






这周花了一周的时间批量修改的相应的xml配置文件,并对批量的url进行测试。现在来分享一下心得吧!
需求大概是这样的,有个参数需要加一个过滤器,过滤掉相应的参数, 过滤器是读取xml里面配置并解析,并对xml里面的参数进行filter。
过滤器就是在web.xml里面的filter节点配置,然后自己在类里面作自定义方法处理。
这些暂时不说,方法皆可百度和google。
主要是批处理 以及 网络请求测试python
一、批处理可以用bat指令和 java,dos命令因为不太懂,也不太用,所以选择java(不过感觉bat不需要依赖环境,方便文件发给测试并测试)
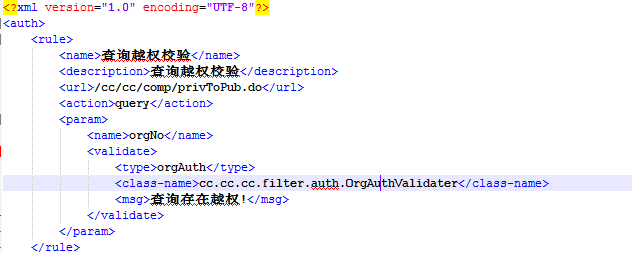
xml文件:
java文件:
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import org.jdom.*;
import org.jdom.input.SAXBuilder;
/**
* 读取xml文件
*
*/
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
List<String> cList = new ArrayList<String>();
try {
String directory="C://Users//aaa/Desktop/conf/cc-conf";/*存储xml文件的文件夹*/
String fileSuffix = ".xml"; /*读取后缀为xml的文件*/
File file = new File(directory);
File[] filelist = file.listFiles();/*获取文件夹下的xml文件列表*/
for(int i=0;i<filelist.length;i++){
if(filelist[i].getName().lastIndexOf(fileSuffix)!=-1){
String filename = filelist[i].getName();/*获取每个xml文件的文件名*/
// System.out.println(filename);
SAXBuilder sb=new SAXBuilder();
Document doc = sb.build(directory+"/"+filename);
Element root=doc.getRootElement(); //获取根元素
List list=root.getChildren("rule");//取名字为disk的所有元素
for(int j=0;j<list.size();j++){
Element ele = (Element)list.get(j);
SetElement con = new SetElement();
con.setName(ele.getChildText("name"));
con.setDescription(ele.getChildText("description"));
con.setUrl(ele.getChildText("url"));
con.setAction(ele.getChildText("action"));
//cList.add(ele.getChildText("description") + ":");
cList.add("http://11111.11.111.11:11/web"+ele.getChildText("url") + "?action=" + ele.getChildText("action")+"&"+ele.getChild("param").getChildText("name") +"=3440101");
}
}
}
} catch (
Exception e) {
e.printStackTrace();
}
for(String c :cList){
System.out.println(c);
}
}
}
输出相应的url ,复制到url.txt
二、接下来批量测试 url
把前面的url.txt放在相应的文件路径,然后把cookie的name/value以;切分的形式 放在cookie.txt里面。

然后写python文件读取url.txt 和cookie.txt。
import time
import requests
f=open(r'cookie.txt','r')#打开所保存的cookies内容文件
cookies={}#初始化cookies字典变量
for line in f.read().split(';'): #按照字符:进行划分读取
#其设置为1就会把字符串拆分成2份
name,value=line.strip().split('=',1)
print('cookie:'+value)
cookies[name]=value #为字典cookies添加内容
file = open('ykext02.txt')
lines = file.readlines()
aa=[]
for line in lines:
temp=line.replace('\n','')
aa.append(temp)
print(aa)
def get_status(url):
r = requests.get(url, cookies=cookies)
return r.status_code
print('开始检查:')
for a in aa:
tempUrl = a
response = requests.get(tempUrl)
status=get_status(tempUrl)
if str(status) == '200':
print('状态码:'+str(status)+" "+tempUrl)
time.sleep(0.1)
同时输出没有生效(http状态码为200)的url。
这样就成功了!















 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









