






超时原因,注释内为超时代码
for(i=begin;i<=end;i++){
/*
if(i<mid&&(a[mid].x-a[i].x)<midmin)
b[cout1++]=a[i];
if(i>mid&&(a[i].x-a[mid].x)<midmin)
c[cout2++]=a[i];
*/
if ( fabs ( a[i].x - a[mid].x ) <= midmin)
{
if (a[i].x-a[mid].x < 0)
c[cout1++]=a[i];
else
b[cout2++]=a[i];
}
}
超时代码1
#include <stdio.h>
#include <math.h>
#include <malloc.h>
typedef struct Position{
double x;
double y;
struct Position *next;
}Position;
double Distance(Position *i,Position *j){
return sqrt((i->x-j->x)*(i->x-j->x)+(i->y-j->y)*(i->y-j->y));
}
int main(){
int n;
double max;
double radius;
Position *head;
Position *i;
Position *j;
while(scanf("%d",&n)!=EOF&&n!=0){
head=j=i=(Position *)malloc(sizeof(Position));
scanf("%lf %lf",&j->x,&j->y);
i=j->next=(Position *)malloc(sizeof(Position));
scanf("%lf %lf",&i->x,&i->y);
i->next=NULL;
max=Distance(i,j);
n-=2;
while(n--){
j=i;
j->next=i=(Position *)malloc(sizeof(Position));
scanf("%lf %lf",&i->x,&i->y);
i->next=NULL;
}
for(i=head;i->next!=NULL;i=i->next){
for(j=i->next;j!=NULL;j=j->next){
if(Distance(i,j)<max)
max=Distance(i,j);
}
}
radius=max/2;
printf("%.2f\n",radius);
for(i=head;i!=NULL;){
j=i->next;
free(i);
i=j;
}
}
return 0;
}
超时代码2
#include<iostream>
#include <stdlib.h>
#include<cmath>
#include<algorithm>
using namespace std;
#define N 100001
typedef struct Point{
double x;
double y;
}Point;
Point a[N];
Point b[N];
Point c[N];
bool cmpup(Point a,Point b){
return a.x<b.x;
}
double min(double x,double y){
return x<y?x:y;
}
double dis(Point a,Point b){
return sqrt(pow(a.x-b.x,2)+pow(a.y-b.y,2));
}
double minRadius(int begin,int end){
if(begin==end-1)
return dis(a[begin],a[end]);
if(begin==end-2)
return min( min(dis(a[begin],a[begin+1]), dis(a[begin],a[end])), dis(a[begin+1],a[end]));
else{
int mid;
double midmin;
int cout1=0;
int cout2=0;
int i,j;
mid=(begin+end)/2;
midmin=min(minRadius(begin,mid),minRadius(mid+1,end));
for(i=begin;i<=end;i++){
if(i<mid&&(a[mid].x-a[i].x)<midmin)
b[cout1++]=a[i];
if(i>mid&&(a[i].x-a[mid].x)<midmin)
c[cout2++]=a[i];
}
for(i=0;i<cout1;i++){
for(j=0;j<cout2;j++){
midmin=min(dis(b[i],c[j]),midmin);
}
}
return midmin;
}
}
int main(){
int n;
while(scanf("%d",&n)==1&&n){
for(int i=0;i<n;i++)
scanf("%lf %lf",&a[i].x,&a[i].y);
sort(a,a+n-1,cmpup);
printf("%.2f\n",minRadius(0,n-1)/2);
}
return 0;
}
成功:
- #include<iostream>
- #include<cmath>
- #include<cstring>
- #include<cstdlib>
- #include<cstdio>
- using namespace std;
- const int N=1000000;
- const double eps=0.00001; //精度
- typedef struct TYPE
- {
- double x,y;
- int index;
- } Point; //存每点的坐标和索引值
- Point a[N],b[N],c[N];
- inline double min(double p,double q)
- {
- return p>q?q:p;
- }
- double dis(Point p,Point q)
- {
- double x1=p.x-q.x,y1=p.y-q.y;
- return sqrt(x1*x1+y1*y1);
- }
- int merge(Point p[],Point q[],int s,int m,int t) //将数组q保存到p,且对y升序排序
- {
- int i,j,k;
- for(i=s,j=m+1,k=s;i<=m&&j<=t;)
- {
- if(q[i].y>q[j].y)
- p[k++]=q[j++];
- else
- p[k++]=q[i++];
- }
- while(i<=m)
- p[k++]=q[i++];
- while(j<=t)
- p[k++]=q[j++];
- memcpy(q+s,p+s,(t-s+1)*sizeof(p[0]));
- return 0;
- }
- double closest(Point a[],Point b[],Point c[],int p,int q)
- {
- if(q-p==1)
- return dis(a[p],a[q]);
- else if(q-p==2)
- {
- double x1=dis(a[p],a[q]);
- double x2=dis(a[p+1],a[q]);
- double x3=dis(a[p],a[p+1]);
- if(x1<x2&&x1<x3)
- return x1;
- else if(x2<x3)
- return x2;
- else
- return x3;
- }
- int m=(p+q)/2;
- int i,j,k;
- double d1,d2;
- for(i=p,j=p,k=m+1;i<=q;i++)
- if(b[i].index<=m)
- c[j++]=b[i]; //数组左半部分保存划分的左部,对y升序的
- else
- c[k++]=b[i]; //数组右半部分保存划分的右部,对y升序的
- d1=closest(a,c,b,p,m);
- d2=closest(a,c,b,m+1,q);
- double dm=min(d1,d2);
- merge(b,c,p,m,q); //将数组c保存到b,且对y升序的
- for(i=p,k=p;i<=q;i++)
- if(fabs(b[i].x-b[m].x)<dm)
- c[k++]=b[i]; //将离划分线b[m].x距离不超过dm的部分保存到数组c
- for(i=p;i<k;i++)
- for(j=i+1;j<k&&c[j].y-c[i].y<dm;j++)
- {
- double temp=dis(c[i],c[j]);
- if(temp<dm)
- dm=temp;
- }
- return dm;
- }
- int cmp_x(const void *p,const void *q) //按x升序排序
- {
- double temp=((Point*)p)->x-((Point*)q)->x;
- if(temp>0)
- return 1;
- else if(fabs(temp)<eps)
- return 0;
- else
- return -1;
- }
- int cmp_y(const void *p,const void *q) //按y升序排序
- {
- double temp=((Point*)p)->y-((Point*)q)->y;
- if(temp>0)
- return 1;
- else if(fabs(temp)<eps)
- return 0;
- else
- return -1;
- }
- int main()
- {
- int n,i;
- double d;
- while(scanf("%d",&n)!=EOF&&n)
- {
- for(i=0;i<n;i++)
- scanf("%lf %lf",&(a[i].x),&(a[i].y));
- qsort(a,n,sizeof(a[0]),cmp_x); //对a按x升序排序
- for(i=0;i<n;i++)
- a[i].index=i;
- memcpy(b,a,n*sizeof(a[0]));
- qsort(b,n,sizeof(b[0]),cmp_y); //对b按y升序排序
- d=closest(a,b,c,0,n-1); //求最近点对的距离
- printf("%.2lf\n",d/2);
- }
- return 0;
- }
-
HDOJ1007的原题目是求出在不同时套中两个玩具的前提下,圆圈的最大半径。问题翻译过来就是求解最近点对的问题,这个问题是经典的分治法问题。
参考博客:http://www.cnblogs.com/peng-come-on/archive/2012/01/18/2325163.html
毫无疑问,通过暴力手段列举所有的点对并计算这些点对的距离,找出最小的一组,可以得到最后的结果。但是,这道题的数据规模非常大,所以,这种传统的方法肯定行不通。我试过,hdoj是超时的。
我对原博客的第3步和第4步有不同的看法。
原博客步骤:
1.读取数据,并将点按横坐标升序排列。
2.以最中间的那个点为基准,将平面内的点分为左右两个部分。递归调用mindis(int,int)函数,分别求出左右两个部分的点集的最短距离,并取两者中的较小值,即为min.
3.显然,min并不一定是最短距离,因为还可能存在一种情况,即点对中的一个点位于左区域,另一个点位于右区域。所以,我们取点集中横坐标与分界线的距离小于min的点,存入p2[N]数组中。
4.对p2[N]数组中的点按纵坐标进行排序,计算p2[N]数组中的点对的距离,如果存在小于min 的情况,就取代min作为最近距离。
最后,min即为平面内点集的最近距离。我的步骤是:
1.读取数据,并将点按横坐标升序排列。
2.以最中间的那个点为基准,将平面内的点分为左右两个部分。递归调用mindis(int,int)函数,分别求出左右两个部分的点集的最短距离,并取两者中的较小值,即为min.
3.显然,min并不一定是最短距离,因为还可能存在一种情况,即点对中的一个点位于左区域,另一个点位于右区域。所以,我们取点集中横坐标与分界线的距离小于min的点,根据在分界线的左右,分别存入pxSmall[N]数组和pxLarge[N]数组中。4.因为唯一可能的情况是一个点在pxSmall[N],另一个点在pxLarge[N]中。只要遍历这个两个数组便可以了。
下面是在原博客代码上的修改:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101#include<iostream>#include<cstdio>#include<cmath>#include<algorithm>usingnamespacestd;#define N 1000010structpoint{doublex;doubley;}p1[N],pxSmall[N],pxLarge[N];doubledis ( point a , point b ){returnsqrt(pow(a.x-b.x,2) +pow( a.y-b.y,2 ) );}doublemin (doublea ,doubleb ){returna<b?a:b;}boolcpx ( point a , point b ){returna.x < b.x ;}boolcpy ( point a , point b ){returna.y < b.y ;}doublemindis (intl,intr){if( l + 1 == r )returndis ( p1[l] ,p1[r] );if( l + 2 == r )returnmin ( dis ( p1[l] , p1[l+1] ) , min ( dis ( p1[l+1] , p1[r] ) , dis ( p1[l] , p1[r] ) ) );else{intmid ,count1=0, count2=0;doublemini;mid = ( l + r) >> 1 ;mini = min ( mindis ( l , mid ) , mindis ( mid+1 , r ) );for(inti = l ; i <= r ; i++ ){if(fabs( p1[i].x - p1[mid].x ) <= mini ){if(p1[i].x-p1[mid].x < 0)pxSmall[count1++]=p1[i];elsepxLarge[count2++]=p1[i];}}//直接遍历两个数组for(inti=0;i<count1;i++){for(intj=0;j<count2;j++){doubletemp = dis(pxSmall[i], pxLarge[j]);if(temp<mini)mini=temp;}}/*sort ( p2 , p2+count , cpy );for ( int i=0 ; i < count ; i++ ){for ( int j = i+1; j < count ;j++){if ( p2[j].y-p2[i].y>=mini)break;else if(dis (p2[j],p2[i])<mini)mini=dis(p2[j],p2[i]);}}*/returnmini;}}intmain(){//freopen("input.txt","r",stdin);intn ;doubledia ;while(scanf("%d",&n)==1&&n){for(inti=0;i<n;i++)scanf("%lf%lf",&p1[i].x,&p1[i].y);sort ( p1 , p1 + n-1 , cpx );dia = mindis ( 0 , n-1 );printf("%.2f\n", dia / 2 );}return0;}我在HDOJ上分别跑这两组代码,发现原博客runtime为1875ms,我的代码runtime为1093ms,比原博客的运行时间少了很多。因为少了排序这个步骤。当然,可能不同的数据集得到的运行时间不同,如果换一个数据集或数据集规模很大的时候原博客的方法可能更有优势。但是有一点,我的方法更好地符合分治法的要求,正确性是可以保证的。最近一直在学习《算法导论》,这本书真是神书,是算法中的算法,不仅仅告诉你算法,还会告诉你算法的证明。以后如果遇到分治法的问题,我会继续补充到这篇博客。
补充:参考博客:http://blog.csdn.net/junerfsoft/article/details/2975495
博客中提到了飞机调度的问题,说的很好。可惜因为每个点的坐标类型都是double类型的,不能直接找到那6个点,可以使用二分查找,但是也不是特别方便。我随便写了代码,时间上反而更长了。
-
问题描述
在应用中,常用诸如点、圆等简单的几何对象代表现实世界中的实体。在涉及这些几何对象的问题中,常需要了解其邻域中其他几何对象的信息。例如,在空中交通控制问题中,若将飞机作为空间中移动的一个点来看待,则具有最大碰撞危险的2架飞机,就是这个空间中最接近的一对点。这类问题是计算几何学中研究的基本问题之一。下面我们着重考虑平面上的最接近点对问题。
最接近点对问题的提法是:给定平面上n个点,找其中的一对点,使得在n个点的所有点对中,该点对的距离最小。
严格地说,最接近点对可能多于1对。为了简单起见,这里只限于找其中的一对。
参考解答
这个问题很容易理解,似乎也不难解决。我们只要将每一点与其他n-1个点的距离算出,找出达到最小距离的两个点即可。然而,这样做效率太低,需要O(n2)的计算时间。在问题的计算复杂性中我们可以看到,该问题的计算时间下界为Ω(nlogn)。这个下界引导我们去找问题的一个θ(nlogn)算法。
这个问题显然满足分治法的第一个和第二个适用条件,我们考虑将所给的平面上n个点的集合S分成2个子集S1和S2,每个子集中约有n/2个点,·然后在每个子集中递归地求其最接近的点对。在这里,一个关键的问题是如何实现分治法中的合并步骤,即由S1和S2的最接近点对,如何求得原集合S中的最接近点对,因为S1和S2的最接近点对未必就是S的最接近点对。如果组成S的最接近点对的2个点都在S1中或都在S2中,则问题很容易解决。但是,如果这2个点分别在S1和S2中,则对于S1中任一点p,S2中最多只有n/2个点与它构成最接近点对的候选者,仍需做n2/4次计算和比较才能确定S的最接近点对。因此,依此思路,合并步骤耗时为O(n2)。整个算法所需计算时间T(n)应满足:
T(n)=2T(n/2)+O(n2)
它的解为T(n)=O(n2),即与合并步骤的耗时同阶,显示不出比用穷举的方法好。从解递归方程的套用公式法,我们看到问题出在合并步骤耗时太多。这启发我们把注意力放在合并步骤上。
为了使问题易于理解和分析,我们先来考虑一维的情形。此时S中的n个点退化为x轴上的n个实数x1,x2,..,xn。最接近点对即为这n个实数中相差最小的2个实数。我们显然可以先将x1,x2,..,xn排好序,然后,用一次线性扫描就可以找出最接近点对。这种方法主要计算时间花在排序上,因此如在排序算法中所证明的,耗时为O(nlogn)。然而这种方法无法直接推广到二维的情形。因此,对这种一维的简单情形,我们还是尝试用分治法来求解,并希望能推广到二维的情形。
假设我们用x轴上某个点m将S划分为2个子集S1和S2,使得S1={x∈S|x≤m};S2={x∈S|x>m}。这样一来,对于所有p∈S1和q∈S2有p
递归地在S1和S2上找出其最接近点对{p1,p2}和{q1,q2},并设δ=min{|p1-p2|,|q1-q2|},S中的最接近点对或者是{p1,p2},或者是{q1,q2},或者是某个{p3,q3},其中p3∈S1且q3∈S2。如图1所示。
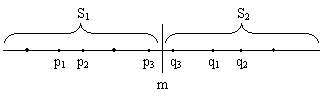 图1 一维情形的分治法
图1 一维情形的分治法我们注意到,如果S的最接近点对是{p3,q3},即|p3-q3|<δ,则p3和q3两者与m的距离不超过δ,即|p3-m|<δ,|q3-m|<δ,也就是说,p3∈(m-δ,m],q3∈(m,m+δ]。由于在S1中,每个长度为δ的半闭区间至多包含一个点(否则必有两点距离小于δ),并且m是S1和S2的分割点,因此(m-δ,m]中至多包含S中的一个点。同理,(m,m+δ]中也至多包含S中的一个点。由图1可以看出,如果(m-δ,m]中有S中的点,则此点就是S1中最大点。同理,如果(m,m+δ]中有S中的点,则此点就是S2中最小点。因此,我们用线性时间就能找到区间(m-δ,m]和(m,m+δ]中所有点,即p3和q3。从而我们用线性时间就可以将S1的解和S2的解合并成为S的解。也就是说,按这种分治策略,合并步可在O(n)时间内完成。这样是否就可以得到一个有效的算法了呢?还有一个问题需要认真考虑,即分割点m的选取,及S1和S2的划分。选取分割点m的一个基本要求是由此导出集合S的一个线性分割,即S=S1∪S2 ,S1∩S2=Φ,且S1{x|x≤m};S2{x|x>m}。容易看出,如果选取m=[max(S)+min(S)]/2,可以满足线性分割的要求。选取分割点后,再用O(n)时间即可将S划分成S1={x∈S|x≤m}和S2={x∈S|x>m}。然而,这样选取分割点m,有可能造成划分出的子集S1和S2的不平衡。例如在最坏情况下,|S1|=1,|S2|=n-1,由此产生的分治法在最坏情况下所需的计算时间T(n)应满足递归方程:
T(n)=T(n-1)+O(n)
它的解是T(n)=O(n2)。这种效率降低的现象可以通过分治法中"平衡子问题"的方法加以解决。也就是说,我们可以通过适当选择分割点m,使S1和S2中有大致相等个数的点。自然地,我们会想到用S的n个点的坐标的中位数来作分割点。在选择算法中介绍的选取中位数的线性时间算法使我们可以在O(n)时间内确定一个平衡的分割点m。
至此,我们可以设计出一个求一维点集S中最接近点对的距离的算法CPAIR1如下。
function CPAIR1(S);
begin
if |S|=2
then δ=|x[2]-x[1]| // x[1..n]存放的是S中n个点的坐标
else if (|S|=1)
then δ:=∞
else
begin
m:=S中各点的坐标值的中位数;
构造S1和S2,使S1={x∈S|x≤m},S2={x∈S|x>m}; δ1:=CPAIRI(S1); δ2:=CPAIRI(S2);
p:=max(S1); q:=min(S2);
δ:=min(δ1,δ2,q-p);
end;
return(δ);
end;
由以上的分析可知,该算法的分割步骤和合并步骤总共耗时O(n)。因此,算法耗费的计算时间T(n)满足递归方程:
解此递归方程可得T(n)=O(nlogn)。
这个算法看上去比用排序加扫描的算法复杂,然而这个算法可以向二维推广。
下面我们来考虑二维的情形。此时S中的点为平面上的点,它们都有2个坐标值x和y。为了将平面上点集S线性分割为大小大致相等的2个子集S1和S2,我们选取一垂直线l:x=m来作为分割直线。其中m为S中各点x坐标的中位数。由此将S分割为S1={p∈S|px≤m}和S2={p∈S|px>m}。从而使S1和S2分别位于直线l的左侧和右侧,且S=S1∪S2 。由于m是S中各点x坐标值的中位数,因此S1和S2中的点数大致相等。
递归地在S1和S2上解最接近点对问题,我们分别得到S1和S2中的最小距离δ1和δ2。现设δ=min(δ1,δ1)。若S的最接近点对(p,q)之间的距离d(p,q)<δ则p和q必分属于S1和S2。不妨设p∈S1,q∈S2。那么p和q距直线l的距离均小于δ。因此,我们若用P1和P2分别表示直线l的左边和右边的宽为δ的2个垂直长条,则p∈P1,q∈P2,如图2所示。
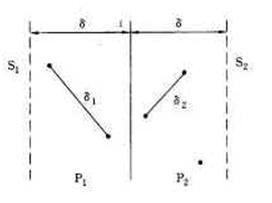
图2 距直线l的距离小于δ的所有点
在一维的情形,距分割点距离为δ的2个区间(m-δ,m](m,m+δ]中最多各有S中一个点。因而这2点成为唯一的末检查过的最接近点对候选者。二维的情形则要复杂些,此时,P1中所有点与P2中所有点构成的点对均为最接近点对的候选者。在最坏情况下有n2/4对这样的候选者。但是P1和P2中的点具有以下的稀疏性质,它使我们不必检查所有这n2/4对候选者。考虑P1中任意一点p,它若与P2中的点q构成最接近点对的候选者,则必有d(p,q)<δ。满足这个条件的P2中的点有多少个呢?容易看出这样的点一定落在一个δ×2δ的矩形R中,如图3所示。
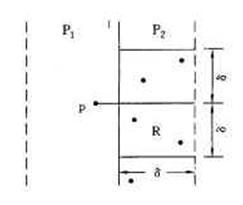 图3 包含点q的δ×2δ的矩形R
图3 包含点q的δ×2δ的矩形R由δ的意义可知P2中任何2个S中的点的距离都不小于δ。由此可以推出矩形R中最多只有6个S中的点。事实上,我们可以将矩形R的长为2δ的边3等分,将它的长为δ的边2等分,由此导出6个(δ/2)×(2δ/3)的矩形。如图4(a)所示。
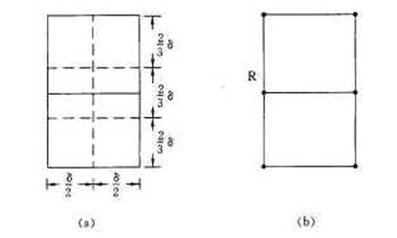 图4 矩形R中点的稀疏性
图4 矩形R中点的稀疏性若矩形R中有多于6个S中的点,则由鸽舍原理易知至少有一个δ×2δ的小矩形中有2个以上S中的点。设u,v是这样2个点,它们位于同一小矩形中,则
因此d(u,v)≤5δ/6<δ 。这与δ的意义相矛盾。也就是说矩形R中最多只有6个S中的点。图4(b)是矩形R中含有S中的6个点的极端情形。由于这种稀疏性质,对于P1中任一点p,P2中最多只有6个点与它构成最接近点对的候选者。因此,在分治法的合并步骤中,我们最多只需要检查6×n/2=3n对候选者,而不是n2/4对候选者。这是否就意味着我们可以在O(n)时间内完成分治法的合并步骤呢?现在还不能作出这个结论,因为我们只知道对于P1中每个S1中的点p最多只需要检查P2中的6个点,但是我们并不确切地知道要检查哪6个点。为了解决这个问题,我们可以将p和P2中所有S2的点投影到垂直线l上。由于能与p点一起构成最接近点对候选者的S2中点一定在矩形R中,所以它们在直线l上的投影点距p在l上投影点的距离小于δ。由上面的分析可知,这种投影点最多只有6个。因此,若将P1和P2中所有S的点按其y坐标排好序,则对P1中所有点p,对排好序的点列作一次扫描,就可以找出所有最接近点对的候选者,对P1中每一点最多只要检查P2中排好序的相继6个点。
至此,我们可以给出用分治法求二维最接近点对的算法CPAIR2如下:
function CPAIR2(S);
begin
if |S|=2
then δ:=S中这2点的距离
else if |S|=0
then δ:=∞
else
begin
1. m:=S中各点x坐标值的中位数; 构造S1和S2,使S1={p∈S|px≤m}和S2={p∈S|px>m}
2. δ1:=CPAIR2(S1);δ2:=CPAIR2(S2);
3. δm:=min(δ1,δ2);
4. 设P1是S1中距垂直分割线l的距离在δm之内的所有点组成的集合, P2是S2中距分割线l的距离在δm之内所有点组成的集合。将P1和P2中的点依其y坐标值从小到大排序,并设P1*和P2*是相应的已排好序的点列;
5. 通过扫描P1*以及对于P1*中每个点检查P2*中与其距离在δm之内的所有点(最多6个)可以完成合并。当P1*中的扫描指针逐次向上移动 时,P2*中的扫描指针可在宽为2δm的一个区间内移动。设δl是按 这种扫描方式找到的点对间的最小距离;
6. δ=min(δm,δl);
end;
return(δ);
end;
下面我们来分析一下算法CPAIR2的计算复杂性。设对于n个点的平面点集S,算法耗时T(n)。算法的第1步和第5步用了O(n)时间,第3步和第6步用了常数时间,第2步用了2T(n/2)时间。若在每次执行第4步时进行排序,则在最坏情况下第4步要用O(nlogn)时间。这不符合我们的要求。因此,在这里我们要作一个技术上的处理。我们采用设计算法时常用的预排序技术,即在使用分治法之前,预先将S中n个点依其y坐标值排好序,设排好序的点列为P*。在执行分治法的第4步时,只要对P*作一次线性扫描,即可抽取出我们所需要的排好序的点列P1*和P2*。然后,在第5步中再对P1*作一次线性扫描,即可求得δl。因此,第4步和第5步的两遍扫描合在一起只要用O(n)时间。这样一来,经过预排序处理后的算法CPAIR2所需的计算时间T(n)满足递归方程:
显而易见T(n)=O(nlogn),预排序所需的计算时间为O(n1ogn)。因此,整个算法所需的计算时间为O(nlogn)。在渐近的意义下,此算法已是最优的了。
-















 3362
3362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









