




 本文深入探讨了逻辑回归的基本原理、决策边界、成本函数、梯度下降法及其在解决过拟合问题上的应用。通过实例演示了如何通过减少特征数量和规范化来预防模型过拟合,同时介绍了正规化线性回归和正规化逻辑回归的实现方式,以提升模型的泛化能力。
本文深入探讨了逻辑回归的基本原理、决策边界、成本函数、梯度下降法及其在解决过拟合问题上的应用。通过实例演示了如何通过减少特征数量和规范化来预防模型过拟合,同时介绍了正规化线性回归和正规化逻辑回归的实现方式,以提升模型的泛化能力。
Linear Regression (线性回归)考虑的是连续值([0,1]之间的数)的问题,而Logistic Regression(逻辑回归)考虑的是离散值(例如只能取0或1而不能取0到1之间的数)的问题。举个例子,你需要根据以往季度的电力数据,预测下一季度的电力数据,这个时候需要使用的是线性回归,因为这个值是连续的,而不是离散的。而当你需要判断这个人抽烟还是不抽烟的问题时,就需要使用逻辑回归了,因为答案必然是抽烟或不抽烟这其中的一个,也就是离散值。
图一

图解:
第1:对于Email的分类是否是垃圾/不垃圾
第2:在线交易:欺诈/不欺诈
第3:肿瘤:恶性或良性
上面所说的都是分类问题,因为选择是有限个的(都是2个),这个应该很好理解。
通常,将我们所需要得到的定义为正类,另外的定义为负类,但有时也可以随意,并不是严格的。例如,与图中相反的,可以将恶性(malignant)定义为负类(Negative),良性(benign)为正类(Positive)。
图二:
/ 下图给出8个样例/
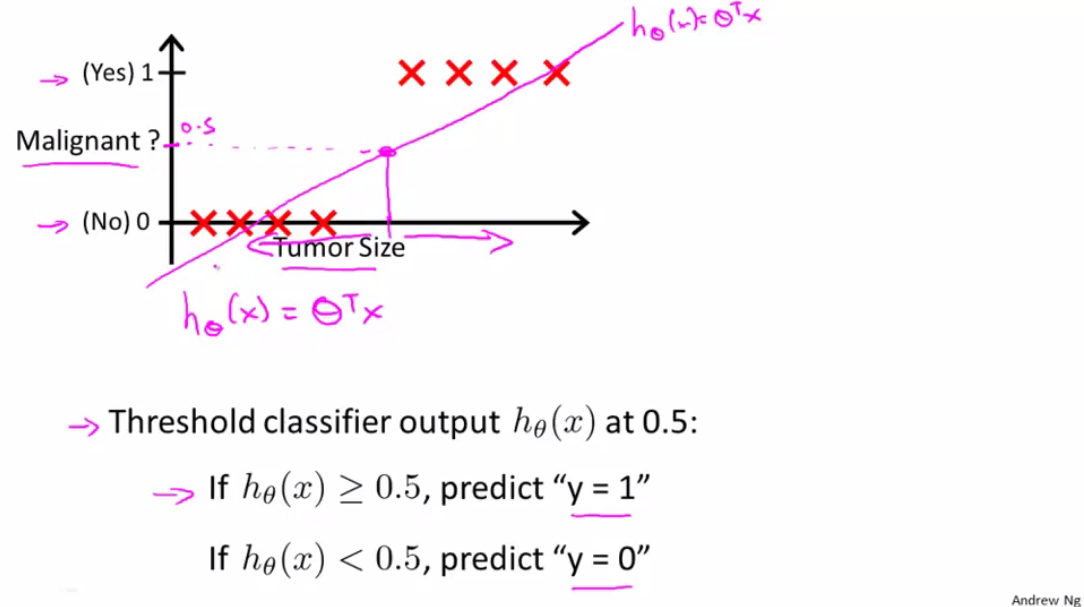
使用线性回归 hθ(x)=θT x,对这8个样例进行拟合,如上图中粉线所示,我们设置一个阈值,当 hθ≥0.5 ,我们将它判定为正类,表示为恶性,当 hθ≤0.5 ,我们将它判定为负类,表示为良性。
即malignant=0.5的点投影下来,其右边的点预测y=1;左边预测y=0;则能够很好地进行分类。
可以这么理解,我们先观看横轴,表示Tumor Size也就是肿瘤大小,越往右边为恶性的可能性也就越大,所以看起来这图还是合理的。
但是,这个时候来了一个新的样本,如下 图三:
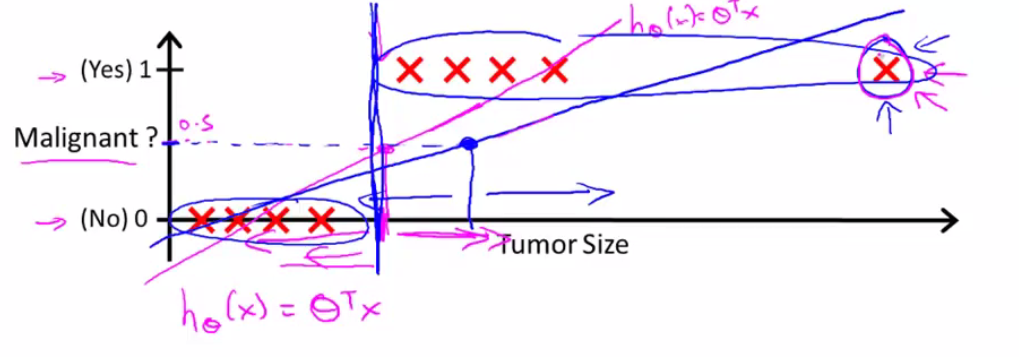
这种情况下,假设linear regression预测由粉红线变为蓝线,那么由0.5的boundary得到的线性方程中,不能很好地进行分类。不满足,
上图,竖直的蓝线本是原本的分割线,左边为良性,右边为恶性,多了一个新样本后,线性回归又拟合出一条新线(蓝线),这样,你再根据上面 hθ(x) 的值来判断,就会将一些本是恶性的归为良性了。
说到这里,应该引入逻辑回归了。
Logistic Regression(逻辑回归)
图四:
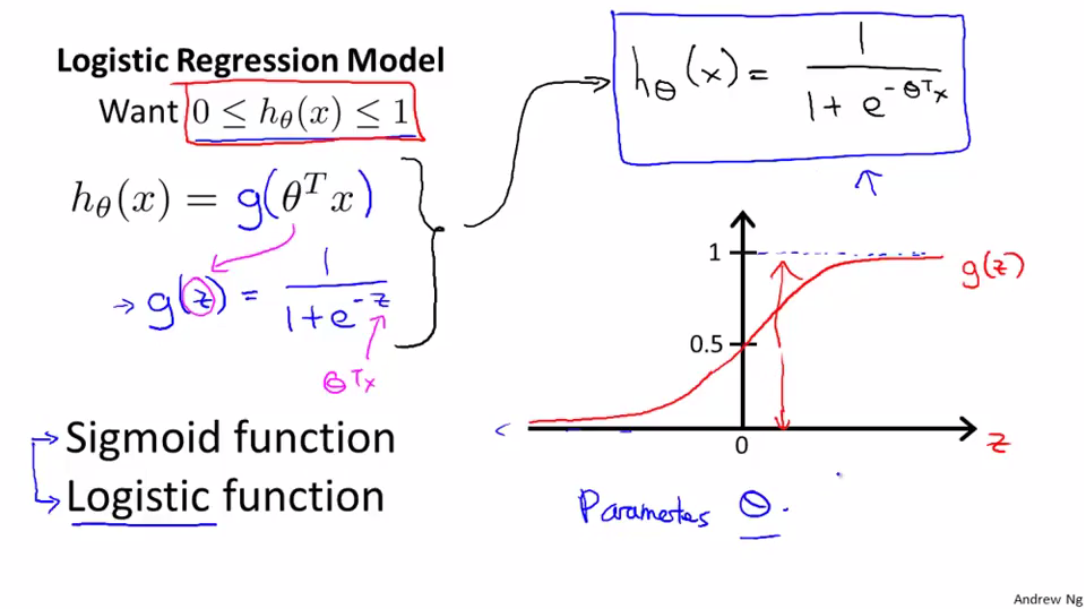
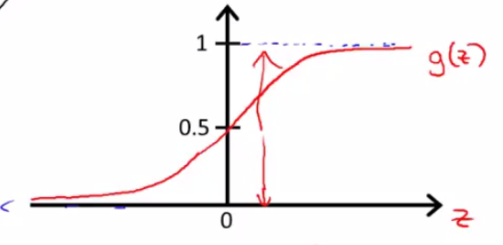
逻辑回归的取值,从图上右侧来看也能得到
仔细观察一下,不就是将原来的线性函数 θTx 通过函数 g 进行映射了么?得到逻辑回归的表达公式:
由下图五,我们可以知道它的性质,在给定 x与θ 的值后, y=1与y=0 的概率之和为1,也就是说不是1就是0的意思
图五
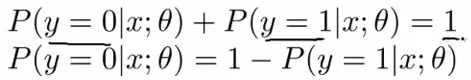
所谓决策边界,其实就是分类边界,如下图所示的粉线,向上则是 y=1 区域 ,向下则是 y=0 区域, 那么问题来了,决策边界是怎么来的?
图六:
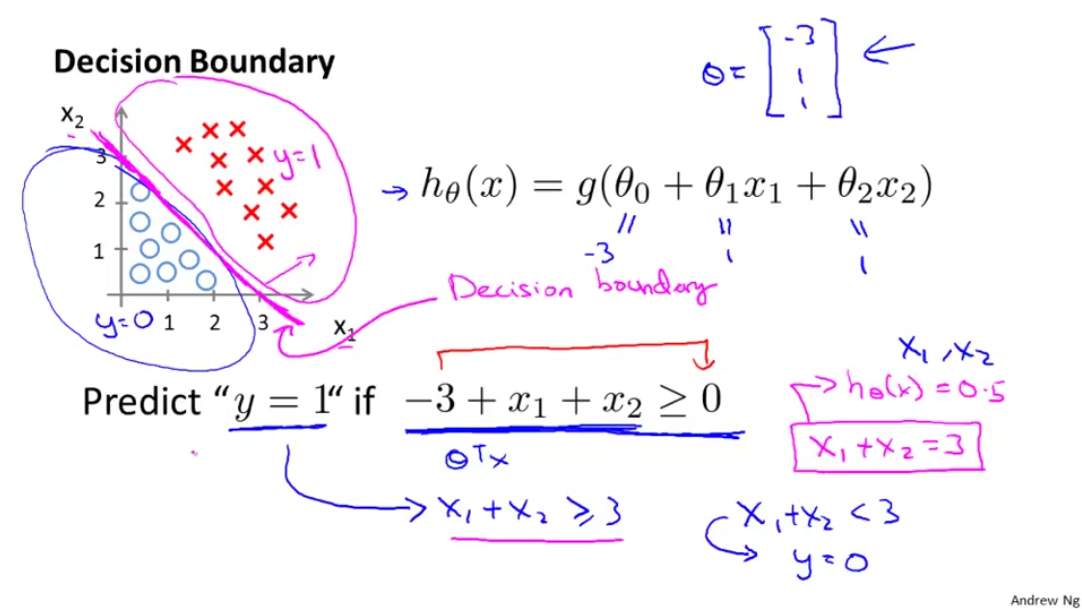
这里先给出了 θT={−3,1,1} 的取值 ,其实 θT 的取值我们是需要通过选择才能得到的,而不是直接给出,这里只是为了更好的理解而直接给出的, 我们得到 hθ(x)=g(−3+x1+x2) ,回顾一下上面所讲的逻辑回归:
图七:
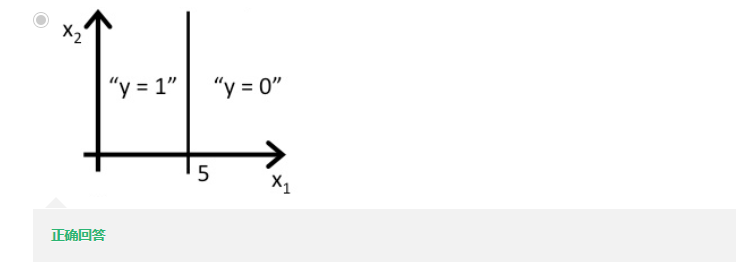
我们来看一个例题:

根据上面所讲,将
θT={5,−1,0}
代入,得到
5−x1
,当
5−x1≥0
时,也就是
x1≤5
时,
y=1
,得到:
当然,决策边界并不一定都是线性的,还有非线性的,我们来看这么一个例子:
图八

按照上面所讲,将
θT={−1,0,0,1,1}
代入得到
hθ(x)=g(x21+x22−1)
,令
x21+x22−1≥0
得到一个半径为1的圆,为决策边界,圆的内侧为
y=0
区域,外侧为
y=1
区域
图九:

当 y=1,Cost(hθ(x),y)=−log(hθ(x)) 如下图十所示:
图十:

当
hθ(x)其实为0的时候,而给出的结果却是1,则会给一个惩罚∞;相应的,如果hθ(x)=1,并且样本标签也为1,则cost=0,即代价为0
当
y=0,Cost(hθ(x),y)=−log(1−hθ(x))
如下图所示:
图十一
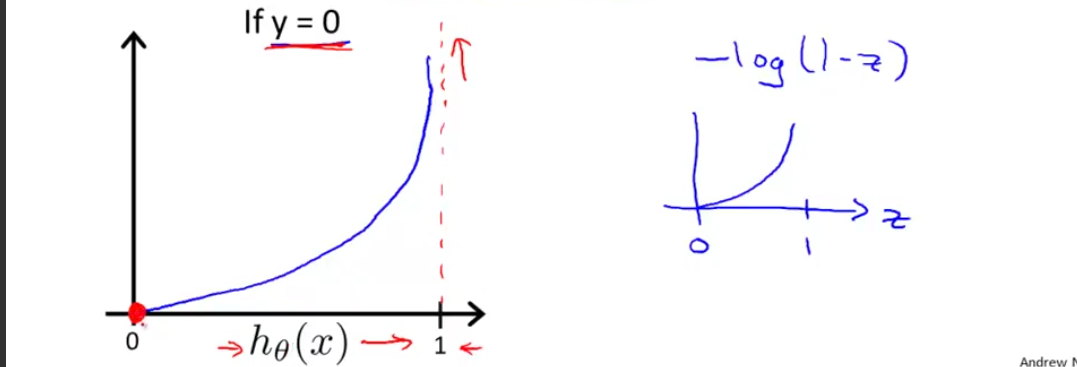
当
hθ(x)其实为1的时候,而给出的结果却是0,则会给一个惩罚∞;相应的,如果hθ(x)=0,并且样本标签也为0,则cost=0,即代价为0
插一句话:为什么不写成Linear Regression Cost Function形式?
图十二:
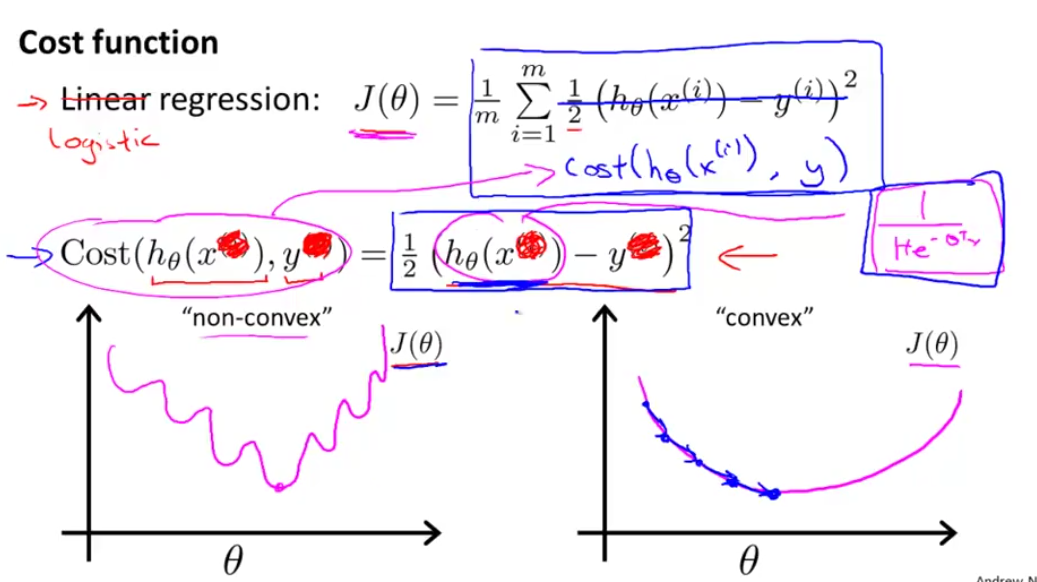
如果写成线性回归的Cost则会出现非凸函数形式(non-convex),在利用梯度下降的时候,不利于得到全局最解
图十三:
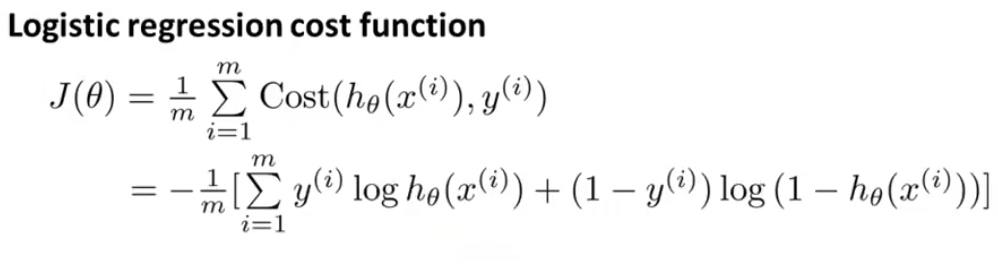
因为取值为{0,1},所以可以写成上图这种形式,不信你可以另y=0或1看看。
现在我们知道了CostFunction,剩下的工作就是如何去 minJ(θ) 中的 θ 了
图十四:
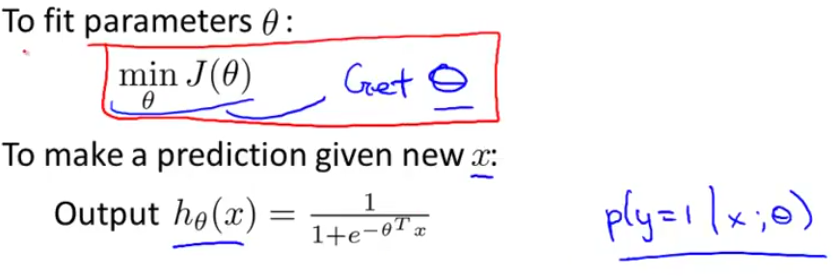
这里使用的还是Gradient Descent, 也就是下图Repeat中的部分,
图十五:

上式中求解对
J(θ)
的偏导如下:
图十六:
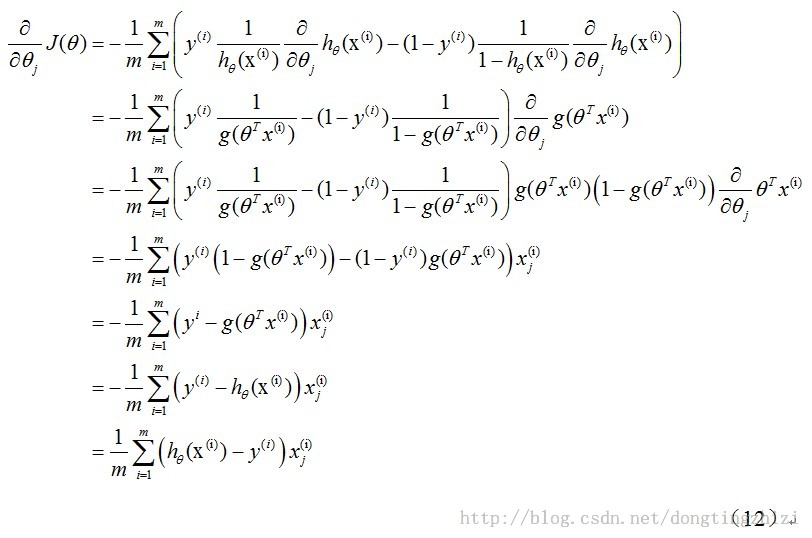
上述求解过程用到如下公式:
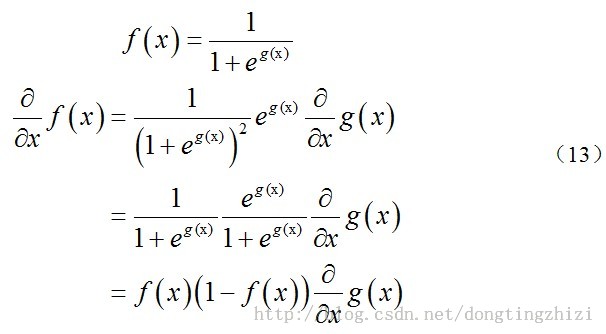
将θ中所有维同时进行更新,而J(θ)的导数可以由下面的式子求得,结果如下图手写所示:
图十七:

通过观察,这个更新式子跟线性回归的很相似,但要注意
hθ(x(i))
所代表的式子并不一样。
例题1:
那么如何用vectorization来做呢?换言之,我们不要用for循环一个个更新θj,而用一个矩阵乘法同时更新整个θ。也就是解决下面这个问题:


例题2:
如何判断学习率α大小是否合适,那么在logistic regression系统中怎么评判呢?


除了gradient descent 方法之外,我们还有很多方法可以使用,如下图所示,左边是另外三种方法,右边是这三种方法共同的优缺点,无需选择学习率α,更快,但是更复杂。
图十八:

后二者由拟牛顿法引申出来,与梯度下降算法相比,这些算法的优点是:
第一,不需要手动的选择步长;
第二,通常比梯度下降算法快;
但是缺点是更复杂-更复杂也是缺点吗?其实也算不上,关于这些优化算法,推荐有兴趣的同学看看52nlp上这个系列的文章:无约束最优化,更深入的了解可以参考这篇文章中推荐的两本书:
用于解无约束优化算法的Quasi-Newton Method中的LBFGS算法到这里总算初步介绍完了,不过这里笔者要承认的是这篇文档省略了许多内容,包括算法收敛性的证明以及收敛速度证明等许多内容。因此读者若希望对这一块有一个更深入的认识可以参考以下两本书:
1) Numerical Methods for Unconstrained Optimization and Nonlinear Equations(J.E. Dennis Jr. Robert B. Schnabel)
2) Numerical Optimization(Jorge Nocedal Stephen J. Wright)
所谓的多类分类器,就是将二分分类器应用于多类而已。
图十九:
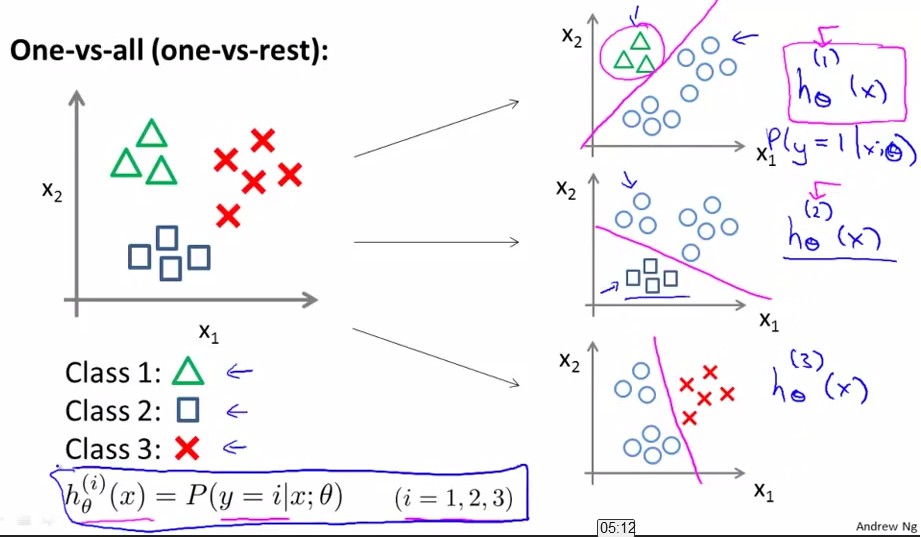
比如我想分成K类,那么就将其中一类作为positive,另(k-1)合起来作为negative,这样进行K个
h(θ)
的参数优化,每次得到的一个
hθ(x)
是指给定
θ
和
x
,它属于positive的类的概率。
例如:我将class1看成正例,那么class2与class3看成负例;相同的,将class2看成正例,class1与class3看成负例。。
按照上面这种方法,给定一个输入向量x,获得最大
图二十:

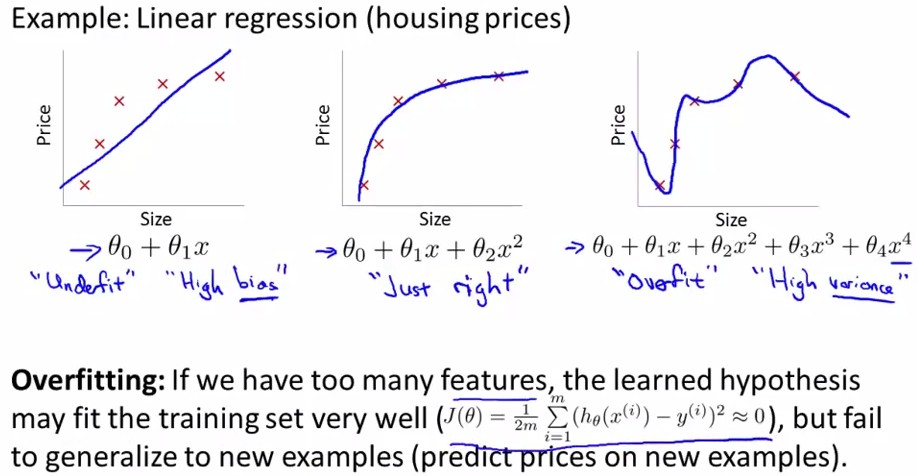
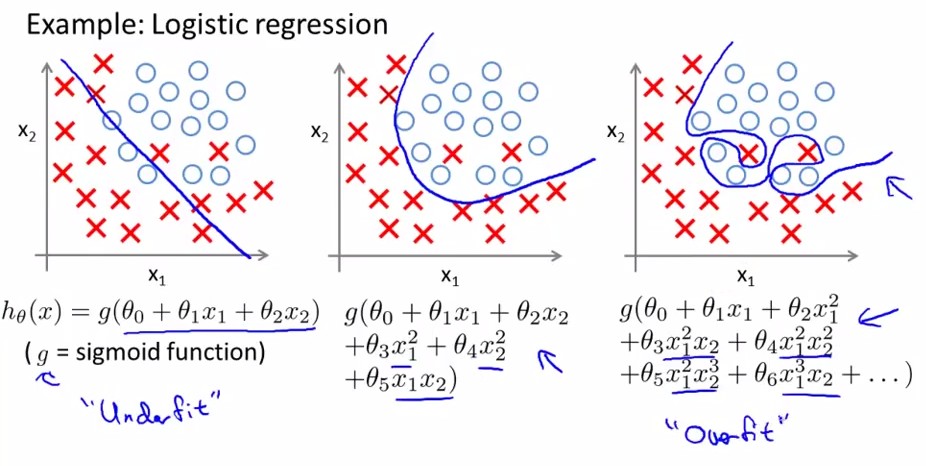
overfitting就是过拟合,简单点来说,就是对Training Set有很好的训练效果,能够完全拟合它,但是模型的泛化能力不行,比如来了一个新数据需要进行预测,得到的结果往往比较差。如下图中最右边的那幅图。对于以上讲述的两类(logistic regression和linear regression)都有overfitting的问题,下面分别用两幅图进行解释:
Linear Regression:
图二十一:
Logistic Regression:
图二十二:
如何解决过拟合问题?
图二十三:

1. 减少feature个数(人工定义留多少个feature、算法选取这些feature)
2. 规格化(留下所有的feature,但对于部分feature定义其parameter非常小)
先来看看下图,我们发现如果 θ3,θ4 的parameter非常大,那么最小化cost function后就有非常小的 θ3,θ4 了
图二十四:
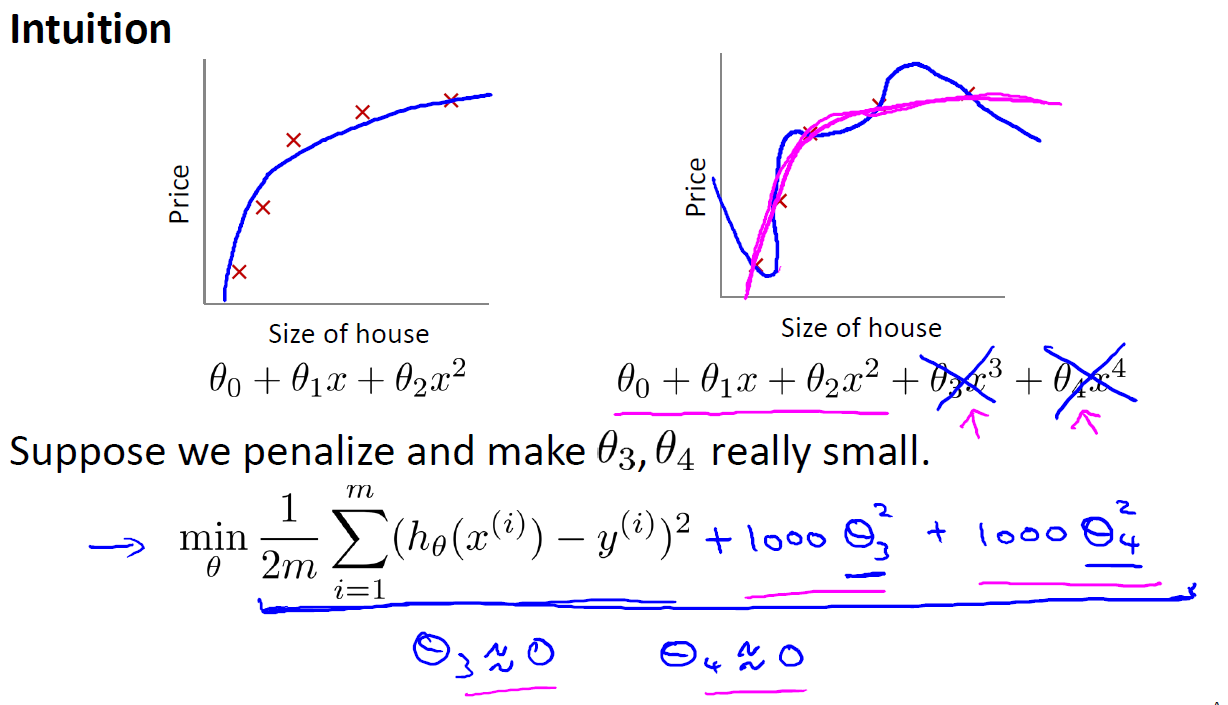
注意 λ 的设置,不能过大,若是过大则会引起欠拟合问题,如下图所示:
图二十五:

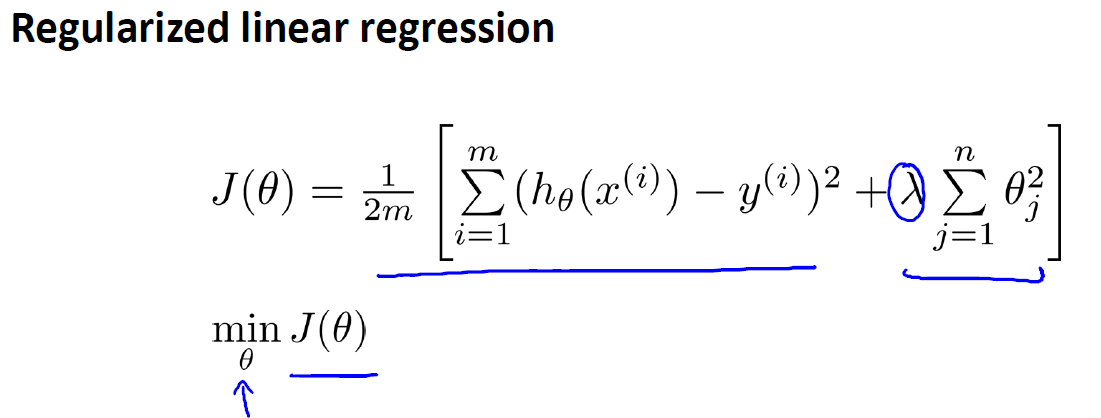
对于 θ0 ,没有惩罚项,更新公式跟原来一样
对于其他
θj,J(θ)
,对其求导后还要加上一项
(λ/m)∗θj
,见下图:
图二十六:

如果不使用梯度下降法(gradient descent+regularization),而是用矩阵计算(normal equation)来求
θ
,也就求使
J(θ)
min的
θ
,令
J(θ)
对
θj
求导的所有导数等于0,有公式如下:
图二十七:

就是在原来的Cost Function上加上一个参数惩罚项
图二十八:
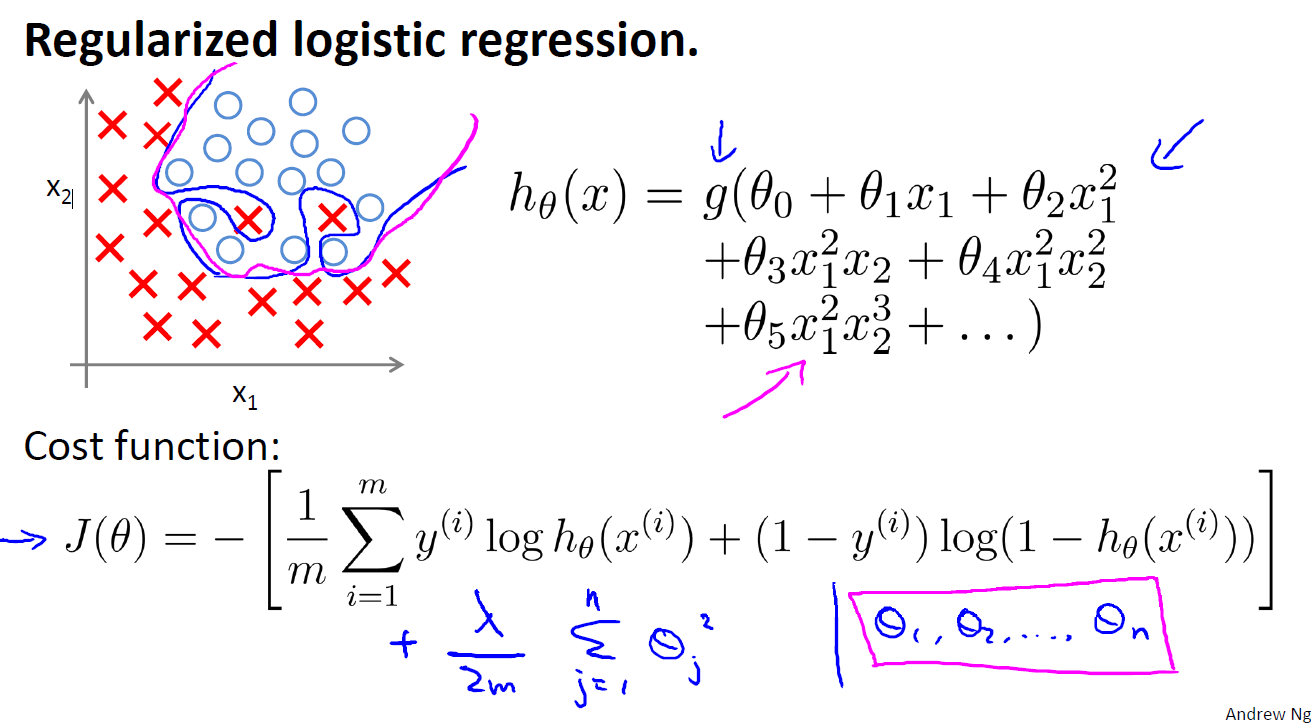
这里我们发现,其实和线性回归的θ更新方法是一样的
图二十九:

图三十:

图三十中,jval表示cost function 表达式,其中最后一项是参数 θ 的惩罚项;下面是对各 θj 求导的梯度,其中 θ0 没有在惩罚项中,因此gradient不变, θ1∼θn 分别多了一项 (λ/m)∗θj ;
至此,regularization可以解决linear和logistic的overfitting regression问题了~
参考内容:

















 6001
6001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









