







standalone
1.基本操作
解压flink
tar -zxvf flink-1.7.1-bin-hadoop26-scala_2.11.tgz
移动到指定目录
mv flink-1.7.1 /opt/sxt/

如上图所示 flink权限需要修改
修改所属人/组
chown root:root -R flink-1.7.1/
修改权限
chmod 755 -R flink-1.7.1/
2.配置 flink-conf.yaml
vim flink-conf.yaml
- 手动配置jdk环境变量和 jobmanager地址
注意中间有空格 (可根据颜色区分配置错误)

- jobmanager和taskmanager的进程内存使用默认即可
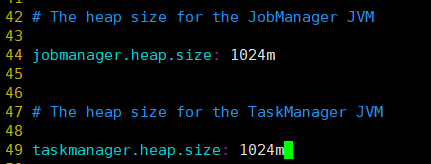
- taskmanager的task slot(插槽)个数 和 默认任务并行度
这里插槽改成了3
一个插槽对应一个并行度任务

3.配置slaves文件(从节点taskmanager配置)
4.配置masters文件
因为之前 配置flink-conf.yaml文件时已经指定了jobmanager的位置
所以无需配置
5.拷贝flink到其他节点
scp -r flink-1.7.1/ bd1302:`pwd`
scp -r flink-1.7.1/ bd1303:`pwd`
6.启动flink
进入bin目录
cd /opt/sxt/
开启flink
./start-cluster.sh

7.访问flink集群的webui界面 8081端口
http://bd1301:8081/
8.提交任务
- 1.第一种:命令行提交
在bin目录下
./flink run -c 方法全路径(com.xxxxx.xxx) jar包的路径
- 2.第二种:webui方式提交

点击提交按钮,提交jar包

提交jar包后

接着提交任务
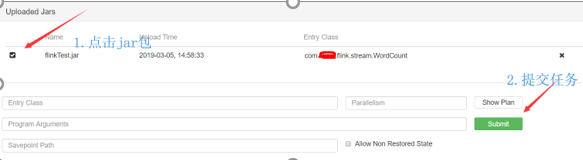

提前开启端口

提交

Yarn
配置
Flink on yarn 只要有个Flink客户端,能够提交任务到yarn上即可。
因为客户端需要访问 Hadoop 配置,从而连接 YARN 资源管理器和 HDFS。可以使用下面的策略来决定 Hadoop 配置:
-
检测 YARN_CONF_DIR, HADOOP_CONF_DIR 或 HADOOP_CONF_PATH 环境变量是否设置了(按该顺序检测)。如果它们中有一个被设置了,那么它们就会用来读取配置(有任意一个即可)。
-
如果上面的策略失败了(如果正确安装了 YARN 的话,就不应该会发生),客户端会使用 HADOOP_HOME 环境变量。如果该变量设置了,客户端会尝试访问 $HADOOP_HOME/etc/hadoop (Hadoop 2) 和 $HADOOP_HOME/conf(Hadoop 1)。
这里,在/etc/profile文件种配置HADOOP_CONF_DIR环境变量。如图所示:

配置完后,让它生效即可 source /etc/profile
Yarn提交模式
Yarn-session模式
该模式是预先在yarn上面划分一部分资源给flink集群用,flink提交的所有任务,共用这些资源。如下图所示

- 先启动一个yarn-session,并指明分配的资源。命令:
./yarn-session.sh -n 3 -jm 1024 -tm 1024
- -n 指明container容器个数,即 taskmanager的进程个数。
- -jm 指明jobmanager进程的内存大小
- -tm 指明每个taskmanager的进程内存大小
- 启动yarn-session后,就可以提交任务了…
注意:由于flink任务是要提交给jobmanager的,所以我们得知道它的地址,在启动yarn-session后的日志中会显示:

知道 jobmanager地址后,提交任务:
. /flink run -m node06:55695 /opt/sxt/flinkTest.jar
- 停止yarn上的flink集群:
若要停止yarn上的flink集群,首先找到application_id,如图:

然后执行命令:
yarn application -kill application_id
Single-job模式
该模式是每次提交任务,都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后,flink集群也会消失。如下图:

任务提交命令:
./flink run -m yarn-cluster -yn 2 /opt/sxt/flinkTest.jar
- -m: 后面跟的是yarn-cluster,不需要指明地址。这是由于Single job模式是每次提交任务会新建flink集群,所以它的jobmanager是不固定的
- -yn: 指明taskmanager个数。















 4049
4049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









