 Java集合框架全面解析
Java集合框架全面解析







认识集合:
单列集合(Collection):

每个元素只包括一个值
双列集合(Map):
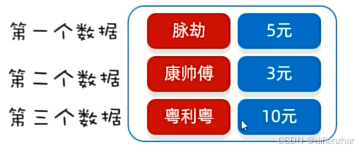
每个元素都是一个键值对
集合体系:
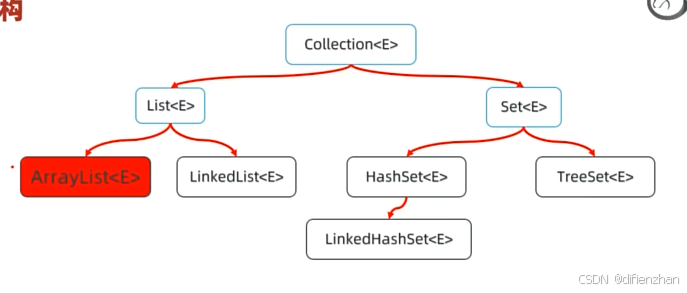
Collection作为List和Set的父接口 在第三层的实践类implement List或者Set接口 从而实现不同的功能。
List一列的特点:有序,可重复,有索引
Set一列的特点:无序,不可重复,无索引
(LinkedHashSet:有序,不可重复,无索引;TreeSet:按照大小升序排序,不可重复,无索引)
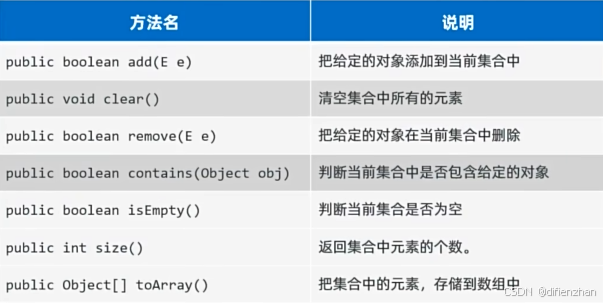
Collection集合:
常用方法:
三种遍历方法:
迭代器:指明当前指向集合中的位置
Iterator<String> iterator
//生成迭代器
常用方法:
.hasNext()//是否遍历完毕
.next()//返回下一个元素
迭代器一开始位于集合的开头(0索引)每次.next()先返回当前所在位置元素 随后向下一步移动
当迭代器位置索引==size时 hasNext返回false
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
注意问一次取一次 防止越界
增强for循环遍历:

可以用来遍历数组或集合 本质就是迭代器遍历的简化
lambda表达式:
list.forEach(s-> System.out.println(s));
三种遍历的区别:
认识并发修改异常问题:遍历时同时进行增删,可能存在业务异常。
情景:假设需要删除list中含有特定字段的元素
1.如果支持索引 可以使用for循环遍历 每次删除时做i--,或者倒序遍历删除
2.如果不支持索引 则只能使用迭代器iterator 使用迭代器提供的删除方法
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String name=it.next();
if(name.contains("马")){
it.remove();
}
}
由于增强for循环和lambda表达式拿不到迭代器 使用不了it.remove()方法,所以都不能在遍历过程中安全地删除元素 这两种方法只适合做数据的遍历而不是增删操作
List集合:
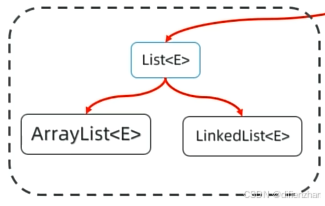
三者特点:有序,可重复,有索引
List的方法:
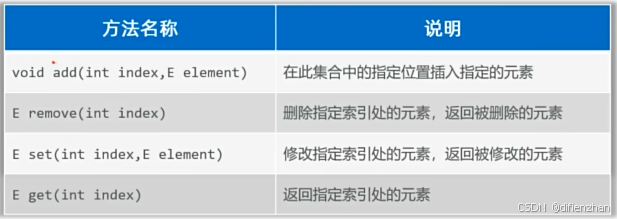
ArrayList和LinkedList的区别:
数据结构不同,应用场景不同。
ArrayList的底层原理:基于数组
查询速度快(根据索引):查询任意数据耗时相同
增删数据效率低
LinkedList的底层原理:基于链表
查询速度慢:由于链表特点 每次查询都要从头节点开始遍历,速度慢
增删数据效率相对数组高
Set集合:
Set一列的特点:无序,不可重复,无索引
(LinkedHashSet:有序,不可重复,无索引;TreeSet:按照大小升序排序,不可重复,无索引)
HashSet:
底层原理:基于哈希表
去重操作:
需求:
创建一个存储学生对象的集合,存储多个学生对象,要求:多个学生对象的成员变量值相同时,我们就认为是同一个对象,要求只保留一个
分析
① 定义学生类,创建Hashset集合对象,创建学生对象
② 把学生添加到集合
③ 在学生类中重写两个方法,hashcode()和equals(),自动生成即可
LinkedHashSet:
底层原理:
依然基于哈希表,每个元素都有双链表机制记录前后两元素的位置
TreeSet:
底层原理:
基于红黑树
对于数值类型,默认按照大小升序排序
对于字符串类型,默认按照首字符编号升序排序
Map集合:
也被称为键值对集合,所有键不可重复,值可重复,键值一一对应
体系:
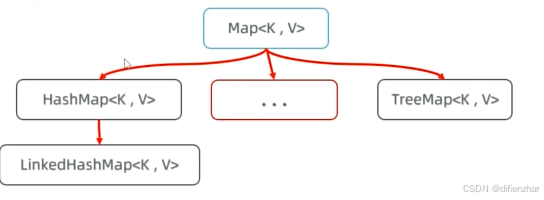
Map集合中只对键做要求,值作为附属品不做要求

类似Set集合
Map的遍历方式:
1.键找值:先获取Map的所有键,遍历键找值

2.把键值对看作整体进行遍历(难度大)
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
使用Entry这个接口,将键值对封装成一个对象,类型为Map.Entry<String, Integer>
3.lambda

map.forEach(new BiConsumer<String, Integer>() {
@Override
public void accept(String s, Integer integer) {
System.out.println(s+":"+integer);
}
});
将匿名内部类写成lambda表达式:
map.forEach((k, v) -> System.out.println(k + "=" + v));
Stream流:
用于操作集合和数组的数据的API,大量结合了lambda表达式的写法,功能强大
使用步骤:
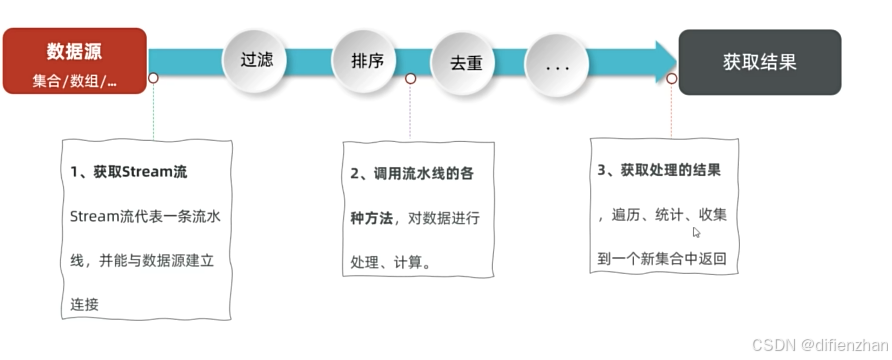
Collection获取流:
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Stream<Integer> stream = list.stream();
Map获取流:
Map<Integer, String> map = new HashMap<>();
map.put(1, "a");
map.put(2, "b");
map.put(3, "c");
//获取键流
Stream<Integer> stream1 = map.keySet().stream();
//获取值流
Stream<String> stream2 = map.values().stream();
//获取键值对流
Stream<Map.Entry<Integer, String>> stream = map.entrySet().stream();
数组获取流:
String[] name={"1","2","3"};
//Arrays类提供的方法
Stream<String> stream = Arrays.stream(name);
//Stream类提供的方法
Stream<String> objectStream = Stream.of(//此中,参数可传一个 可传一批 可不传);
中间办法:
指调用完成后会返回新的流,可继续使用
常用方法:

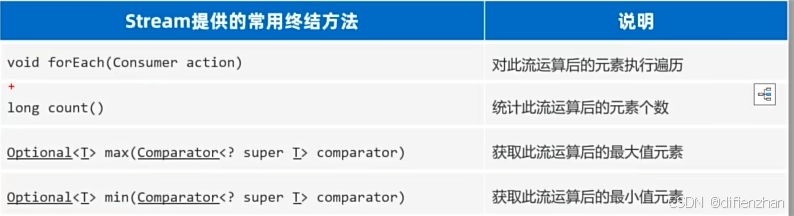
终结方法:
调用完不会返回新的流
常用方法:


















 3882
3882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









