






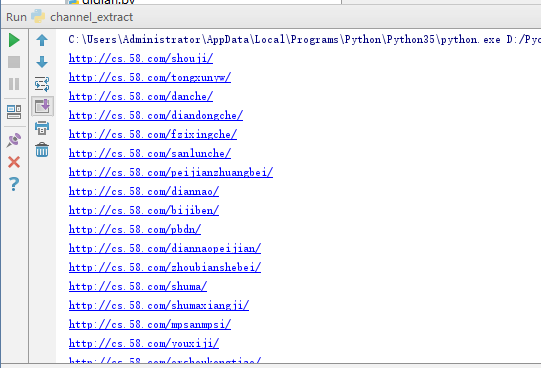
channel_extract.py:
import requests
from lxml import etree
# 请求URL
start_url = 'http://cs.58.com/sale.shtml'
# 拼接的部分URL
url_host = 'http://cs.58.com'
# 获取商品类目URL
def get_channel_urls(url):
html = requests.get(url)
selector = etree.HTML(html.text)
infos = selector.xpath('//div[@class="lbsear"]/div/ul/li')
for info in infos:
class_urls = info.xpath('ul/li/b/a/@href')
for class_url in class_urls:
print(url_host + class_url)
get_channel_urls(start_url)
page_spider.py:
import requests
from lxml import etree
import time
import pymongo
# 连接数据库
client = pymongo.MongoClient('localhost', 27017)
mydb = client['mydb']
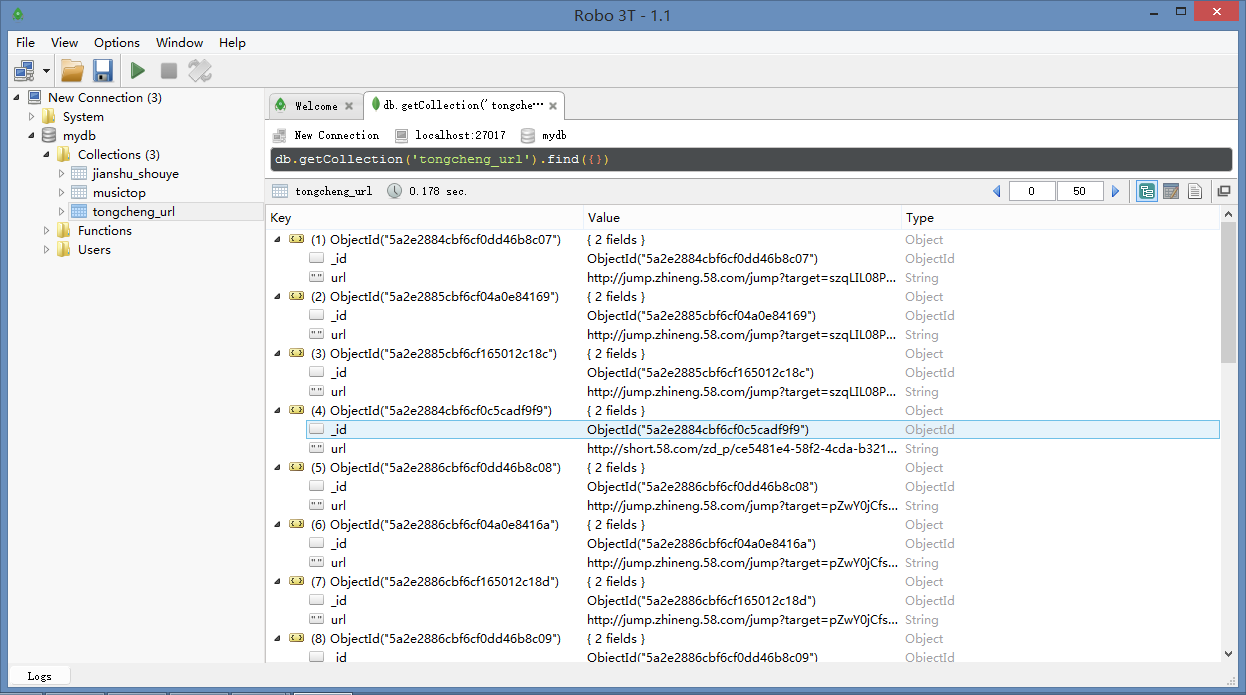
tongcheng_url = mydb['tongcheng_url']
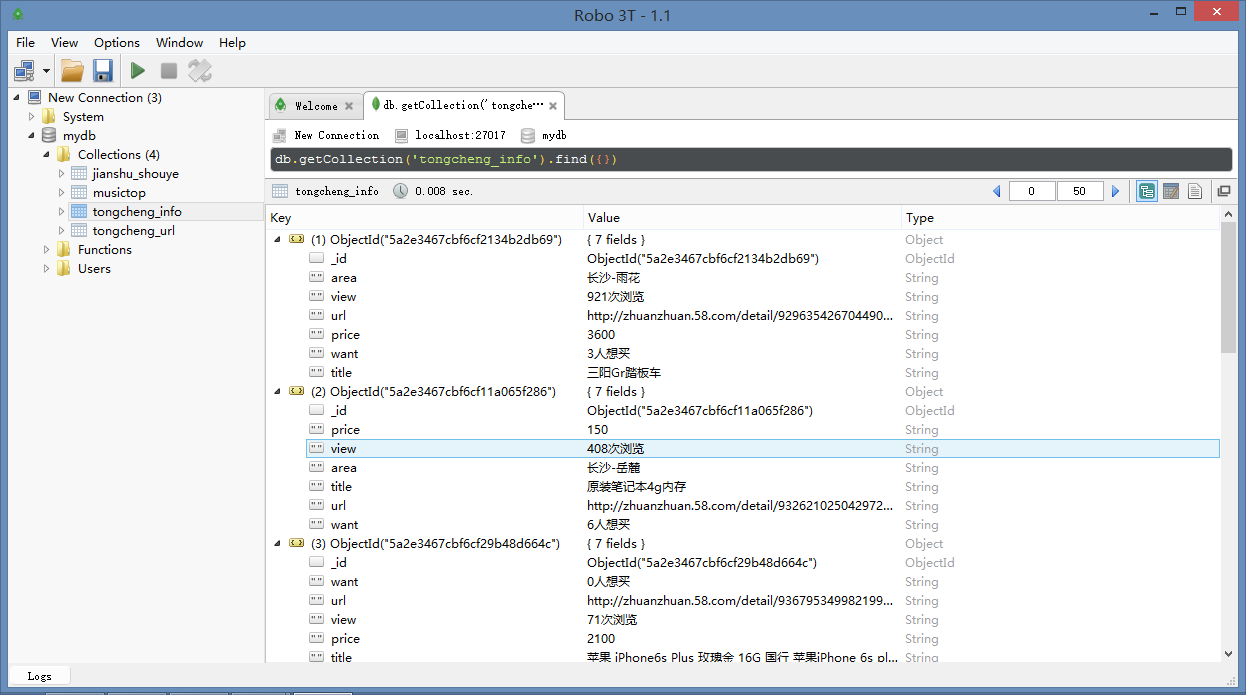
tongcheng_info = mydb['tongcheng_info']
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/53.0.2883.87 Safari/537.36',
'Connection': 'keep-alive'
}
# 定义获取商品URL的函数
def get_links(channel,pages):
list_view = '{}pn{}/'.format(channel,str(pages))
try:
html = requests.get(list_view,headers=headers)
time.sleep(2)
selector = etree.HTML(html.text)
if selector.xpath('//tr'):
infos = selector.xpath('//tr')
for info in infos:
if info.xpath('td[2]/a/@href'):
url = info.xpath('td[2]/a/@href')[0]
tongcheng_url.insert_one({'url':url})
else:
pass
else:
pass
except requests.exceptions.ConnectionError:
pass
# 定义商品详细信息的函数
def get_info(url):
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
try:
title = selector.xpath('//h1/text()')[0]
if selector.xpath('//span[@class="price_now"]/i/text()'):
price = selector.xpath('//span[@class="price_now"]/i/text()')[0]
else:
price = "无"
if selector.xpath('//div[@class="palce_li"]/span/i/text()'):
area = selector.xpath('//div[@class="palce_li"]/span/i/text()')[0]
else:
area = "无"
view = selector.xpath('//p/span[1]/text()')[0]
if selector.xpath('//p/span[2]/text()'):
want = selector.xpath('//p/span[2]/text()') [0]
else:
want = "无"
info = {
'title': title,
'price': price,
'area': area,
'view': view,
'want': want,
'url': url,
}
tongcheng_info.insert_one(info)
except IndexError:
pass
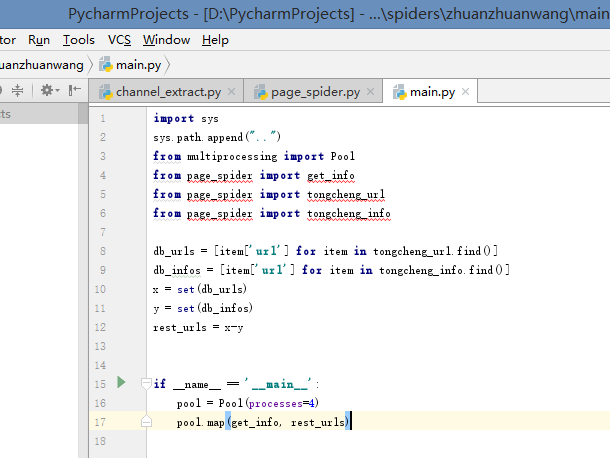
main.py:
import sys
sys.path.append("..")
from multiprocessing import Pool
from channel_extract import channel_list
from page_spider import get_links
# 构造urls
def get_all_links_from(channel):
for num in range(1, 101):
get_links(channel, num)
if __name__ == '__main__':
# 创建进程池
pool = Pool(processes=4)
# 调用进程爬虫
pool.map(get_all_links_from, channel_list.split())















 1789
1789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









