









deepBi 学习笔记
先会用再开发
学会安装
参考官方文档与README_CN.md
官方的脚本无任何错误,出现问题优先考虑电脑、服务器 本身问题,网络,配置等
官方脚本一览
如果报任何错误肯定是你的问题,不要死磕报错浪费不必要的时间,换台机器就好
二开
认识项目结构
技术栈 react+flask+Redis+SQL+docker
.
├── ai #与ai通信代码部分
├── bi #分析图表部分
├── bin
├── client #前端静态文件
├── docker-compose.yml #docker-compose文件
├── Dockerfile.template
├── Docker_install_CN.md #Docker中文安装指南
├── Docker_install.md
├── Install_CN.sh #ubuntu本机安装脚本
├── Install.sh
├── LICENSE
├── Makefile #docker Makefile
├── manage.py #启动器
├── package.json #前端package.json
├── pip.conf
├── README_CN.md #中文README
├── README.md
├── README_window_cn.md
├── README_window_en.md
├── setup.cfg
├── sources.list
├── ubuntu_CN_install.sh #ubuntu本机安装指南中文
├── ubuntu_install.sh
├── ubuntu_start.sh #ubuntu下程序启动脚本
├── ubuntu_stop.sh #ubuntu下程序停止脚本
├── user_manual
├── user_upload_files #用户上传的数据文件,进程pid
├── version.md
├── vrequment.txt
├── webpack.config.js #前端webpack打包js
├── worker.conf
└── yarn.lock如何认识项目结构
-
有开发文档看开发文档
-
开发文档不仔细的看docker相关文件,其中肯定包含了相关的启动命令,从启动入手分析结构docker-compose,./bin/docker-entrypoint,./Installl.sh
-
看进程,看应用启动了哪些进程,监听端口在哪,运行文件路径在哪,本项目中启动后会将每个进程的pid存入user_upload_files中
-
摸鱼
如何下手
首先明确要改什么?本文的目的是:加入一个新的模型,新的适配器,即Adapter.py
在你了解了项目的大体结构之后,你会找到这样一个文件夹./ai/agents/oai,很明显,这个文件夹中就是所有与llm api接口交互要使用到的组件。
第二种思路,直接从前端入手,前端的api配置肯定是写死在前端静态文件中或者从后端请求得来的。
刷新页面,(设置断点)查看前端这些适配器是从哪个请求中传入的,
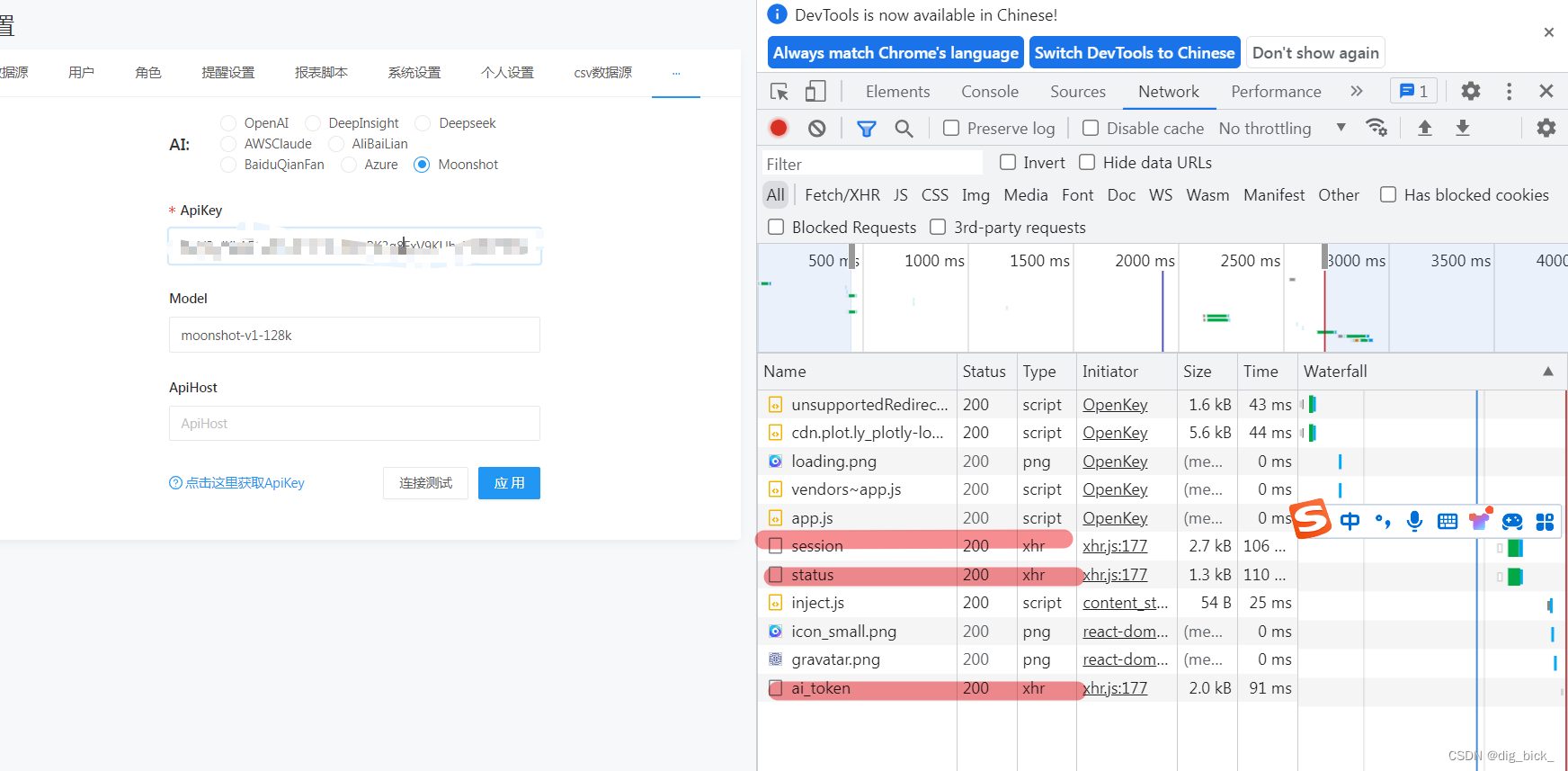
发现了这些请求,一般内容不会在js文件中,其实一眼就可以看出来是从llm.json这个请求中传入的,然后从静态文件中找到llm.json文件,然后顺藤摸瓜是被谁调用的就好了。
├── agentchat #聊天交互相关组件
│ ├── agent.py
│ ├── assistant_agent.py
│ ├── bi_proxy_agent.py
│ ├── chart_presenter_agent.py
│ ├── check_agent.py
│ ├── conversable_agent.py
│ ├── groupchat.py
│ ├── human_proxy_agent.py
│ ├── **init**.py
│ ├── python_proxy_agent.py
│ ├── report_questioner.py
│ ├── task_planner_agent.py
│ ├── task_selector_agent.py
│ └── user_proxy_agent.py
├── agent_instance_util.py
├── agent_llm.py
├── code_utils.py
├── **init**.py
├── oai
│ ├── alibailianAdapter.py #各种适配器
│ ├── azureAdapter.py
│ ├── baiduqianfanAdapter.py
│ ├── claude2Adapter.py
│ ├── claudeAdapter.py
│ ├── completion.py
│ ├── deepseekAdapter.py
│ ├── **init**.py
│ ├── openai_utils.py
│ └── zhipuaiAdapter.py
└── prompt
├── **init**.py
├── prompt_echarts.py
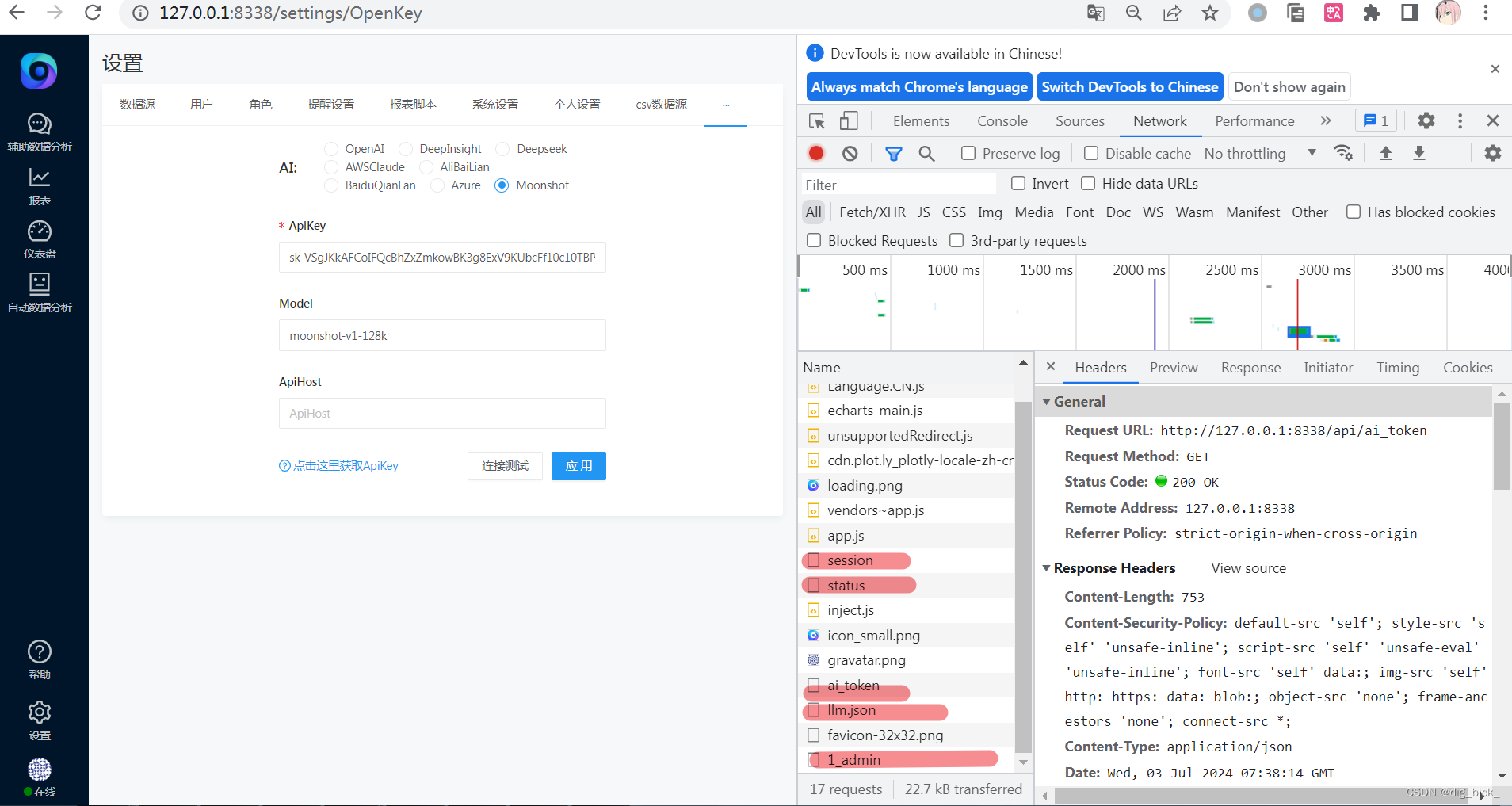
└── prompt_matplotlib.py现在,我们已经拿到了,文件的路径,现在要做的,就是借鉴先人,通过查看其他适配器的历史代码提交记录,通过查看先人修改的文件内容来查看具体要修改那几个文件。
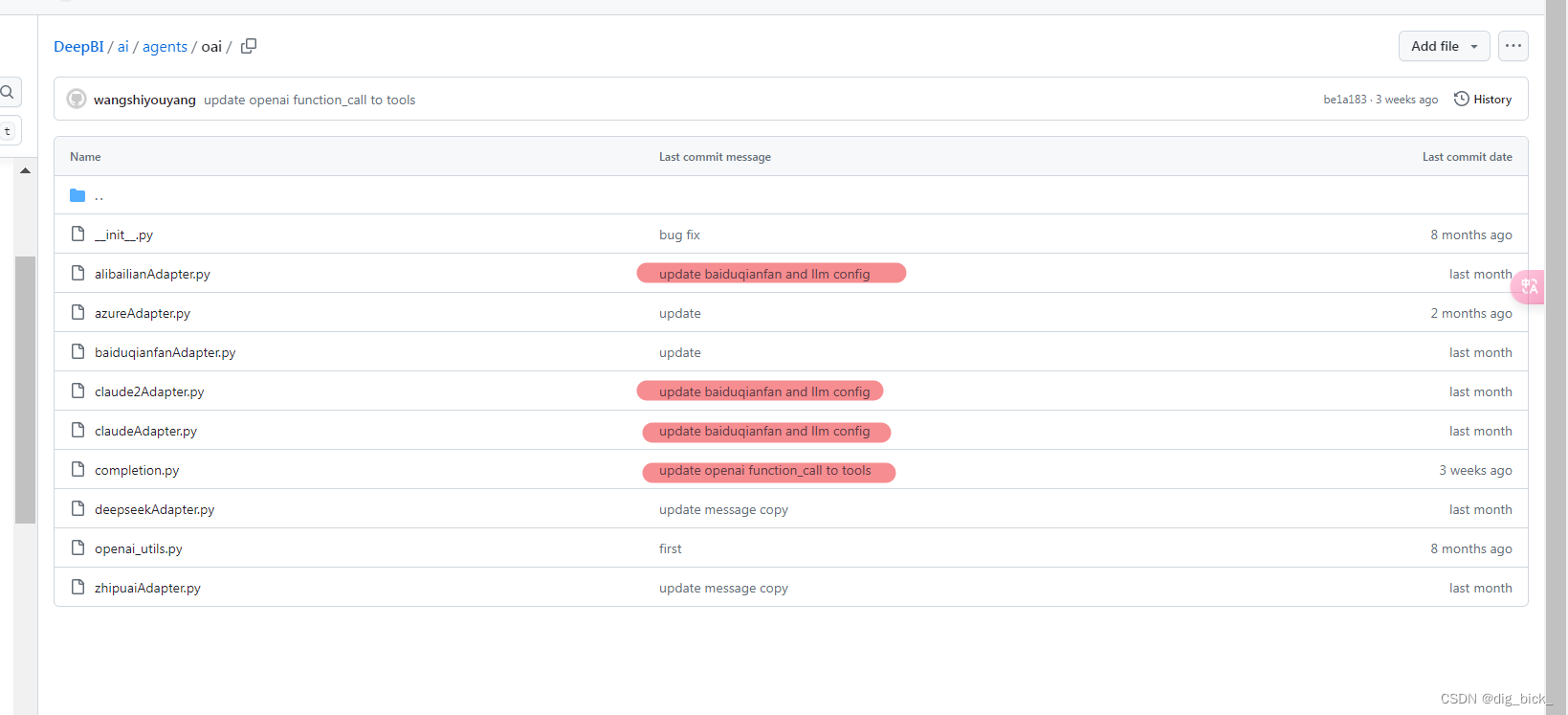
可以看到多个适配器都是同一个请求提交的,这次commit是我们的重点研究对象。

可以看到这次提交修改了多个适配器设置,添加了一个新的baiduqinafan适配器,修改了completion文件,aidb.py,还有静态文件中的llm.json,这里更好跟我们第二种方法分析到的文件对上了,这下十拿九稳了。
llm.json
对于前端静态文件来说,require代表必填,其他对应后端与llm请求的适配器组件

aidb.py
不去看代码的上下文,根据前人的修改其实就可以确定,在这里添加我们的适配器就ok了
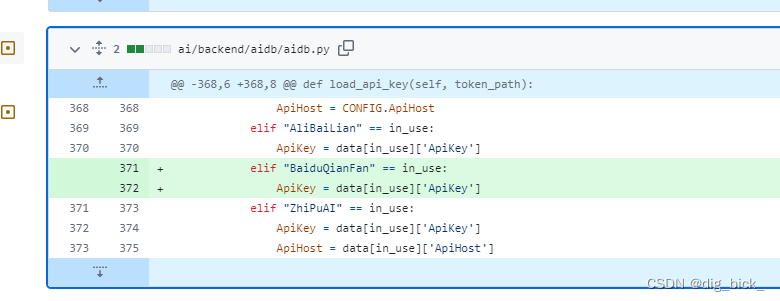
aidb.py文件主要用于与AI接口进行交互,处理数据描述和数据库注释检查等任务。
ai/agents/oai/completion.py
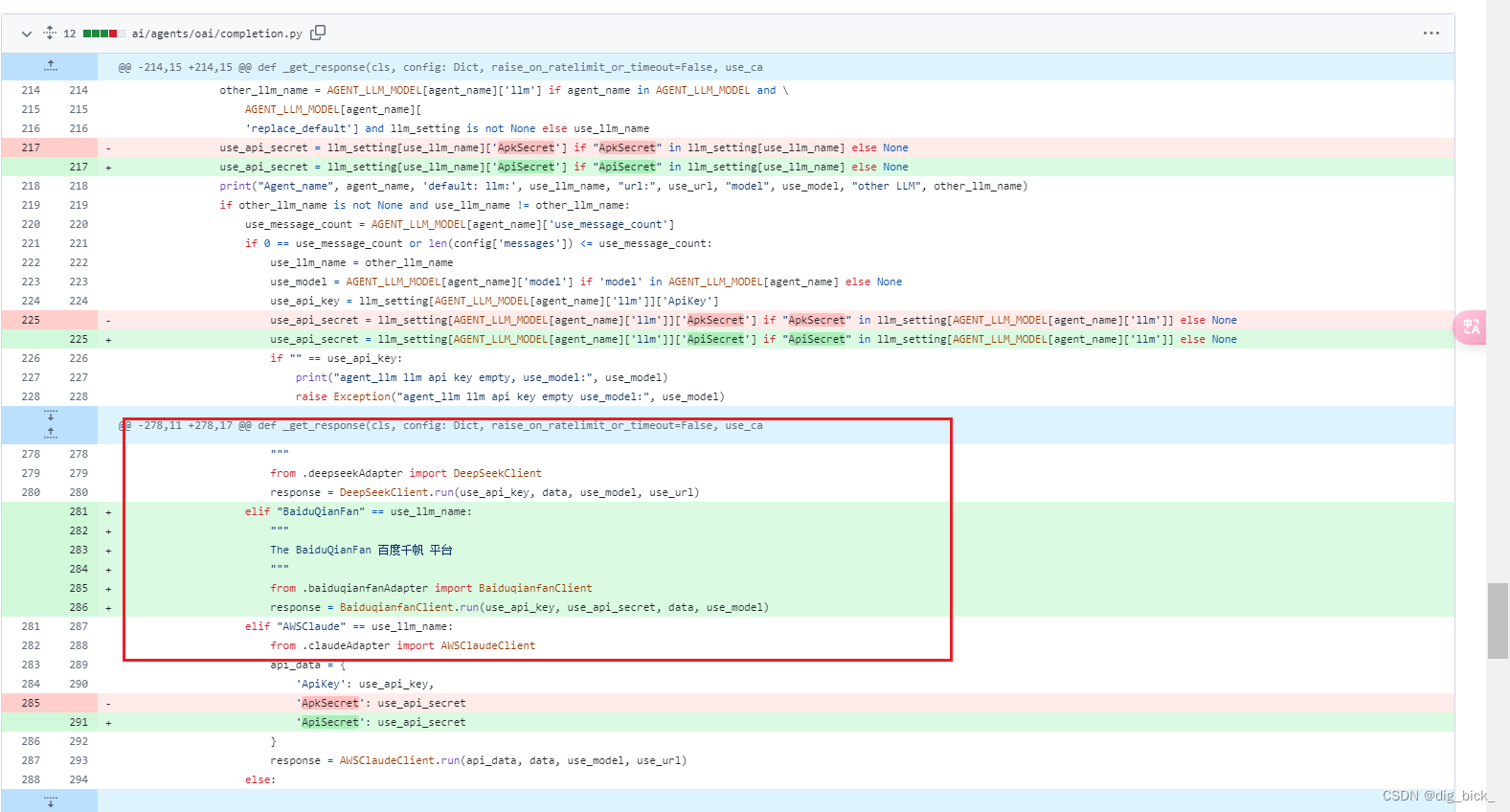
与OpenAI API进行交互,包括处理API请求、响应、缓存和错误处理。
同上,把这 几个文件照葫芦画瓢改一下运行就好啦 ^^
第三种方法 由浅入深,和上面两种根据答案出题的思路不一样,从install.sh、docker-compose、package.json、webpack.config.js出发一步步研究程序是如何一步步被拉起的,可以完全了解一个项目。
webpack.config.js
entry: {
app: [
"./client/app/index.js",
"./client/app/assets/less/main.less",
"./client/app/assets/less/ant.less"
],
server: ["./client/app/assets/less/server.less"]
} output: {
path: path.join(basePath, "./dist"),
// filename: isProduction ? "[name].[chunkhash].js" : "[name].js",
filename: "[name].js",
publicPath: cdn_domain + staticPath
},package.json
"scripts": {
"clean": "rm -rf client/dist/",
"build": "yarn clean && NODE_ENV=production webpack",
"build:old-node-version": "yarn clean && NODE_ENV=production node --max-old-space-size=4096 dules/.bin/webpack",
"watch:app": "webpack --watch --progress --colors -d",
"watch": "npm-run-all --parallel watch:*",
"webpack-dev-server": "webpack-dev-server",
"analyze": "yarn clean && BUNDLE_ANALYZER=on webpack",
"analyze:build": "yarn clean && NODE_ENV=production BUNDLE_ANALYZER=on webpack",
"lint": "yarn lint:base --ext .js --ext .jsx --ext .ts --ext .tsx ./client",
"lint:fix": "yarn lint:base --fix --ext .js --ext .jsx --ext .ts --ext .tsx ./client",
"lint:base": "eslint --config ./client/.eslintrc.js --ignore-path ./client/.eslintignore",
"lint:ci": "yarn lint --max-warnings 0 --format junit --output-file /tmp/test-results/eslint/results.xml",
"prettier": "prettier --write 'client/app/**/*.{js,jsx,ts,tsx}' 'client/cypress/**/*.{js,jsx,ts,tsx}'",
"type-check": "tsc --noEmit --project client/tsconfig.json",
"type-check:watch": "yarn type-check --watch",
"jest": "TZ=Africa/Khartoum jest",
"test": "run-s type-check jest",
"test:watch": "jest --watch",
"cypress": "node client/cypress/cypress.js"
},docker
./Installl.sh
docker-compose.yml
/bin/docker-entrypointentrypoint
help() {
echo "DeepBi Docker."
echo ""
echo "Usage:"
echo ""
echo "server -- start deepbi server (with gunicorn)"
echo "worker -- start a single RQ worker"
echo "scheduler -- start an rq-scheduler instance"
echo ""
echo "shell -- open shell"
echo "debug -- start Flask development server with remote debugger via ptvsd"
echo "create_db -- create database tables"
echo "manage -- CLI to manage deepbi"
}RQ(Redis Queue)工作进程
worker() {
echo "Starting RQ worker..."
export WORKERS_COUNT=${WORKERS_COUNT:-2}
export QUEUES=${QUEUES:-}
exec supervisord -c worker.conf
}[supervisord]
logfile=/dev/null
pidfile=/tmp/supervisord.pid
nodaemon=true
[unix_http_server]
file = /tmp/supervisor.sock
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[program:worker]
command=./manage.py rq worker %(ENV_QUEUES)s
process_name=%(program_name)s-%(process_num)s
numprocs=%(ENV_WORKERS_COUNT)s
directory=/app
stopsignal=TERM
autostart=true
autorestart=true
startsecs=300
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stderr
stderr_logfile_maxbytes=0
[eventlistener:worker_healthcheck]
serverurl=AUTO
command=./manage.py rq healthcheck
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stderr
stderr_logfile_maxbytes=0
events=TICK_60端口及服务
8338
当访问 8338 端口时,Gunicorn 将请求传递给 Flask 应用,Flask 应用根据配置处理请求并提供响应。
server
server() {
# Recycle gunicorn workers every n-th request. See http://docs.gunicorn.org/en/stable/settings.html#max-requests for more details.
MAX_REQUESTS=${MAX_REQUESTS:-1000}
MAX_REQUESTS_JITTER=${MAX_REQUESTS_JITTER:-100}
TIMEOUT=${DEEPBI_GUNICORN_TIMEOUT:-60}
exec /usr/local/bin/gunicorn -b 0.0.0.0:8338 --name deepbi -w${DEEPBI_WEB_WORKERS:-4} bi.wsgi:app --max-requests $MAX_REQUESTS --max-requests-jitter $MAX_REQUESTS_JITTER --timeout $TIMEOUT
}
wsgi.py文件是 WSGI 服务器的入口点,通过调用create_app函数创建和配置 Flask 应用实例。app.py文件包含自定义的 Flask 应用类Bi,并定义了create_app工厂函数,用于创建和初始化 Flask 应用及其所有扩展和模块。- 这种结构使得应用初始化逻辑集中在一个地方,易于维护和测试,也遵循了 Flask 推荐的应用工厂模式。
8339
server_socket
server_socket() {
echo "Starting ai web-socket server.."
exec /app/manage.py run_ai
}8340
server_api
server_api() {
echo "Starting ai web-api server.."
exec /app/manage.py run_ai_api
}deepBI分析
前端react
前端是用React构建的单页应用(SPA),负责在用户浏览器中显示界面和处理用户交互。React应用通过HTTP请求与后端进行通信,通常是通过AJAX或Fetch API来发送请求并接收响应。
后端python
Web框架 flask
Gunicorn是一个高性能的WSGI HTTP服务器,用于运行您的Python Web应用。它接收客户端的HTTP请求,通过WSGI接口将请求传递给后端的Web框架(如Django或Flask),并将处理后的响应返回给客户端。
WSGI(Web Server Gateway Interface)是Web服务器与Web应用之间的标准接口。Gunicorn作为WSGI服务器,运行您的Django或Flask应用,通过WSGI接口处理请求和响应。
- 客户端请求:用户在浏览器中访问React应用。
- React与后端通信:React应用通过HTTP请求与后端服务器(运行在Gunicorn上的Django或Flask应用)通信,通常使用RESTful API或GraphQL。
- Gunicorn接收请求:Gunicorn作为WSGI服务器,接收来自React应用的HTTP请求。
- WSGI处理:Gunicorn通过WSGI接口将请求传递给Flask应用。
- 后端处理:Flask应用处理请求(如查询数据库、执行业务逻辑),并生成响应。
- Gunicorn返回响应:处理完成后,Django或Flask应用通过WSGI接口将响应返回给Gunicorn,Gunicorn再将响应发送回React应用。
- 前端更新:React应用接收到响应后,根据响应数据更新界面。
文件结构
ai
bi
settings
helpers
辅助函数
def fix_assets_path(path):
fullpath = os.path.join(os.path.dirname(__file__), "../", path)
return fullpath- 从环境变量
DEEPBI_FLASK_TEMPLATE_PATH获取模板文件路径。如果环境变量未设置,则默认使用STATIC_ASSETS_PATH的值。 - 同样,通过
fix_assets_path函数将其转换为绝对路径。
bin
client
.eslintignore
build/.js dist config/.js client/dist
app
react源代码
.\app\pages\settings\OpenKey.jsx
const response = await fetch("/static/llm.json");
if (!response.ok) {
throw new Error("Failed to load local llm.json API key data");
}分析部分由ai生成

















 2104
2104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









