









本文用CNN国际新闻板块的前25条新闻标题,结合道琼斯工业指数进行机器学习,最终预测道琼斯指数的涨跌。预测的实现借助了Keras和Sklearn等Python的机器学习库,具体算法有逻辑回归LR,朴素贝叶斯NB,随机森林RF,梯度推进机GBM,随机梯度下降SGD,朴素贝叶斯支撑向量机NBSVM,多层感知机MLP,LSTM,卷积神经网络CNN这九种算法。
1.数据来源
数据集来自Kaggle网站的数据集:“Daily News for Stock Market Prediction”,链接是:
https://www.kaggle.com/aaron7sun/stocknews
本人在Kaggle网站上的代码链接是:
https://www.kaggle.com/lseiyjg/d/aaron7sun/stocknews/use-news-to-predict-stock-markets/discussion
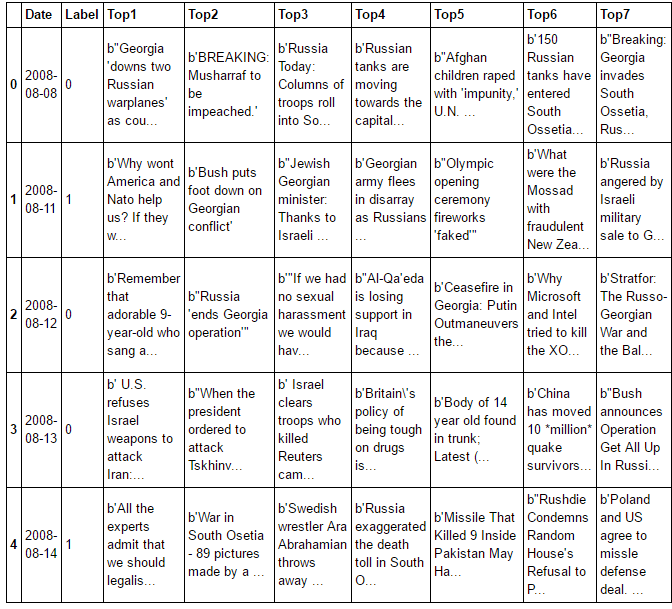
用以预测道琼斯指数的数据集主要分为两个部分,第一个部分的数据是2008年6月至2016年7月每日道琼斯工业指数的涨跌数据,估计是通过爬虫程序在网上收集得到;第二个部分的数据是2008年6月至2016年7月每日CNN国际新闻板块的前25条新闻标题,估计也是通过程序在CNN网上收集得到,具体内容见下图:
实际的数据格式如上,其中Date一栏是日期,Label一栏是指数的涨跌(0代表跌,1代表涨),Top一栏是具体的新闻标题(从Top1至Top25,即前25条新闻)。由于原始数据的数据量巨大,因此图2.1只截取了5日的新闻,标题从Top1至Top7。
从原始数据集可以看出,原始数据并不是能直接进行训练的。首先是原始数据未经过同义词的处理:原始数据有大小写字母,有大量的同义词(如airplane和aeroplane),还有同义词的各种形式(listen和listening)。除此以外,原始数据集还有一些对机器学习无太大意义的部分(例如标题前的b是加粗的格式),一些非字母的符号如$。
2.数据处理
为了方便进行后续的机器学习,原始数据需要通过程序进行预处理。首先,删去无机器学习无太大意义的部分,如字体的格式符号,非字母的符号等。其次,把意义相同的部分统一化,譬如字母都整理为小写字母,同义词进行统一(如aeroplane和airplane都是飞机),同一词的不同形式进行统一(如listen和listening都化为listen),便于后续学习。进行对数据进行初步处理后,去除了大量的无意义部分,统一了大量的同义部分。接下来的步骤中,把处理过的新闻标题拆解成单词序列,统计单词出现的频数,一般来说单词的频数和单词的重要性呈正相关。但是,频数过高的单词很可能是无意义的单词(如“a”,“an”,“the”,“in”,“on”)等,同时频数过低的单词太过生僻,不具有机器学习的意义。因此需要将频数过高或过低的单词悉数滤去,这里滤除95%以上新闻标题都含有的单词,和滤除1%以下新闻标题才含有的单词。
最后,输入数据集可以为一元单词集,即每个单词的频数是一个输入,还有二元、三元等输入形式,需要通过算法来验证选取几元数据集。
这里尝试了机器学习,特别是自然语言处理中一些基础算法和效果较好的算法。具体算法有逻辑回归LR,朴素贝叶斯NB,随机森林RF,梯度推进机GBM,随机梯度下降SGD,朴素贝叶斯支撑向量机NBSVM,多层感知机MLP,LSTM,卷积神经网络CNN这九种算法。
基础算法,如逻辑回归算法和朴素贝叶斯算法,用以作为选取输入数据集元数的验证算法,用来调试选取怎样的输入数据集,是一元单词集、二元单词集、还是三元单词集等等。基础算法同时也作为预测结果的一个基准算法,用以对比其他算法的有效性。
高级算法中,随机森林算法,梯度推进机,随机梯度下降算法,多层感知机,卷积神经网络在各种机器学习问题上的效果都尚可,属于泛用性较广的机器学习的算法;朴素贝叶斯支撑向量机,LSTM,则是在自然语言处理中效果较好的算法,通过这些算法的对比,可以得到应用在本问题上较为优秀的算法。
通过运用逻辑回归算法,测试一元单词集,二元单词集,三元单词集作为输入的效果,来选择合适的输入数据集。2015年以前的数据集作为训练集,2015年以后的数据集作为测试集。输入数据集的元数与准确率的表格见下表:

发现一元单词集作为输入数据集,太过简单,预测准确率不高。二元单词集预测准确率最高,复杂度适中,数据量适中。三元单词集开始预测准确率逐渐下降,可能是因为三元数据集的数据量相对于复杂度不够大。因此选择二元单词集作为输入集,各个输入集相关系数前五和后五的单词分别如下:
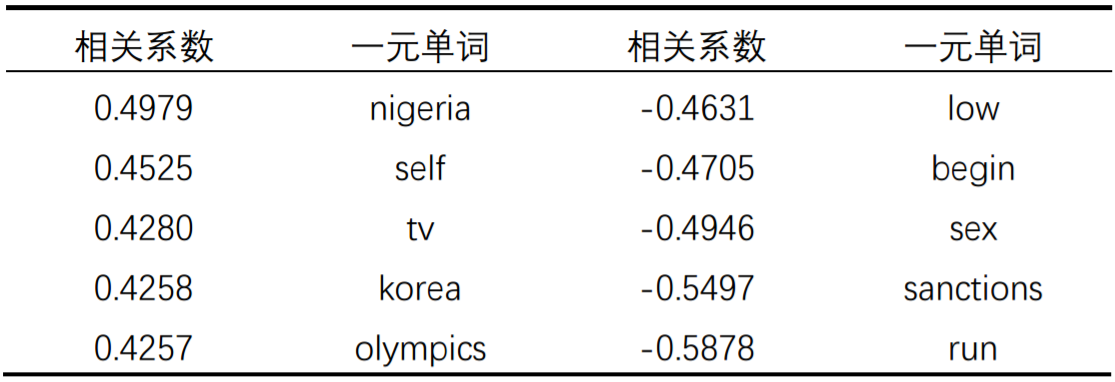
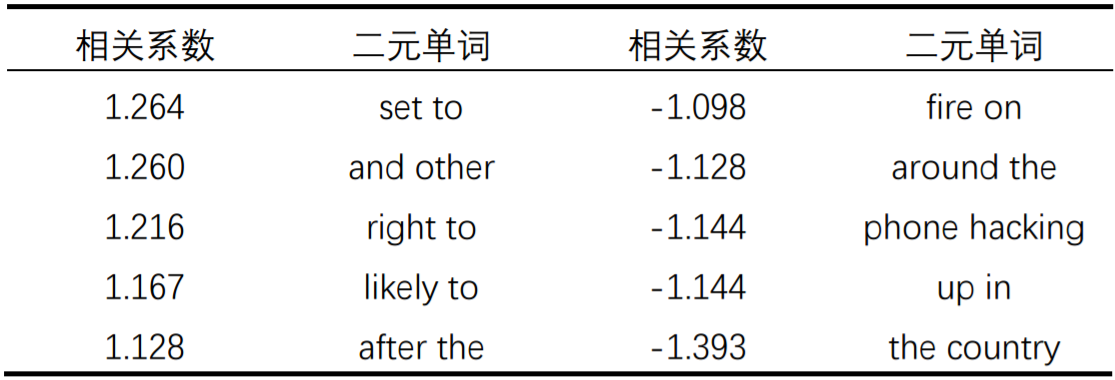

可以看出新闻标题中的“尼日利亚”,“韩国(朝鲜)”,“中国”,“诺贝尔和平奖”正向影响美国经济,新闻标题中的“性”,“电话监听”,“西非”,“世界上”反向影响美国经济。大部分不具有意义的常见单词,如“a”,“the”等被滤除,数据可以使用于机器学习。
3.算法结果
选取输入数据集为二元单词集,2015年以前的数据集作为训练集,2015年以后的数据集作为测试集,分别应用逻辑回归LR,朴素贝叶斯NB,随机森林RF,梯度推进机GBM,随机梯度下降SGD,朴素贝叶斯支撑向量机NBSVM,多层感知机MLP,LSTM,卷积神经网络CNN这九种算法。各个算法的准确率如下:
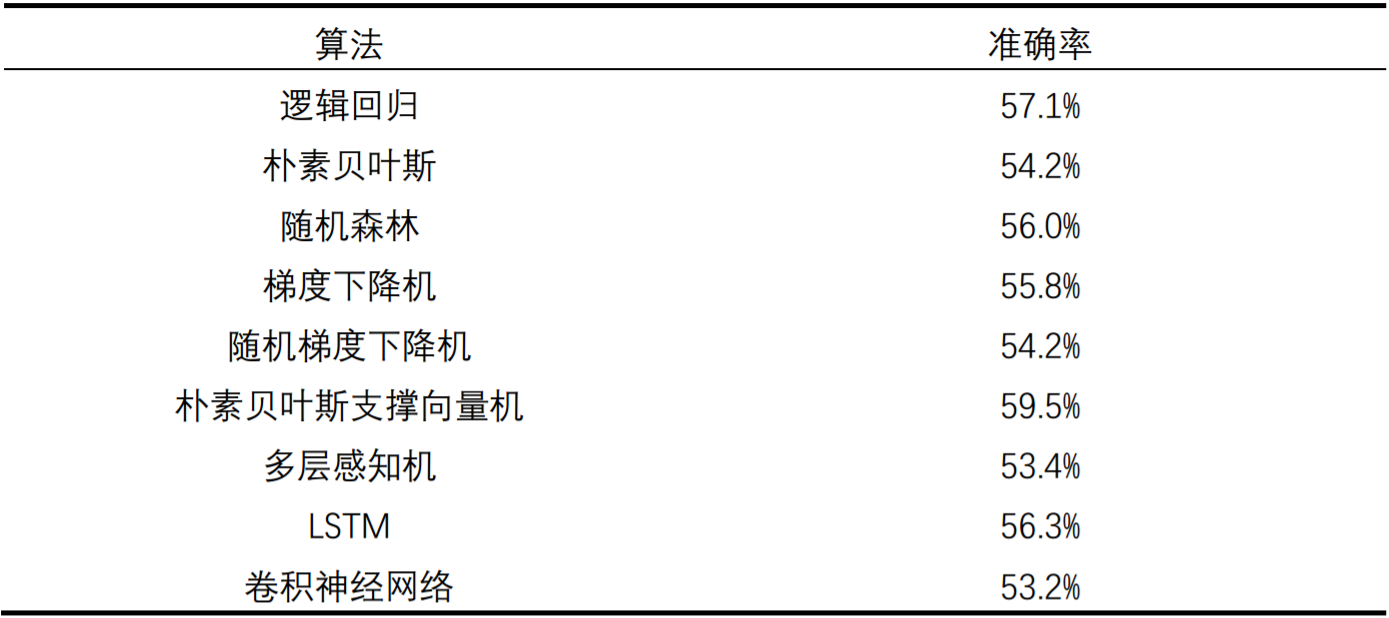
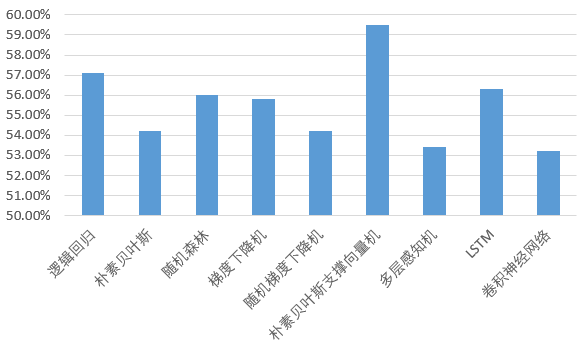
可以看出朴素贝叶斯支撑向量机(NBSVM)的效果最好。其他的均低于逻辑回归算法。
预想中最好的算法应该是处理自然语言最佳的的朴素贝叶斯算法和LSTM算法,其中朴素贝叶斯支撑向量机用于垃圾邮件分类,LSTM用于语义识别。这里LSTM算法未能超过逻辑回归可能是因为新闻标题的性质是短小精悍的,而LSTM具有记忆性,适合运用于大段的语义识别,因此在这个问题上未能表现得特别突出。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









