






# Mail编程
## 电子邮件的历史
- 起源
- 1969 Leonard K. 教授发给同事的"LO"
- 1971 美国国防部自主的阿帕网(Arpanet)的通讯机制
- 通讯地址里用@
- 1987年中国的第一封电子邮件
"Across the Great Wall we can reach every corner in the world"
- 管理程序
- Euroda使邮件普及
- Netscape,outlook,forxmail后来居上
- Hotmail使用浏览器发送邮件
## 邮件工作流程
- MUA(MailUserAgent):邮件用户代理
- MTA(MailTransferAgent):邮件传输代理
- MDA(MailDeliveryAgent):邮件投递代理
案例流程:
- laoshi@qq.com:老师在北京海淀
- xuesheng@sina.com:学生在上海静安
流程:
1、MUA-MTA,邮件从用户代理发出,发到邮件传输代理,也就是服务器上
2、qq MTA->......->sina MTA,此时邮件从qq的服务器上发到新浪的服务器上
3、sina MTA-> sina MDA,此时邮件从新浪服务器上,发到你个人的新浪邮箱里
4、sina MDA -> sina MUA(forxmail/Outlook),用管理程序的邮箱软件从个人邮箱把邮件下载到本地电脑
- 编写程序
- 发送:MUA->MTA with SMTP:SimpleMailTransferProtocal,包含MTA-MTA
- 接受:MDA->MUA with POP3 and IMAP:PostOfficeProtocal v3 and InternetMessageAccessProtocal
- 准备工作
- 注册邮箱(以qq邮箱为例)
- 第三方邮箱需要特殊设置,以qq邮箱为例
- 进入设置中心
- 取得授权码
- Python for mail
- SMTP协议负责发送邮件
1、使用email模块构建邮件
- 纯文本邮件,案例v07.py
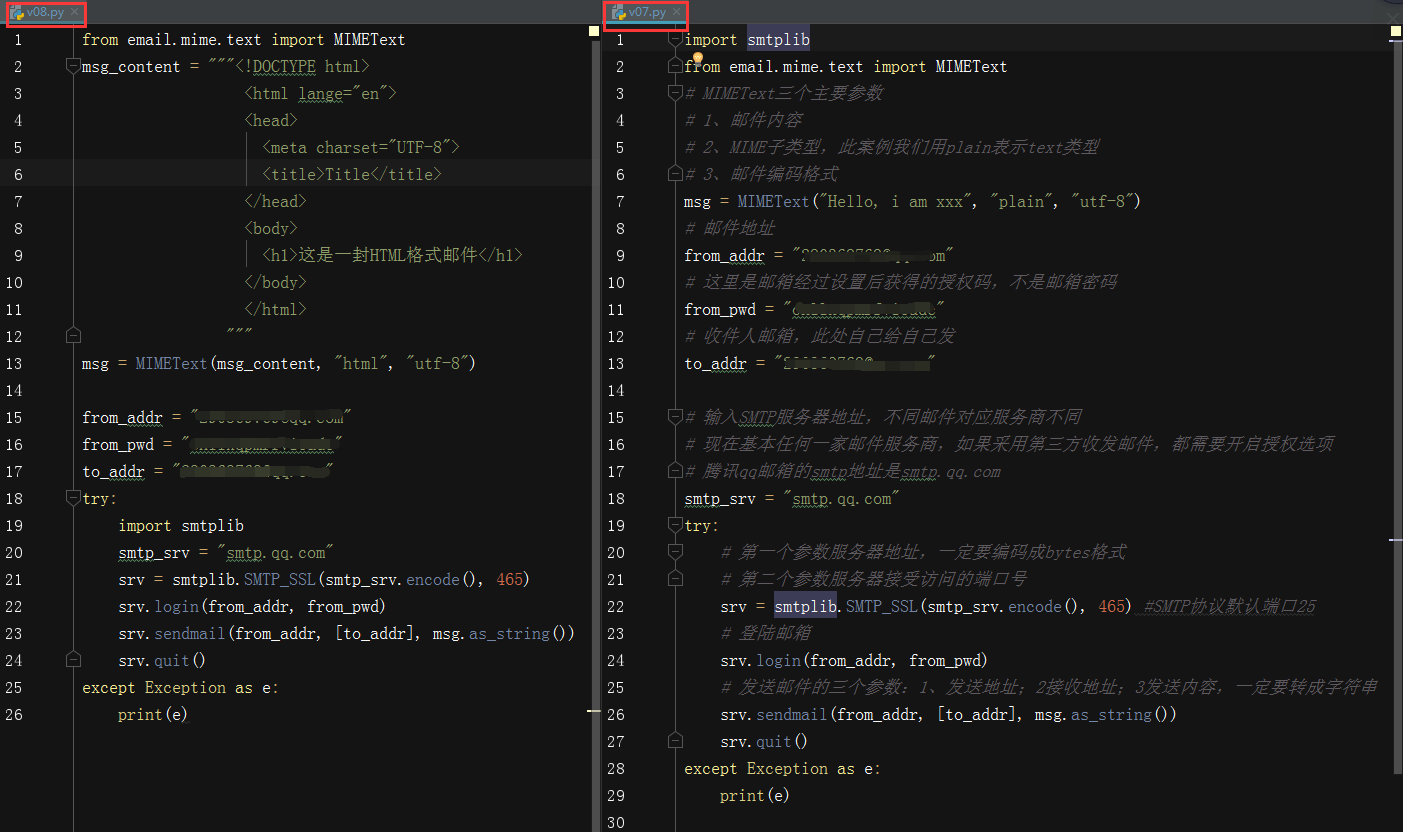
- HTML格式邮件发送
1、准备HTML代码作为内容
2、把邮件的subtype设为html
3、发送
案例v08.py
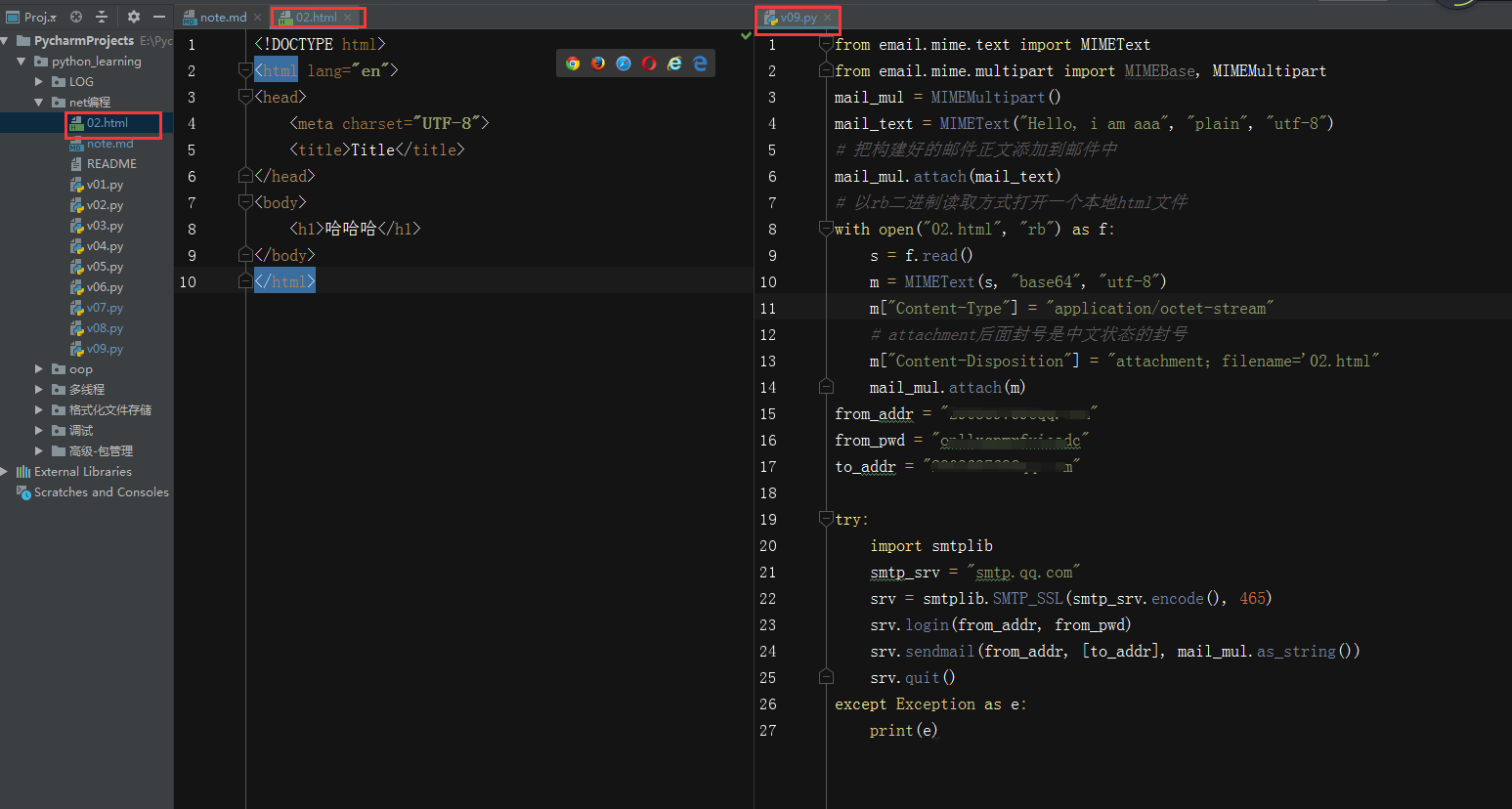
- 发送带附件的邮件
- 可以把邮件看成是一个文本邮件和一个附件的合体
- 一封邮件如果涉及多个部分,需要使用MIMEMultipart格式构建
- 添加一个MIMEText正文
- 添加一个MIMEBase或者MIMEText作为附件
案例v09.py
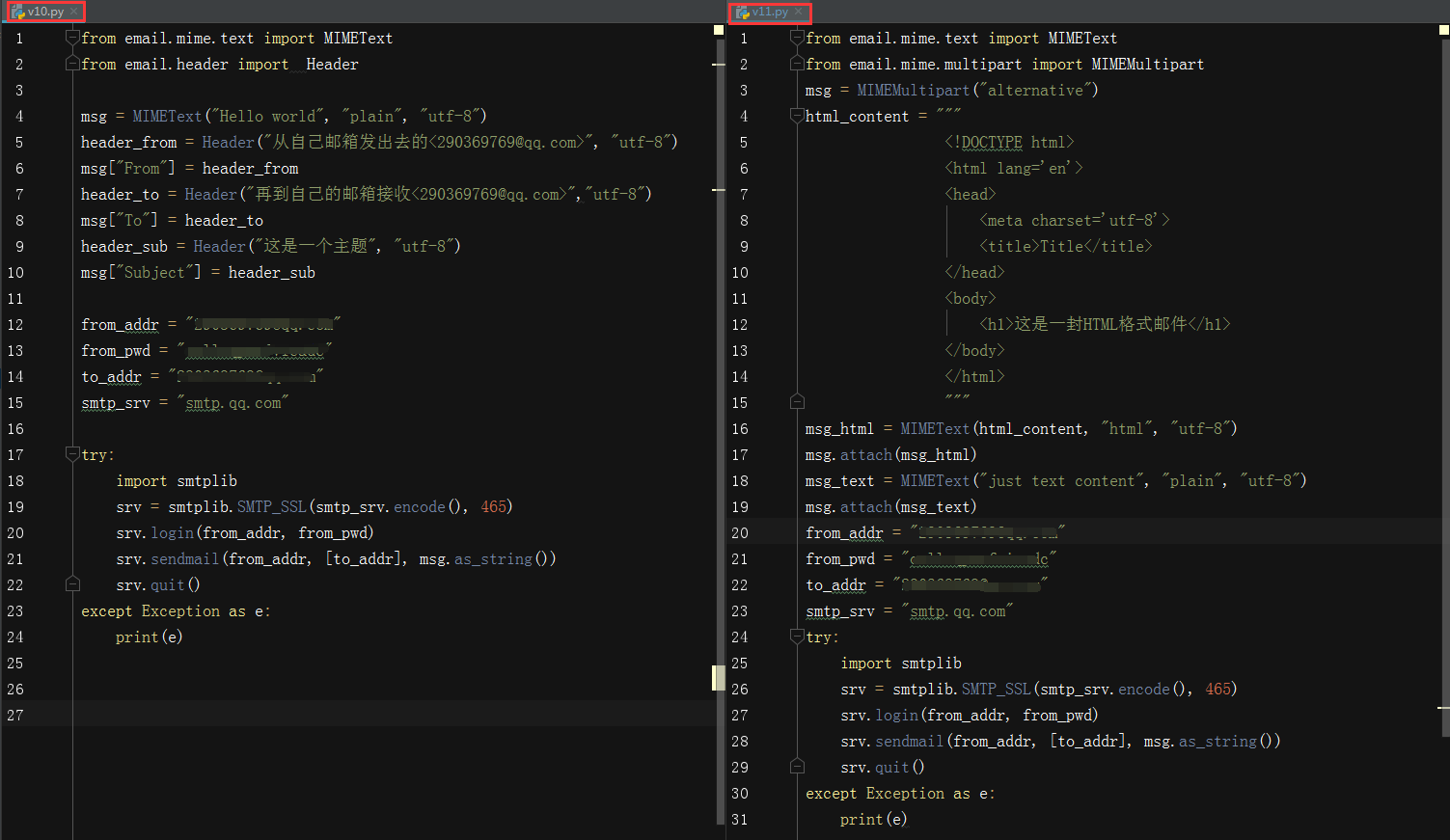
- 添加邮件头(摘要),抄送等信息
- mail["From"]:表示邮件发送者信息,包括姓名和邮件地址
- mail["To"]:表示接收者信息,包括姓名和邮件地址
- mail["Subject"]:表示摘要或者主题信息
案例v10.py
- 同时支持html和text格式
- 构建一个MIMEMultipart格式邮件
- MIMEMultipart的subtype设置成alternative格式
- 添加html和text邮件
案例v11.py
2、使用smtplib模块发送邮件
- POP3协议接收邮件
- 本质上是从MDA-MUA的一个过程
- 从MDA下载下来的是一个完整的邮件结构体,需要解析才能得到每个具体内容
- 步骤:
一、 用poplib下载邮件结构体原始内容步骤:
1、准备相应的内容(邮件地址,密码,POP3实例)
2、身份认证
3、一般会先得到邮箱内邮件的整体列表
4、根据相应序号,得到某一封信的数据流
5、利用解析函数进行解析出相应的邮件结构体
二、用email解析邮件的具体内容
案例v12.py
# v12.py
# poplib负责邮件从MDA->MUA的瞎子啊 import poplib # 以下包负责邮件结构的解析 from email.parser import Parser from email.header import decode_header from email.utils import parseaddr # 得到邮件的原始内容 def getMsg(): email = "290369769@qq.com" pwd = "onllxqpmrfvicadc" pop3_srv = "pop.qq.com" # 端口995 # SSL代表安全通道 srv = poplib.POP3_SSL(pop3_srv) # user代表email地址 srv.user(email) # pass_代表密码 srv.pass_(pwd) # stat返回邮件数量和占用空间,注意stat返回一个tuple格式 msgs, counts = srv.stat() print("Messages:{0}, Size:{1}".format(msgs, counts)) # list返回所有邮件编号列表 # mails是所有邮件编号列表 rsp, mails, octets = srv.list() # 可以看到返回的mails列表类似[b'1 82923', b'2 2184'] print(mails) # 获得最新一封邮件,注意邮件索引是从1开始,最新代表索引号最高 index = len(mails) # retr负责返回一个具体索引号的一封信的内容,此内容不具有可读性 # lines存储邮件的最原始文本的每一行 rsp, lines, octets = srv.retr(index) # 获得整个邮件的原始文本 msg_count = b'\r\n'.join(lines).decode("utf-8") # 解析出邮件整个结构体,参数是解码后的邮件整体 msg = Parser().parsestr(msg_count) srv.quit() return msg # 详细解析得到的邮件内容 # msg代表邮件原始内容 # indent带便邮件嵌套的层级 def parseMsg(msg, indent=0): if indent == 0: for header in ["From", "To", "Subject"]: # 使用get可以避免如果没有相关关键字报错的可能性 # 如果没有关键字"From",我们使用msg["From"]会报错 value = msg.get(header, '') if value: # Subject中的内容直接解码就可以,它是字符串类型 if header == "Subject": value = decodeStr(value) else: hdr, addr = parseaddr(value) name = decodeStr(hdr) value = "{0}<{1}".format(name, addr) print("{0}, {1}, {2}".format(indent, header, value)) # 下面代码关注邮件内容本身 # 邮件内容,可能是multipart类型,也可能是普通邮件类型 # 下面的解析使用递归方式 if(msg.is_multipart()): # 得到多部分邮件的一个基础部分邮件 parts = msg.get_payload() # enumerate是内置函数,作用是将一个列表,此处指parts,生成一个有索引和parts原内容一一对应的tuple组成的新列表 # 例如enumerate(['a', 'b']) 结果是[(1, 'a'), (2, 'b')] for n,part in enumerate(parts): print("{0}spart:{1}".format(' '*indent, n)) parseMsg(part, indent+1) else: # get_content_type是系统提供的函数,得到内容类型 content_type = msg.get_content_type() # text/plain或者text/html是固定值 if content_type == "text/plain" or content_type =="text/html": content = msg.get_payload(decode=True) charset = guessCharset(msg) if charset: content = content.decode(charset) print("{0}Text:{1}".format(indent, content)) def decodeStr(s): ''' s代表邮件中From, To, Subject中的任一项 对s进行解码,解码是编码的逆过程 :param s: :return: ''' value, charset = decode_header(s)[0] # charset字符编码有可能为空 if charset: value = value.decode(charset) return charset def guessCharset(msg): ''' 猜测邮件的编码格式 :param msg: :return: ''' charset = msg.get_charset() if charset is None: content_type = msg.get("Content-Type","").lower() pos = content_type.find("charset=") if pos >= 0: # 如果包含charset,则内容形如charset=xxx charset = content_type[pos+8].strip() return charset if __name__ == '__main__': msg = getMsg() print(msg) parseMsg(msg, 0)















 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









