




前言
数据库故障恢复就是把数据库从错误状态恢复到某一已知的正确状态(亦称为一致状态或完整状态)。
一、故障的种类
1、事务故障
- 逻辑故障,例如:除以0;
- 余额不允许为负。
2、系统崩溃故障
- 停电、硬件故障,蓝屏死机故障。
3、磁盘故障
- 分为数据库磁盘故障和日志磁盘故障。
4、灾难故障
- 例如:地震,火灾等不可抗因素。
二、故障恢复方法
主要讲述常用的日志方法,分页方法因为很少使用,有兴趣可以自行查阅资料。
1、事务故障的恢复:撤消事务(UNDO)
具体方法:
(1). 反向扫描文件日志(即从最后向前扫描日志文件),查找该事务的更新操作。
(2). 对该事务的更新操作执行逆操作。即将日志记录中“更新前的值” 写入数据库。
插入操作, “更新前的值”为空,则相当于做删除操作
删除操作,“更新后的值”为空,则相当于做插入操作
若是修改操作,则相当于用修改前值代替修改后值
(3). 继续反向扫描日志文件,查找该事务的其他更新操作,并做同样处理。
(4). 如此处理下去,直至读到此事务的开始标记,事务故障恢复就完成了。
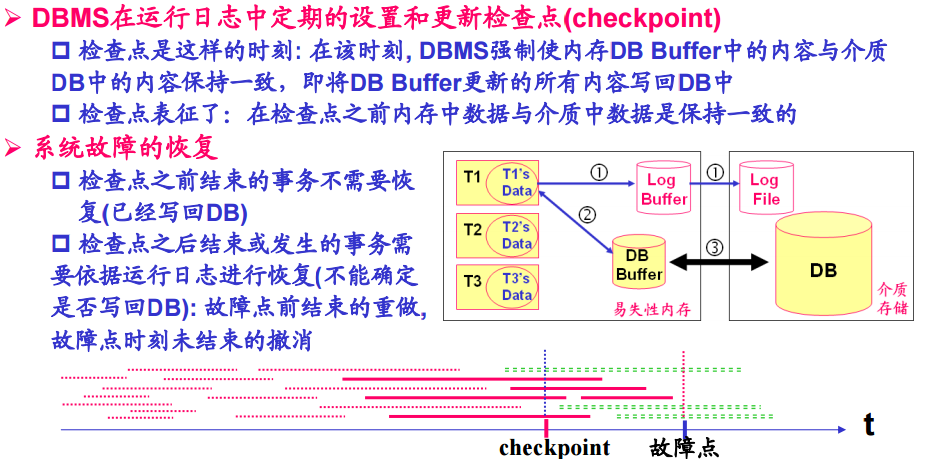
2、系统崩溃故障的恢复
发生系统故障时,事务未提交
恢复策略:强行撤消(UNDO)所有未完成事务
发生系统故障时,事务已提交,但缓冲区中的信息尚未完全写回到磁盘上。
恢复策略:重做(REDO)所有已提交的事务
具体方法:
重启数据库管理系统;从日志磁盘读取日志文件;反向扫描日志,也就是从日志文件的结束位置开始后向扫描。当发现一个事务在日志记录中没有 记录时,执行undo( Ti) 操作,使用旧值恢复数据项: 然后从日志文件的开始位置顺向扫描。对日志记录中含有的事务,执行redo( Ti) 操作,使用新值恢复数据项;
新的问题来了,运行日志保留了若干天的记录,扫描整个日志文件很费时,如何解决?
解决方法
周期性的做检查点(checkpointing)
更详细讲解请跳转至
数据库故障恢复
3、磁盘(介质)故障的恢复
数据库磁盘故障,把dump的备份数据库文件拷贝到新的数据库磁盘上;从日志文件的末尾逆向扫描直至记录,再顺向扫描日志记录,对有日志记录的事务做redo(Ti)操作。
日志磁盘故障:不再接收事务请求,让当前的所有活动事务执行完毕;输出数据库缓冲区中的缓冲数据到数据库磁盘中(即checkpoint);执行Dump操作,把磁盘中的数据库文件拷贝到另一个磁盘上;更换日志磁盘。

4、灾难故障的恢复:远程备份
三、小结
事务故障的恢复
UNDO
系统故障的恢复
UNDO + REDO
介质故障的恢复
重装备份并恢复到一致性状态 + REDO
灾难故障的恢复
远程备份
以上为个人的学习总结,有不妥之处,请在评论中指出。

















 1820
1820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









