







JAVA特性
1. 封装:就是隐藏对象的属性和实现细节,仅对外提供公共访问方式。
2. 继承:通过使用继承我们能够非常方便地复用以前的代码,能够大大的提高开发的效率。
3. 多态:同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。重写和重载
抽象类与接口
| 参数 | 抽象类 | 接口 |
| 默认的方法实现 | 它可以有默认的方法实现 | 接口完全是抽象的。它根本不存在方法的实现 |
| 实现 | 子类使用extends关键字来继承抽象类。如果子类不是抽象类的话,它需要提供抽象类中所有声明的方法的实现。 | 子类使用关键字implements来实现接口。它需要提供接口中所有声明的方法的实现 |
| 构造器 | 抽象类可以有构造器 | 接口不能有构造器 |
| 与正常Java类的区别 | 除了你不能实例化抽象类之外,它和普通Java类没有任何区别 | 接口是完全不同的类型 |
| 访问修饰符 | 抽象方法可以有public、protected和default这些修饰符 | 接口方法默认修饰符是public。你不可以使用其它修饰符。 |
| main方法 | 抽象方法可以有main方法并且我们可以运行它 | 接口没有main方法,因此我们不能运行它。 |
| 多继承 | 抽象方法可以继承一个类和实现多个接口 | 接口只可以继承一个或多个其它接口 |
| 速度 | 它比接口速度要快 | 接口是稍微有点慢的,因为它需要时间去寻找在类中实现的方法。 |
| 添加新方法 | 如果你往抽象类中添加新的方法,你可以给它提供默认的实现。因此你不需要改变你现在的代码。 | 如果你往接口中添加方法,那么你必须改变实现该接口的类。 |
反射
https://blog.csdn.net/sinat_38259539/article/details/71799078
https://www.cnblogs.com/ysocean/p/6516248.html
Java反射就是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性。
反射机制允许程序在运行时取得任何一个已知名称的class的内部信息,包括包括其modifiers(修饰符),fields(属性),methods(方法)等,并可于运行时改变fields内容或调用methods。那么我们便可以更灵活的编写代码,代码可以在运行时装配,无需在组件之间进行源代码链接,降低代码的耦合度;还有动态代理的实现等等;但是需要注意的是反射使用不当会造成很高的资源消耗!
动态代理
https://www.cnblogs.com/gonjan-blog/p/6685611.html
代理模式是常用的java设计模式,他的特征是代理类与委托类有同样的接口,代理类主要负责为委托类预处理消息、过滤消息、把消息转发给委托类,以及事后处理消息等。
静态代理即在代理类中明确指出了被代理的类,在编译前就已完成,而动态代理则是一个通用的代理类,只有在运行期才能确定被代理的类,一般通过反射来实现,可用于实现Spring中的AOP。
异常处理
http://www.importnew.com/26613.html
异常
Throwable:
1. ERROR:程序无法处理的异常,一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢等。对于这类错误的导致的应用程序中断,仅靠程序本身无法恢复和和预防,遇到这样的错误,建议让程序终止。
2. EXCEPTION:
(1)RuntimeException:运行时异常,即在代码编写过程中我们可以对这种异常不做处理,当发生异常时直接交给虚拟机处理。比如:我们从来没有人去处理过NullPointerException异常,它就是运行时异常,并且这种异常还是最常见的异常之一。
五种常见的运行时异常:
ClassCastException(类转换异常)
IndexOutOfBoundsException(数组越界)
NullPointerException(空指针)
ArrayStoreException(数据存储异常,操作数组时类型不一致)
BufferOverflowException(IO异常)
(2)CheckedException:我们经常遇到的IO异常及sql异常就属于检查式异常。对于这种异常,java编译器要求我们必须对出现的这些异常进行catch 所以 面对这种异常不管我们是否愿意,只能自己去写一堆catch来捕捉这些异常。
关键字
try:try中定义的变量是局部变量,只能在try中使用。
catch:对异常进行捕获并进行处理,catch不可使用try中的局部变量。
finally:常用于回收物理资源,例如关闭数据库连接,因为虚拟机不会主动对物理资源进行回收。try和catch之后必会执行finally 中的语句,除非执行了System.exit(1),在finally中不要写return或者抛出异常,否则会覆盖之前的处理结果,产生不可预期的问题。
throw:用来手动抛出异常,可以单独使用,但是需要注意的是其抛出的是一个异常实例,而非异常类。
throws:用于方法的声明上,当前方法不知道如何处理异常时,交由上一级方法进行处理。
public class ExceptionTest {
public static void main(String[] args) {
try {
Test1(true);
} catch (MyException e) {
e.printStackTrace();
}
}
public static void Test1(boolean flag) throws MyException{
if(flag)
throw new MyException("flag = true");
else
System.out.println("no error");
}
}
class MyException extends Exception {
public MyException(String msg){
super(msg);
}
}
Exception.MyException: flag = true
at Exception.ExceptionTest.Test1(ExceptionTest.java:15)
at Exception.ExceptionTest.main(ExceptionTest.java:7)
异常链
企业应用做法:程序先捕获原始异常,然后抛出一个新的业务异常,新的业务异常中包含对用户的提示信息—–这种做法叫异常转译。因为核心是:在合适的层级处理异常。
异常的打印:Java的异常跟踪栈,printSrackTrace()方法–用于打印异常的跟踪栈信息。这个设计体现了一个设计模式-职责链模式。这个异常传播方式:只要异常没被完全捕获,异常从发生异常的方法逐渐向外传播,首先传给方法的调用者,该方法调用者再传给其调用者,直至传至上一层的方法,一层层传递。如果最上层的方法还没处理该异常,JVM就会中止程序,并打印异常的跟踪栈信息。
序列化与反序列化
https://www.cnblogs.com/ysocean/p/6870069.html
https://www.cnblogs.com/xdp-gacl/p/3777987.html
序列化:指把堆内存中的 Java 对象数据,通过某种方式把对象存储到磁盘文件中或者传递给其他网络节点(在网络上传输)。这个过程称为序列化。通俗来说就是将数据结构或对象转换成二进制串的过程
反序列化:把磁盘文件中的对象数据或者把网络节点上的对象数据,恢复成Java对象模型的过程。也就是将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。
public class Main {
public static void main(String[] args) {
//序列化
try {
OutputStream op = new FileOutputStream("D:"+File.separator+"io"+File.separator+"a.txt");
ObjectOutputStream ops = new ObjectOutputStream(op);
ops.writeObject(new Person("马嘉祺",16));
ops.close();
} catch (Exception e) {
e.printStackTrace();
}
//反序列化
try {
InputStream ip = new FileInputStream("D:"+File.separator+"io"+File.separator+"a.txt");
ObjectInputStream ips = new ObjectInputStream(ip);
Person p = (Person) ips.readObject();
System.out.println(p.getName()+" "+p.getAge());
ips.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}public class Person implements Serializable {
private String name;
private int age;
public Person(String name) {
this.name = name;
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
serialVersionUID的作用:
serialVersionUID是版本号,java可以根据其类名,接口名,方法名,属性等进行自动生成。如果不在代码中显式指定,则每次编译时,java编译器会自动生成版本号,这样会导致修改后的类或者是使用不同编译器生成的版本号和之前的会不一致,会报版本号不一致的错误。因此强烈建议在一个可序列化类中显示的定义serialVersionUID,为它赋予明确的值。
父类与子类的加载
class Father{
static {
System.out.println("父类静态方法");
}
{
System.out.println("父类非静态方法");
}
Father(){
System.out.println("父类构造函数");
}
}
class Son extends Father{
static {
System.out.println("子类静态方法");
}
{
System.out.println("子类非静态方法");
}
Son(){
System.out.println("子类构造函数");
}
}public static void main(String[] args) {
Father f = new Father();
}父类静态方法
父类非静态方法
父类构造函数
public static void main(String[] args) {
Son s = new Son();
}父类静态方法
子类静态方法
父类非静态方法
父类构造函数
子类非静态方法
子类构造函数
public static void main(String[] args) {
Father f = new Father();
System.out.println("--------------------------");
Son s = new Son();
}
父类静态方法
父类非静态方法
父类构造函数
--------------------------
子类静态方法
父类非静态方法
父类构造函数
子类非静态方法
子类构造函数
顺序:父类静态方法,子类静态方法,父类非静态方法,父类构造函数,子类非静态方法,子类构造函数
ps: 静态代码块的方法仅加载一次
装箱与拆箱
https://www.cnblogs.com/dolphin0520/p/3780005.html
为什么要为每个基本类型对应一个包装类:
因为基本类型并不具有对象的性质,为了让基本类型也具有对象的特征,就出现了包装类型(如我们在使用集合类型Collection时就一定要使用包装类型而非基本类型),它相当于将基本类型“包装起来”,使得它具有了对象的性质,并且为其添加了属性和方法,丰富了基本类型的操作。
对于包装类,主要作用是:1.作为和基本数据类型对应的类类型存在,方便涉及到对象的操作。2.包含每种基本数据类型的相关属性如最大值、最小
基本数据类型: short, int, long, float , double, byte, char, boolean
包装类:Short, Integer, Long, Float, Double, Byte, Character, Boolean
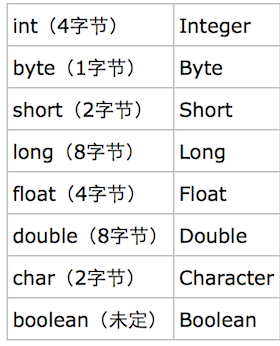
装箱:基本数据类型 -> 包装类
拆箱:包装类 -> 基本数据类型
Integer i = 10; //装箱
int n = i; //拆箱
在装箱的时候自动调用的是Integer的valueOf(int)方法。而在拆箱的时候自动调用的是Integer的intValue方法。
public class Main {
public static void main(String[] args) {
Integer i1 = 100;
Integer i2 = 100;
Integer i3 = 200;
Integer i4 = 200;
System.out.println(i1==i2); // ->true
System.out.println(i3==i4); // ->false
}
}在通过valueOf方法创建Integer对象的时候,如果数值在[-128,127]之间,便返回指向IntegerCache.cache中已经存在的对象的引用;否则创建一个新的Integer对象。上面的代码中i1和i2的数值为100,因此会直接从cache中取已经存在的对象,所以i1和i2指向的是同一个对象,而i3和i4则是分别指向不同的对象。
因为整数型在一定范围内的数是有限的,所以valueOf在一定范围内不创建新对象。而浮点类型则个数是不一定的,所以总是创建新的对象。Boolean总是不创建新的对象。
注意,Integer、Short、Byte、Character、Long这几个类的valueOf方法的实现是类似的。
Double、Float的valueOf方法的实现是类似的。
Integer i = new Integer(xxx)和Integer i =xxx;这两种方式的区别。
当然,这个题目属于比较宽泛类型的。但是要点一定要答上,我总结一下主要有以下这两点区别:
1)第一种方式不会触发自动装箱的过程;而第二种方式会触发;
2)在执行效率和资源占用上的区别。第二种方式的执行效率和资源占用在一般性情况下要优于第一种情况(注意这并不是绝对的)。
当 "=="运算符的两个操作数都是 包装器类型的引用,则是比较指向的是否是同一个对象,而如果其中有一个操作数是表达式(即包含算术运算)则比较的是数值(即会触发自动拆箱的过程)。
对于包装器类型,equals方法并不会进行类型转换。
public class Main {
public static void main(String[] args) {
Integer a = 1;
Integer b = 2;
Integer c = 3;
Integer d = 3;
Integer e = 321;
Integer f = 321;
Long g = 3L;
Long h = 2L;
System.out.println(c==d); //true
System.out.println(e==f); //false
System.out.println(c==(a+b)); //true
System.out.println(c.equals(a+b)); //true
System.out.println(g==(a+b)); //true
System.out.println(g.equals(a+b)); //false
System.out.println(g.equals(a+h)); //true
}
}















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









