







索引的概念:索引是帮助MySQL提高查询效率的一种排好序的数据结构。
常见索引:二叉树、红黑树、哈希索引、B-Tree、B+Tree,有这么多索引,为什么我们的MySQL选择了B+Tree?下面我们一起探究下。下面的几条数据,我们分别用几种数据结构展示

一个比较方便的网站,可以帮助我们快速生成各种树结构,Data Structure Visualization,已查询Col=89为例。
1、不使用索引的情况:
按照上面的数据,则需要6次才能查找到Col=89的这条数据,如果我们的数据量非常大,则需要的次数更多,花费的时间也就自然更更多了。查询一条数据需要一次I/O操作,则结果自然可想而知。
2、用二叉树作为MySQL索引:
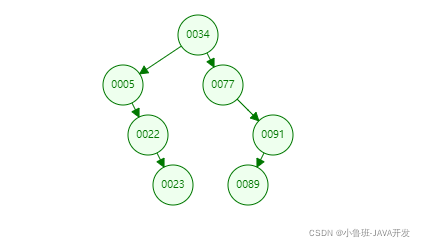
数据存放结果(左边的子元素小于父元素,右边的子元素大于父元素),查询Col=89则需要进过4次才能查找到。相比较全表查询,已经少了两次I/O。但是如果我们插入的数据是依次递增的,将会形成一颗单边增长的二叉树,比如我们一次插入2,3,4,5,6,7。这样就跟我们全表查询是一样的了,这个时候索引也就没用了。

3、用平衡二叉树作为MySQL索引:

相对于二叉树来说,平衡二叉树自动帮我们调整树的高度,查找Col=89只需要两次就可以了,但是数据多的时候,高度依然会非常高,而且他通过旋转维护树的高度也需要耗时。
4、用红黑树作为MySQL索引:

看起来跟平衡二叉树效果差不多,不过他的插入效率要比平衡二叉树高些。
5、用B-Tree作为MySQL索引:

以Max. Degree = 4,可以看出所有节点数据不重复,一个节点可以存多个元素,节点的数据从左到右依次递增,查找Col=89只需要两次就可以了,看起来效果已经很好了,那么我们用实际数据模拟下效果。

我们已主键索引为例,数字代表主键值,data是具体的这一行的数据。mysql默认一页的大小是16KB,若data中的数据过大,则一个节点能放的数据量越小,这样就会造成树的高度比较大了,所以也不是我们理想的效果。
6、用B+Tree作为MySQL索引:
以Max. Degree = 3,从上面的结构可以看出,叶子结点和非叶子节点之间有重复数据,一个节点可以存多个元素,节点的数据从左到右依次递增,叶子结点之间用指针链接。
我们的MySQL在此基础上做了修改。非叶子节点不存数据,只存索引的值。相邻的叶子结点指针相互指向,形成一个双向链表,提高区间的访问速度。
我们可以计算一下3层B+Tree能存放的数据量大小。我们先看非叶子节点,假设主键ID为 bigint 类型,那么长度为8B,指针大小在Innodb源码中6B,一共14B,那么一页(即一个节点)可以存储 16KB/14B=1170 个索引元素和 1170个指针;根节点有1170个索引和1170个指针,树高度为2的节点就有1170个,那么叶子节点的数量为 1170x1170;每个叶子节点可以存储16KB,若每条数据比较大为1KB,那么每个叶子节点可以存储16条数据;那么,高度为3的 B+Tree 的叶子节点可以存储的数据量为 1170x1170x16大约等于2000W;















 57
57











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









