







一、数据立方体的基本概念
数据立方体是多维数据库的基本结构,并作为在多维数据库上定义的所有操作符的输入输出基本单位。将它定义为一个四元组<D,M,A,f>,这四个组件分别表示数据立方体的特征:
1. n 个维的集合D={d1 ,d2,。。。 ,dn },其中每个di 为从维域中抽取的维名。
2. K 个度量的集合M={ m1 ,m2,。。。 ,mn },其中每个mi 为从度量域中抽取的度量名。
3. 维名集合与度量名集合是不相交的,即D∩M=。
4. t 个属性的集合A={a1, a2,。。。at},其中每个ai 为从维域中抽取的属性名。
5. 一对多映射f:D→A,即每个维存在一个对应的属性集合。与不同维对应的属性集互不相交,即对所有i,j,i不等于j,f(di)∩f(dj)= 空。
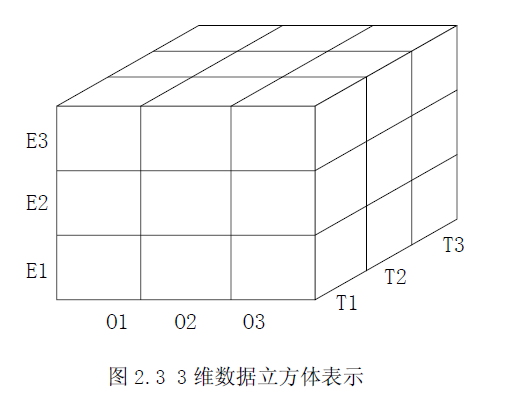
在典型的OLAP 应用中,存在一个中心关系或数据集合,称作事实表。事实表代表感兴趣的事件或对象。事实表通常有几个表示维的属性和一个或多个度量属性,这些度量属性一般是用户想要查询到的一些值。下面给出例子来说明数据立方体的定义。表2.1 是一个数据库中表示文件元数据的基本关系表Files,Owner、Type、Etime、Size 分别表示文件的所有者、类型、创建时间、大小,单位KB。

Files 关系:Files(Owner,Type,Etime,Size)是个事实表。维Owner、Type、Etime用来定义分类,Size 是度量属性,它是向这个数据库所提出的聚集查询所需要的,用它来进行一定的分析。
现在用与基本关系表Files 相对应的元数据立方体来表示存储系统中文件元数据的多维数据库。元数据立方体具有如下的特征:
(1) 用户关心是的文件大小这个度量,对于元数据立方体来说,M={文件大小}。
(2) 用户习惯于用三维来分析文件,即文件所有者、类型、创建时间,也就是说用户经常会提出这样的问题,“用户O1 在上周创建的文件的总大小是多少?”(用文件所有者和创建时间维询问),或“在一定时间内,用户O2 所创建的文本文件的总大小是多少?”(用全部三个维询问)。于是对元数据立方体来说,D={文件所
有者,文件类型,创建时间}。
(3)创建时间维是用属性日、月和年来描述的;文件所有者维是用john、xiaoguo、yy 来描述的;文件类型维是用doc、exe、txt 等来描述的。于是,对元数据立方体而言,A={john,xiaoguo,yy,doc,exe,txt,日,月,年}。
(4)在前面解释的每一个维都用特定的属性来描述,对元数据立方体而言,映射f 为:
f(文件所有者) = { john,xiaoguo,yy }
f(文件类型) = {doc、exe、txt}
f(创建时间) = {日,月,年}
可以注意到上面的三个属性集合是互不相交的,因此元数据立方体满足上述定义,如图所示:
二、数据立方体的计算
数据立方体的全部或部分预计算可以大幅降低响应时间,提高查询效率,提高联机分析处理性能[18]。数据立方体的物化有三种策略:
1. 预先计算任何方体,即完全立方体物化(Full Materialization)[19]。一个n 维的数据立方体,有2n 种组合(Group by),即有2n 个方体。因此完全立方体物化就是聚集度量M 对n 个维的所有可能组合计算。完全物化优点:可以对提出的任何查询快速响应,快速返回预计算好的结果,不用在线等待计算结果,提高交互性。缺点:完全物化时间复杂度是维度的指数,随着维度的增大,将发生“维灾”。计算代价非常大,而且消耗大量的存储空间和系统资源,同时当它的数据源发生改变时,为了保持数据的一致性,需要重新的计算所有的方体。当立方体的维度比较高时,对完全物化策略的立方体进行更新维护将耗费大量的时间和系统资源。完全物化主要有多路数组聚集方法。
2. 不预先计算任何的方体(不物化,No Materialization),数据立方体中每一个方体都不对聚集度量M 进行预计算,相当于只提供一个多维的索引,这样对于用户提交的查询,需要在线计算结果,响应时间较长。当总的数据量很大时,那查询的结果集也会很大,在线计算将需要很长的时间,从而导致无法忍受的响应时间,在海量数据情况下,该策略是不可取的。
3. 部分物化(Partial Materialization)提供了存储空间和响应时间的有效折衷。替代计算完全立方体,我们可以计算立方体的一个子集,或计算由各种方体的单元组成的子立方体。优点是节省了大量的计算时间和存储空间;缺点是只能命中大部分查询而且结果可能不太精确, 对于没命中的查询需要在线计算( onlinecomputation)。
完全立方体的每个单元记录一个聚集值,通常使用诸如count、sum 等度量。对于方体中的许多单元,度量值将为0。当相对于存放在该方体中的非零值元组的数量,方体维的基数的乘积很大时,那么该方体是稀疏的。如果一个立方体包含许多稀疏方体,则称该立方体是稀疏的。
在许多情况下,相当多的立方体空间可能被大量具有很低度量值的单元占据。这是因为立方体单元在多维空间中的分布常常是相当稀疏的。例如,某一类型的文件非常少,这样的事件将产生少量非空单元,使得其他大部分立方体单元为空。在这种情况下仅物化其度量值大于某个最小阈值的方体(Group by)单元是很有用的。比如说,在上面Files 对就应的元数据立方体中,我们可能只希望物化其Size 100KB,这不仅能够节省计算时间和空间,而且能够导致更聚集的分析。对于未来的分析,不能够满足阈值的单元多半是微不足道的。这种部分物化的单元称作冰山立方体(Iceberg Cube)[20,21,22],最小阈值称作最小支持度阈值或简称最小支持度(min_sup)。
实际上,决策者或管理者可能对许多方体的单元不太感兴趣或不感兴趣。例如,“某个文件夹下文件的总大小是多少?”这样的话文件小于100KB 的就可以不予考虑,这样可以大大减少计算时间,节省空间,但又不影响分析和做出决策。
前面的一篇文章——数据仓库的多维数据模型中已经简单介绍过多维模型的定义和结构,以及事实表(Fact Table)和维表(Dimension Table)的概念。多维数据模型作为一种新的逻辑模型赋予了数据新的组织和存储形式,而真正体现其在分析上的优势还需要基于模型的有效的操作和处理,也就是OLAP(On-line Analytical Processing,联机分析处理)。
数据立方体
关于数据立方体(Data Cube),这里必须注意的是数据立方体只是多维模型的一个形象的说法。立方体其本身只有三维,但多维模型不仅限于三维模型,可以组合更多的维度,但一方面是出于更方便地解释和描述,同时也是给思维成像和想象的空间;另一方面是为了与传统关系型数据库的二维表区别开来,于是就有了数据立方体的叫法。所以本文中也是引用立方体,也就是把多维模型以三维的方式为代表进行展现和描述,其实上Google图片搜索“OLAP”会有一大堆的数据立方体图片,这里我自己画了一个:

OLAP
OLAP(On-line Analytical Processing,联机分析处理)是在基于数据仓库多维模型的基础上实现的面向分析的各类操作的集合。可以比较下其与传统的OLTP(On-line Transaction Processing,联机事务处理)的区别来看一下它的特点:
OLAP与OLTP
| 数据处理类型 | OLTP | OLAP |
| 面向对象 | 业务开发人员 | 分析决策人员 |
| 功能实现 | 日常事务处理 | 面向分析决策 |
| 数据模型 | 关系模型 | 多维模型 |
| 数据量 | 几条或几十条记录 | 百万千万条记录 |
| 操作类型 | 查询、插入、更新、删除 | 查询为主 |
OLAP的类型
首先要声明的是这里介绍的有关多维数据模型和OLAP的内容基本都是基于ROLAP,因为其他几种类型极少接触,而且相关的资料也不多。
MOLAP(Multidimensional)
即基于多维数组的存储模型,也是最原始的OLAP,但需要对数据进行预处理才能形成多维结构。
ROLAP(Relational)
比较常见的OLAP类型,这里介绍和讨论的也基本都是ROLAP类型,可以从多维数据模型的那篇文章的图中看到,其实ROLAP是完全基于关系模型进行存放的,只是它根据分析的需要对模型的结构和组织形式进行的优化,更利于OLAP。
HOLAP(Hybrid)
介于MOLAP和ROLAP的类型,我的理解是细节的数据以ROLAP的形式存放,更加方便灵活,而高度聚合的数据以MOLAP的形式展现,更适合于高效的分析处理。
另外还有WOLAP(Web-based OLAP)、DOLAP(Desktop OLAP)、RTOLAP(Real-Time OLAP),具体可以参开维基百科上的解释——OLAP。
OLAP的基本操作
我们已经知道OLAP的操作是以查询——也就是数据库的SELECT操作为主,但是查询可以很复杂,比如基于关系数据库的查询可以多表关联,可以使用COUNT、SUM、AVG等聚合函数。OLAP正是基于多维模型定义了一些常见的面向分析的操作类型是这些操作显得更加直观。
OLAP的多维分析操作包括:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot),下面还是以上面的数据立方体为例来逐一解释下:

钻取(Drill-down):在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对2010年第二季度的总销售数据进行钻取来查看2010年第二季度4、5、6每个月的消费数据,如上图;当然也可以钻取浙江省来查看杭州市、宁波市、温州市……这些城市的销售数据。
上卷(Roll-up):钻取的逆操作,即从细粒度数据向高层的聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据,如上图。
切片(Slice):选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者2010年第二季度的数据。
切块(Dice):选择维中特定区间的数据或者某批特定值进行分析,比如选择2010年第一季度到2010年第二季度的销售数据,或者是电子产品和日用品的销售数据。
旋转(Pivot):即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
OLAP的优势
首先必须说的是,OLAP的优势是基于数据仓库面向主题、集成的、保留历史及不可变更的数据存储,以及多维模型多视角多层次的数据组织形式,如果脱离的这两点,OLAP将不复存在,也就没有优势可言。
数据展现方式
基于多维模型的数据组织让数据的展示更加直观,它就像是我们平常看待各种事物的方式,可以从多个角度多个层面去发现事物的不同特性,而OLAP正是将这种寻常的思维模型应用到了数据分析上。
查询效率
多维模型的建立是基于对OLAP操作的优化基础上的,比如基于各个维的索引、对于一些常用查询所建的视图等,这些优化使得对百万千万甚至上亿数量级的运算变得得心应手。
分析的灵活性
我们知道多维数据模型可以从不同的角度和层面来观察数据,同时可以用上面介绍的各类OLAP操作对数据进行聚合、细分和选取,这样提高了分析的灵活性,可以从不同角度不同层面对数据进行细分和汇总,满足不同分析的需求。
是不是觉得其实OLAP并没有想象中的那么复杂,一旦多维数据模型建成后,在上面做OLAP其实是一件很cool的事情。 















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









