






web assembly 逆向。
环境
调试方法
live server 打开浏览器,可以正确解析导入的 js 和 wasm。然后 f12 在 source 打断点,内存是一个局部变量,打了断点之后去 console 读memory
反编译
jeb 可以正确反编译,反编译得到的结果是 c 语言。
其中,反编译结果里 gvar_3, gvar_8 这一类变量的地址值就是 0x3, 0x8. 所以 &gvar_8 其实是常量 8 的意思。i32.load @Ch(4) 会被解释称 (int* )(var + &gvar8) +1,也就是 +12 取值。
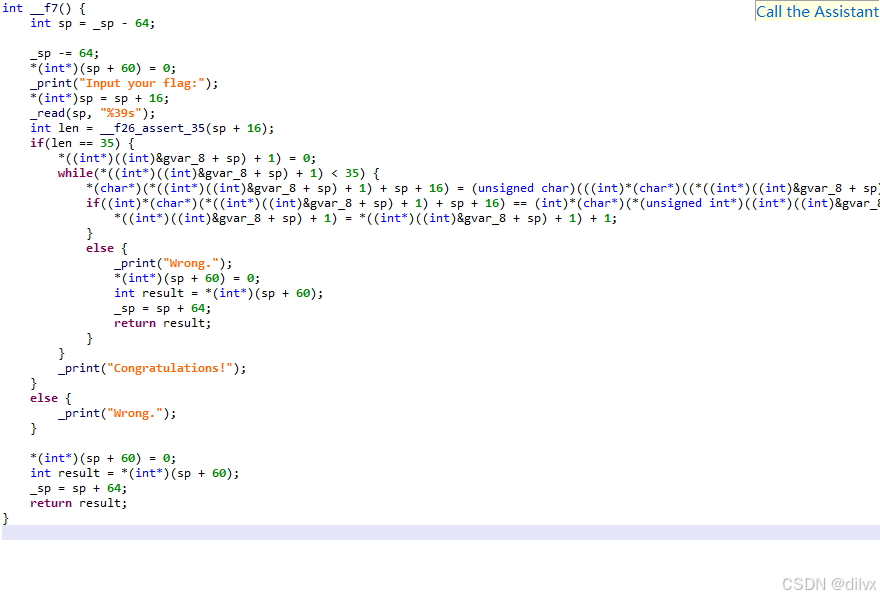
逆向的 notes
strlen
反编译结果上来是完全没有符号的。像 print, read 这种很容易猜出来。
这个 func26 一开始并不知道是什么,只是结果 == 35 感觉像是算长度。追踪进去看的反编译结果是这样的:
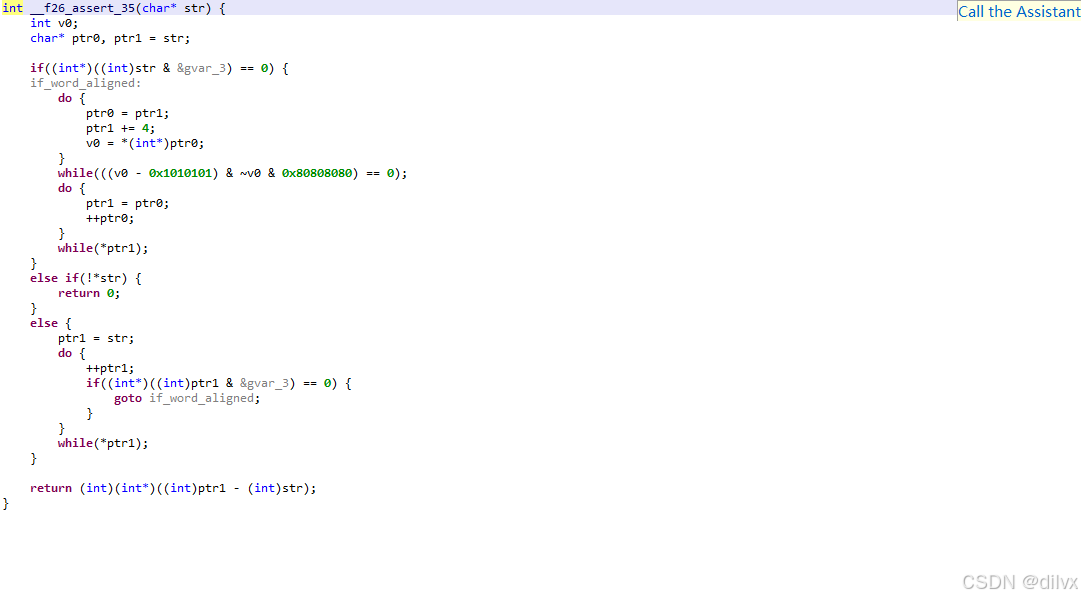
一开始看到这个 0x1010101 和 0x80808080 把孩子吓到了,甚至感觉有加密什么的东西。第一段逻辑不知道在干什么,不过,如果假设开头的 if 是 false 的话(也就是地址没对齐到 word),函数就会走最后的 else。最后面那个肯定是算长度,所以 func26 大概率是算长度。
那回到分支的第一个代码块,问了下 gpt,这其实是 4-byte 时候的优化:
这段代码的主要目的是每次检查4个字节,而不是一次只检查一个字节,从而加快处理速度。
这个条件的原理是:
- 如果一个字节是'\0'(值为0),那么
(该字节 - 1)的最高位会是1。v0 - 0x1010101会使得任何为0的字节在相减后的对应位置产生一个值,其最高位为1。~v0会使得原来为0的字节在结果中所有位都变为1。& 0x80808080只保留每个字节的最高位。如果结果不为0,说明找到了一个空字符,循环结束。
这种方法比逐字节检查要快得多,特别是对于长字符串。它利用了整数运算和位操作的效率,一次性检查4个字节。
需要注意的是,这种方法假设了字符串的内存对齐,并且在不同的体系结构上可能需要调整(例如,在大端序系统上)。
逆向 check 的逻辑

观察结构,大概意思是把 input 按位异或然后和 template 比较,如果 true 就继续否则就 exit
那么,template 就在 +16540 这个内存地址。不过这里有一个弱智的地方,jeb 这个 +16540 是按 4-Byte 指针计算的,实际地址是 +16540*4……
从 console 把这个地方的 bytes 读出来,拿 python 枚举一下开头的字符,然后就解出来了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









