






一、目标网站分析
爬取校花网http://www.xiaohuar.com/大学校花所有图片。

经过分析,所有图片分为四个页面,http://www.xiaohuar.com/list-1-0.html,到 http://www.xiaohuar.com/list-1-3.html。
二、go代码实现
// 知识点
// 1. http 的用法,返回数据的格式、编码
// 2. 正则表达式
// 3. 文件读写
package main
import (
"bytes"
"fmt"
"io/ioutil"
"net/http"
"os"
"path/filepath"
"regexp"
"strings"
"sync"
"time"
"github.com/axgle/mahonia"
)
var workResultLock sync.WaitGroup
func check(e error) {
if e != nil {
panic(e)
}
}
func ConvertToString(src string, srcCode string, tagCode string) string {
srcCoder := mahonia.NewDecoder(srcCode)
srcResult := srcCoder.ConvertString(src)
tagCoder := mahonia.NewDecoder(tagCode)
_, cdata, _ := tagCoder.Translate([]byte(srcResult), true)
result := string(cdata)
return result
}
func download_img(request_url string, name string, dir_path string) {
image, err := http.Get(request_url)
check(err)
image_byte, err := ioutil.ReadAll(image.Body)
defer image.Body.Close()
file_path := filepath.Join(dir_path, name+".jpg")
err = ioutil.WriteFile(file_path, image_byte, 0644)
check(err)
fmt.Println(request_url + "\t下载成功")
}
func spider(i int, dir_path string) {
defer workResultLock.Done()
url := fmt.Sprintf("http://www.xiaohuar.com/list-1-%d.html", i)
response, err2 := http.Get(url)
check(err2)
content, err3 := ioutil.ReadAll(response.Body)
check(err3)
defer response.Body.Close()
html := string(content)
html = ConvertToString(html, "gbk", "utf-8")
// fmt.Println(html)
match := regexp.MustCompile(`<img width="210".*alt="(.*?)".*src="(.*?)" />`)
matched_str := match.FindAllString(html, -1)
for _, match_str := range matched_str {
var img_url string
name := match.FindStringSubmatch(match_str)[1]
src := match.FindStringSubmatch(match_str)[2]
if strings.HasPrefix(src, "http") != true {
var buffer bytes.Buffer
buffer.WriteString("http://www.xiaohuar.com")
buffer.WriteString(src)
img_url = buffer.String()
} else {
img_url = src
}
download_img(img_url, name, dir_path)
}
}
func main() {
start := time.Now()
dir := filepath.Dir(os.Args[0])
dir_path := filepath.Join(dir, "images")
err1 := os.MkdirAll(dir_path, os.ModePerm)
check(err1)
for i := 0; i < 4; i++ {
workResultLock.Add(1)
go spider(i, dir_path)
}
workResultLock.Wait()
fmt.Println(time.Now().Sub(start))
}
编译
go build -o go_spider/xiaohua/xiaohua_spider.exe .\go_spider\xiaohua\main.go
运行go文件


下载的图片
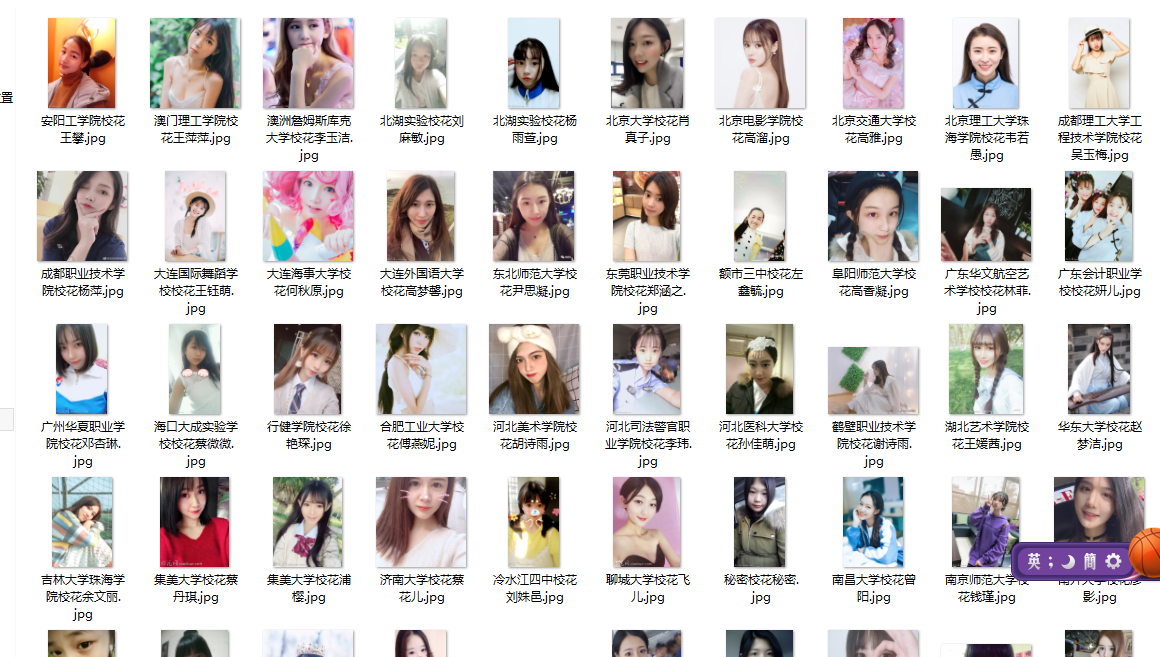
短短14秒钟下载了全部98张图片。看来go的速度就是这么快。
go第一次项目实战,成功!















 792
792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









