







onenote中只能设置中文字体,英文字体只能用默认的“Calibri”,中英文和数字混排时,效果极差,极其烦人。是否有办法同时或分别设置onenote中、英文字体呢?办法是有的。
中文字体的设置在文件–>选项中,设置较为方便。
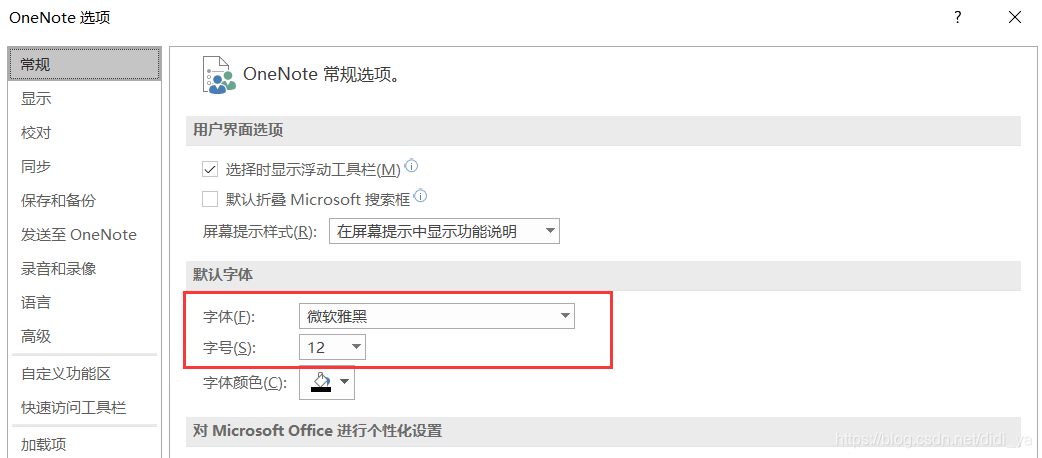
个人比较喜欢微软雅黑的中文字体,所以希望默认的中文字体为雅黑。这就导致了一个问题,相同字号下 Calibri 字体的英文字母显示很大,在和雅黑的中文混杂在一起的时候,就很难看,简直逼死强迫症。比如说这样:
解决思路
首先下载安装Onetastic,
相关链接:
https://download.csdn.net/download/didi_ya/12657449
或https://getonetastic.com/
下载完成后,然后可以使用别人做好的宏,
如图
打开下载宏,
然后找到字体修正的宏安装即可。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7292
7292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











