






第五课、python中可变类型的数据集合
一、课程介绍
课时介绍
- 列表简单介绍
- 列表常用操作
- 列表的应用
- 字典的简单介绍
- 字典的基本操作
- 字典的应用
课程目标
- 掌握列表的特性与使用方法
- 掌握字典的特性与使用方法
二、列表的介绍与基本操作(最重要的数据类型一定要掌握好)
2-1 列表介绍与创建
数据结构
- 数据结构就是指从计算机存储、组织数据的结构
- 常用的数据结构
- 列表(List)
- 元组(Tuple)
- 字典(Dictionary)
- 集合(Set)
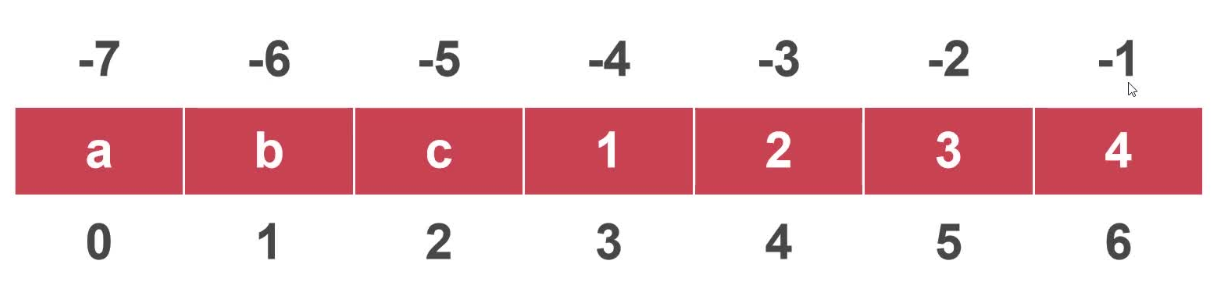
列表(List)的特点
- 列表中的数据按顺序排列
- 列表有正序与倒序两种索引
- 列表可存储任意类型数据,且允许重复
正序索引 n-1 倒叙索引 -n
1 list = ['a' , 'b' , 'c' , 'd' , 1 , 2 , 3 , 4] 2 print(list) 3 list1 = [] 4 print(list1)
2-2 列表的取值
1 #列表的取值 2 list = ['张三' , '李四' , '王五' , '赵六' , '钱七' , '孙八'] 3 print(list) 4 #取值的语法:变量 = 列表变量[索引值] 5 zhaoliu =list[3] 6 print(zhaoliu) 7 zhaoliu=list[-3] 8 print(zhaoliu) 9 #范围取值:列表变量=原列表变量[起始索引:结束索引] 10 #在python中列表范围取值是“左闭右开” 11 list1 = list[1:4] 12 print(list1) 13 print(list1[-1]) 14 #列表的index函数用于获取指定元素的索引值 15 zhaoliu_index = list.index('赵六') 16 print(zhaoliu_index)
2-3 遍历列表(for循环)
for..in语句
- for..in语句专门用于遍历列表、元组等数据结构
- for迭代变量in可迭代对象
- 循环体(必须缩进)
1 #遍历列表 2 persons = ['张三' ,'赵六' , '李四' , '王五' , '赵六' , '钱七' , '孙八'] 3 count=len(persons)#获取列表长度 4 print(count) 5 #for循环用于遍历列表 6 #for 迭代变量 in 可迭代对象 7 i = 0 8 for a in persons: 9 if a == '赵六': 10 ri = count * -1 + i 11 print(a, i, ri) 12 i += 1 13 14 i=0 15 while i < len(persons): 16 p = persons[i] 17 if p =='赵六': 18 ri=count * -1 + i 19 print(p , i , ri) 20 i += 1
2-4 列表的反转与排序
- reverse方法用于反转列表
-
sort()用于排序,reverse=True代表降序排列
1 #列表的反转与排序 2 persons = ['张三' ,'赵六' , '李四' , '王五' , '赵六' , '钱七' , '孙八'] 3 persons.reverse()#reverse方法用于反转列表 4 print(persons) 5 6 numbers = [28, 32, 14, 12, 53, 42] 7 numbers.sort() 8 print(numbers) 9 numbers.sort(reverse = True)#sort()用于排序,reverse=True代表降序排列 10 print(numbers)
2-5 列表的增删改查操作
列表的新增、修改、删除操作
| 用法 | 描述 |
| list.append(新元素) | 在列表末端追加新元素 |
| list.insert(索引,新元素) | 在指定索引插入新元素 |
| list[索引]=新值 | 更新指定索引位置数据 |
| list[起始索引:结束索引]=新列表 | 更新指定范围数据 |
| list.remove(元素) | 删除指定元素 |
| list.pop(索引) | 按索引删除指定元素 |
1 #列表的写操作 2 persons = ['张三', '赵六', '李四', '王五', '赵六', '钱七', '孙八'] 3 #列表的追加 4 persons.append("杨九") 5 print(persons) 6 #列表的插入 7 persons.insert(2,'刘二') 8 print(persons) 9 persons.insert(len(persons),'候大') 10 print(persons) 11 #列表的更新 12 persons[2] = "宋二" 13 print(persons) 14 #列表范围取值是“左闭右开” 15 persons[3:5] = ['王五', '李四'] 16 print(persons) 17 #列表的删除 18 #按元素内容删除 19 persons.remove("宋二") 20 print(persons) 21 #按索引值删除元素 22 persons.pop(4) 23 print(persons) 24 persons[4:7] = [] 25 print(persons)
2-6 列表的其他常用方法及使用技巧(掌握技巧,提高编程效率)
1 #其他常用方法 2 persons = ['张三', '赵六', '李四', '王五', '赵六', '钱七', '孙八'] 3 #统计出现次数 4 cnt = persons.count('赵六') 5 print(cnt) 6 #追加操作 7 #append将整个列表追加到末尾,extend则是将列表中的元素追加到原始列表末尾 8 persons.append(['杨九', '吴十']) 9 print(persons) 10 persons.extend(['杨九', '吴十']) 11 print(persons) 12 #in运算符(成员运算符)用于判断数据是否在列表中存在,存在返回True,不存在返回False 13 b = '张三'in persons 14 print(b) 15 c = '李一'in persons 16 print(c) 17 #copy函数用于复制列表 18 persons1 = persons.copy() 19 persons2 = persons 20 print(persons1) 21 #is身份运算符用于判断两个变量是否指向同一块内存 22 print(persons1 is persons) 23 print(persons2 is persons) 24 #clear用于清空列表 25 persons.clear() 26 print(persons) 27 print(persons1) 28 print(persons2)
2-7 嵌套列表
1 #多维列表(嵌套列表) 2 #[[姓名,年龄,工资],[姓名,年龄,工资],[姓名,年龄,工资]] 3 #字符串:“姓名,年龄,工资”例如:“张三,30,2000” 4 #str = "张三,30,2000" 5 #l = str.split(",") 6 #print(l) 7 emp_list = [] 8 while True: 9 info = input("请输入员工信息:") 10 if info =="": 11 print("程序结束") 12 break 13 info_list = info.split(",") 14 if len(info_list) != 3: 15 print("输入格式不正确,请重新输入") 16 continue 17 emp_list.append(info_list) 18 #print(emp_list) 19 for emp in emp_list: 20 print("{n},年龄:{a},工资:{s}".format(n=emp[0], a=emp[1], s=emp[2]))
三、字典介绍与的基本操作(重要的数据类型)
3-1 字典介绍与创建方式
列表存储数据的问题
- 列表在表达结构化数据是语义不明确
- 结构化数据是只有明确属性,明确表示规则的数据
什么是字典
- 字典(Dictionary)是python中的内置数据结构
- 字典非常适合表达结构化数据
1 { 2 '姓名':'王峰','性别':'男','绩效评级':'A','岗位':'销售','工资':1000,'话费补贴':100 3 }
字典的特点
- 字典采用键(key):值(value)形式表达数据
- 字典中key不允许重复,value允许重复
- 字典是可修改的,运行时动态调整储存空间
创建字典的两种方式
- 使用{}创建字典
- 使用dict函数创建字典
1 #字典的创建 2 #1.使用{} 3 dict1 = {}#空的字典 4 print(type(dict1)) 5 dict2 = {'name': '王峰', 'sex': "男", 6 'hiredate': '1997-10-20', 'grade': 'A', 7 'jod': '销售', 'salary': 1000, 8 'welfare': 100 9 } 10 print(dict2) 11 12 #2.利用dict函数创建字典 13 dict3 = dict(name='王峰', sex='男', hiredate='1997-10-20') 14 print(dict3) 15 dict4 = dict.fromkeys(['name', 'sex', 'hiredate', 'grade'], 'N/A') 16 print(dict4)
3-2 字典的取值操作
1 #字典的取值操作 2 employee = {'name': '王峰', 'sex': "男", 3 'hiredate': '1997-10-20', 'grade': 'A', 4 'job': '销售', 'salary': 1000, 5 'welfare': 100 6 } 7 8 #字典的取值 9 name = employee['name'] 10 print(name) 11 salary = employee['salary'] 12 print(salary) 13 print(employee.get('job')) 14 print(employee.get('dept', '其他部门')) 15 16 # in 成员运算符 17 print('name'not in employee) 18 print('dept'not in employee) 19 20 #遍历字典 21 for key in employee: 22 v = employee[key] 23 print(v) 24 for key,value in employee.items(): 25 print(key, value)
3-3 字典更新与删除操作
1 #字典的更新操作 2 employee = {'name': '王峰', 'sex': "男", 3 'hiredate': '1997-10-20', 'grade': 'A', 4 'job': '销售', 'salary': 1000, 5 'welfare': 100 6 } 7 print(employee) 8 #单个kv进行更新 9 employee['grade']='B' 10 print(employee) 11 #对多个kv进行更新 12 employee.update(salary=1200, welfare=150) 13 print(employee) 14 15 #字典的新增操作与更新操作完全相同,秉承有则更新,无则新增的原则 16 employee['dept'] = '研发部' 17 print(employee) 18 employee['dept'] = '市场部' 19 print(employee) 20 employee.update(weight=80,dept='财务部') 21 print(employee) 22 23 #与删除相关的函数 24 #1.pop删除指定的kv 25 employee.pop('weight') 26 print(employee) 27 #2.popitem删除最后一个kv 28 kv=employee.popitem() 29 kv=employee.popitem() 30 print(kv) 31 print(employee) 32 #3.clear清空字典 33 employee.clear()
3-5 字典的常用操作
字典的常用操作
- 为字典设置默认值
- 字典的视图
- 字典的格式化输出
1 emp1 = {'name': 'Jacky', 'grade': 'B'} 2 emp2 = {'name': 'Lily', 'grade': 'A'} 3 # 1.setdefault为字典设置默认值,如果某个key已存在则忽略,如果不存在则设置 4 emp1.setdefault('grade', 'C') 5 emp2.setdefault('grade', 'C') 6 # if 'grade'not in emp2: 7 # emp2['grade']='C' 8 print(emp2) 9 10 # 2.获取字典的视图 11 # (1)keys代表所获取所有的键 12 ks = emp1.keys() 13 print(ks) 14 print(type(ks)) 15 # (2)values代表获取所有的值 16 vs = emp1.values() 17 print(vs) 18 print(type(vs)) 19 # (3)items代表或去所有的键值对 20 its = emp1.items() 21 print(its) 22 print(type(its)) 23 emp1['hiredate'] = '1984-05-30' 24 print(ks) 25 print(vs) 26 print(its) 27 28 # 3.利用字典格式化字符串 29 # 老版本的字符串格式化 30 emp_str = "姓名:%(name)s,评级:%(grade)s,入职时间:%(hiredate)s"%emp1 31 print(emp_str) 32 # 新版本的字符串格式化 33 emp_str1 = "姓名:{name},评级:{grade},入职时间:{hiredate}".format_map(emp1) 34 print(emp_str1)
3-6 散列值与字典的存储原理(内存是如何存储数据)
散列值(Hash)
- 字典也称为“哈希(Hash)”,对应“散列值”
- 散列值是从任何一种数据中创建数字“指纹”
- Python中提供hash()函数生成散列值
1 # 散列值 hash() 2 h1 = hash("abc") 3 print(h1) 4 h2 = hash("bcd") 5 print(h2) 6 h3 = hash(8838183) 7 print(h3) 8 h4 = hash("abc") 9 h5 = hash("def") 10 print(h4) 11 print(h5)
字典的存储原理
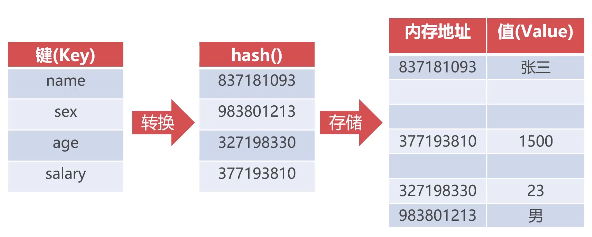
1 # 处理员工数据 2 source = "7782,CLARK,MANAGER,SALES,5000$7934,MILLER,SALESMAN,SALES,3000$7369,SMITH,ANALYST,RESEARCH,2000" 3 employee_list = source.split("$") 4 print(employee_list) 5 6 # 保存所有解析后的员工信息,key是员工编号,value则是包含完整员工信息的字典 7 all_emp = {} 8 9 for i in range(0,len(employee_list)): 10 # print(i) 11 e = employee_list[i].split(",") 12 print(e) 13 14 # 创建员工字典 15 employee = {"no": e[0], "name": e[1], "job": e[2], "department": e[3], "salary": e[4]} 16 print(employee) 17 all_emp[employee['no']] = employee 18 print(all_emp) 19 20 empno=input("请输入员工编号:") 21 emp = all_emp.get(empno) 22 if empno in all_emp: 23 print("工号:{no},姓名:{name},岗位:{job},部门:{department},工资:{salary}".format_map(emp)) 24 else: 25 print("员工信息不存在")
四、课程总结
课程总结
- 列表有序存储数据,按索引值进行提取
- 字典采用键值方式存储数据,数据无序存储
- 列表
- 列表中的数据按顺序排列
- 列表有正序与倒序两种索引
- 列表可存储任意类型数据,且允许重复
- for..in语句
- for..in语句专门用于遍历列表、元组等数据结构
- 冒泡排序
- 什么是字典
- 字典是Python中的内置数据结构
- 字典非常适合表达结构化数据
- 字典的特点
- 字典采用键(key):值(value)形式表达数据
- 字典中key不允许重复,value允许重复
- 字典是可以修改的,运行时动态调整存储空间
- 创建字典的两种方式
- 使用{}创建字典
- 使用dict函数创建字典
- 散列值(hash)
- 字典也称为“哈希(Hash)”,对应“散列值”
- 散列值是从任何一种数据中创建数字“指纹”
- Python中提供了hash()函数生成散列值
- 字典的存储原理
-















 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









