionTask的方法类似,也是用于线程池共享回收的产物。如果定义了destroyScheduler线程池,那么将会通过destroyScheduler线程池定时调用回收方法。
最终调用的逻辑DestroyTask 在2.2部分有详细描述。
2.5 用户线程
用户线程在使用DruidDataSource的时候,通过getConnection方法获取连接,通过close方法将连接回归到连接池。
用户线程是连接池最大的消费者,getConnection的详细过程将在后面分析。
用户线程获取连接的过程,如果连接存在,则直接使用。如果连接数量下降到最低连接数量,则会触发empty.signal(),通知生产者创建连接。同时调用notEmpty.await()被notEmpty阻塞。
3.DruidDataSource的基本原理
DruidDataSource启动之后,会启动三个线程,分别是:
| 线程 | 说明 |
|---|---|
| CreateConnectionThread | 创建连接,做为生产者,满足消费者对连接的需求。 |
| DestroyConnectionThread | 销毁连接,将空闲、不健康的连接回收。将连接池维持在最小连接数。 |
| LogStatsThread | 打印日志,定期打印连接池的状态。 |
出日志线程之外,创建连接的线程和销毁连接的线程,与用户线程一起,组成了一个生产者消费者模型。
生产者和消费者模型通过ReentrentLock的两个Condition:empty和notEmpty。来实现生产者和消费者的阻塞和通知。
这个消费者模型中,生产者只有一个线程CreateConnectionThread,而消费者包括用户线程和定始调用的销毁线程DestroyConnectionThread。
这个过程可以用如下图表示:















 1825
1825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









