







Go并发编程(七)go爬虫小案例

系统流程图

文件下载
// 图片下载
func DownloadImg() {
index := 0
for url := range chanImageString{
ok := DownFile(url,"file_" + strconv.Itoa(index))
if ok{
fmt.Println("下载成功:",url)
}else{
log.Fatal("下载失败:",url)
}
index++
}
}
// 图片下载
func DownFile(url string,fileName string) bool{
resp,err := http.Get(url)
HandleError(err,"http.get url")
defer resp.Body.Close()
bytes,err := ioutil.ReadAll(resp.Body)
HandleError(err,"read body")
// 保存到本地
e := ioutil.WriteFile(fileName,bytes,0666)
return e == nil
}
写文件使用的是io工具类:底层其实也是分为两步
- 打开文件
- 写入字节数据
- 关闭文件
func WriteFile(filename string, data []byte, perm fs.FileMode) error {
return os.WriteFile(filename, data, perm)
}
func WriteFile(name string, data []byte, perm FileMode) error {
// 打开文件
f, err := OpenFile(name, O_WRONLY|O_CREATE|O_TRUNC, perm)
if err != nil {
return err
}
// 写入字节数据
_, err = f.Write(data)
// 关闭文件
if err1 := f.Close(); err1 != nil && err == nil {
err = err1
}
return err
}
ioutil 简单使用
ioutil中封装了很多io操作:

读取文件:例如我要读取当前目录下的test.txt文件:

只需要简单调用下ioutil.ReadFile将返回的字节数组转为字符串即可
// 测试读取文件
func TestReadFile() {
bytes,err := ioutil.ReadFile将返回的字节数组转为字符串即可("test.txt")
if err != nil{
log.Fatal("err:",err)
}
fmt.Println("文件内容为:",string(bytes))
}
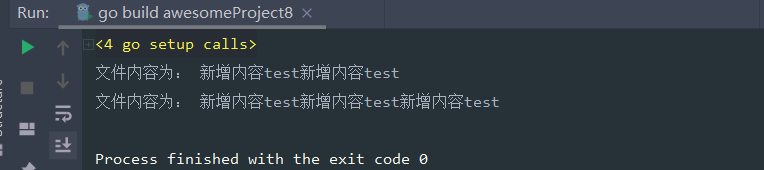
追加写入文件,这里ioutil存在不能追加的问题
// 测试追加写入数据
func TestWriteFile(){
strs := "新增内容test"
// writeFile不能追加写入,解决方案:
bytes,_ := ioutil.ReadFile("test.txt")
ioutil.WriteFile("test.txt", append([]byte(strs), bytes...),os.ModeAppend)
}
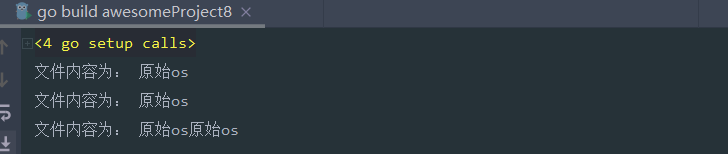
使用原始os包写如下:
func TestReadFileWithOs() {
bytes,err := os.ReadFile("test.txt")
if err != nil{
log.Fatal(err)
}
fmt.Println("文件内容为:",string(bytes))
}
func TestWriteFileWithOs() {
// 读写追加模式打开文件,获取到文件指针
file,_ := os.OpenFile("test.txt",os.O_RDWR |os.O_APPEND,0777)
defer file.Close()
strs := "原始os"
file.Write([]byte(strs))
}
文件夹操作:
func TestCreateDir() {
// 创建临时文件夹
name,err := ioutil.TempDir("D:\\test","*")
if err != nil{
log.Fatal(err)
}
fmt.Println("文件夹名为:",name)
// 读取文件夹
fds,_ := ioutil.ReadDir(name)
fmt.Println("文件夹数量",len(fds))
}
func TestReadDir() {
fds,err := ioutil.ReadDir("D:\\test\\937712527")
if err != nil{
log.Fatal(err)
}
fmt.Println("文件夹数量",len(fds))
for _,fd := range fds{
fmt.Println("是否是文件夹:" ,fd.IsDir())
fmt.Println("文件名:",fd.Name())
fmt.Println("文件大小:",fd.Size())
}
}
爬虫获取图片链接
整体就是将每一页的url传递进来,通过http包获取到网页的html文件响应,在通过正则表达式获取其中的包含.gif,.img,.jpg等类型的字符串
func getImgUrls(url string) {
urls := getImgs(url)
for _,u := range urls{
chanImageString <- u
}
chanTask <- url
wg.Done()
}
// 获取当前页图片链接
func getImgs(url string) (urls []string) {
pageStr := GetPageStr(url)
// 通过正则表达式获取所有的图片链接
re := regexp.MustCompile(reImg)
results := re.FindAllStringSubmatch(pageStr, -1)
fmt.Printf("共找到%d条结果\n", len(results))
for _, result := range results {
url := result[0]
urls = append(urls, url)
}
return
}
// 抽取根据url获取内容
func GetPageStr(url string) (pageStr string) {
resp, err := http.Get(url)
HandleError(err, "http.Get url")
defer resp.Body.Close()
// 2.读取页面内容
pageBytes, err := ioutil.ReadAll(resp.Body)
HandleError(err, "ioutil.ReadAll")
// 字节转字符串
pageStr = string(pageBytes)
return pageStr
}
完整代码
package myspider
import (
"fmt"
"io/ioutil"
"log"
"net/http"
"regexp"
"strconv"
"sync"
)
var(
// 图片链接管道,协程爬取链接后往管道传
chanImageString chan string
// 协程任务监控管道
chanTask chan string
wg sync.WaitGroup
// 正则式
reImg = `https?://[^"]+?(\.((jpg)|(png)|(jpeg)|(gif)|(bmp)))`
)
// 并发爬思路:
// 1.初始化数据管道
// 2.爬虫写出:26个协程向管道中添加图片链接
// 3.任务统计协程:检查26个任务是否都完成,完成则关闭数据管道
// 4.下载协程:从管道里读取链接并下载
func Test() {
// 初始化数据管道
chanTask = make(chan string,26)
chanImageString = make(chan string,1000000)
// 26个爬虫协程爬取26页网页
for i := 1;i < 27;i++{
wg.Add(1)
go getImgUrls("https://www.bizhizu.cn/shouji/tag-%E5%8F%AF%E7%88%B1/" + strconv.Itoa(i) + ".html")
}
// 任务统计协程
wg.Add(1)
go checkOk()
// 下载协程
for i := 0;i < 5;i++{
wg.Add(1)
go DownloadImg()
}
wg.Wait()
}
func DownloadImg() {
index := 0
for url := range chanImageString{
ok := DownFile(url,"file_" + strconv.Itoa(index))
if ok{
fmt.Println("下载成功:",url)
}else{
log.Fatal("下载失败:",url)
}
index++
}
}
func getImgUrls(url string) {
urls := getImgs(url)
for _,u := range urls{
chanImageString <- u
}
chanTask <- url
wg.Done()
}
// 获取当前页图片链接
func getImgs(url string) (urls []string) {
pageStr := GetPageStr(url)
// 通过正则表达式获取所有的图片链接
re := regexp.MustCompile(reImg)
results := re.FindAllStringSubmatch(pageStr, -1)
fmt.Printf("共找到%d条结果\n", len(results))
for _, result := range results {
url := result[0]
urls = append(urls, url)
}
return
}
// 抽取根据url获取内容
func GetPageStr(url string) (pageStr string) {
resp, err := http.Get(url)
HandleError(err, "http.Get url")
defer resp.Body.Close()
// 2.读取页面内容
pageBytes, err := ioutil.ReadAll(resp.Body)
HandleError(err, "ioutil.ReadAll")
// 字节转字符串
pageStr = string(pageBytes)
return pageStr
}
func checkOk() {
count := 0
for {
url := <- chanTask
count++
fmt.Println("完成了爬取任务:",url)
if count == 26{
close(chanImageString)
fmt.Println("爬取完成")
wg.Done()
break
}
}
return
}
// 图片下载
func DownFile(url string,fileName string) bool{
resp,err := http.Get(url)
HandleError(err,"http.get url")
defer resp.Body.Close()
bytes,err := ioutil.ReadAll(resp.Body)
HandleError(err,"read body")
// 保存到本地
e := ioutil.WriteFile(fileName,bytes,0666)
return e == nil
}
// 异常处理
func HandleError(err error,why string) {
if err != nil{
log.Fatal(err)
}
}
结果:

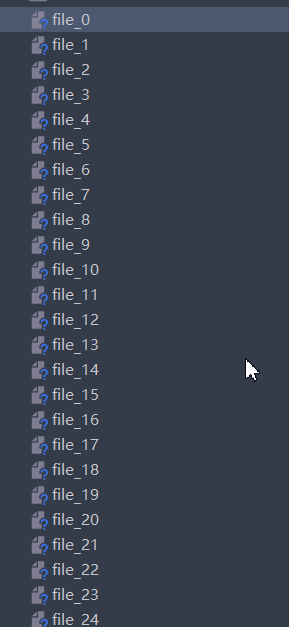















 1264
1264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









