






在Transformer出来之前,NLP处理使用的是RNN.RNN得到的信息是关于整个句子的,没有办法获得单个词的信息,如下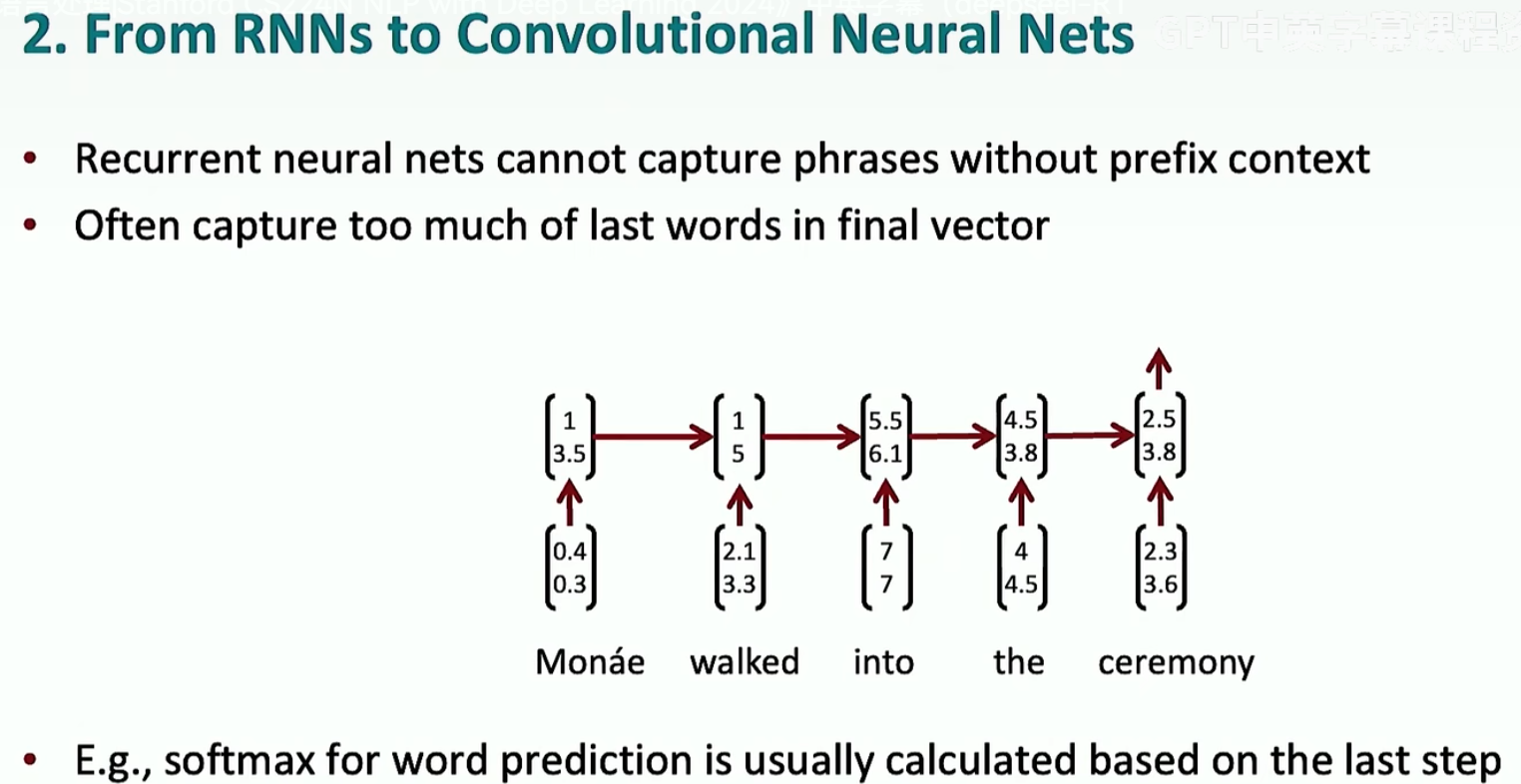
于是我们可以考虑使用卷积神经网络(这个东西类似于\(n\)元语法)
现在CNN是进行一维的滑动。首先我们的序列是一维的,但是我们要先将每个词元变成词向量,然后选择一个适应的CNN,如下
然后CNN沿着红线进行滑动并计算卷积,得到右边第一列,然后设置一个偏置项(这里的偏置项是\(1\)),再经过\(\text{Sigmoid}\)激活函数后得到最后一列
当然也有填充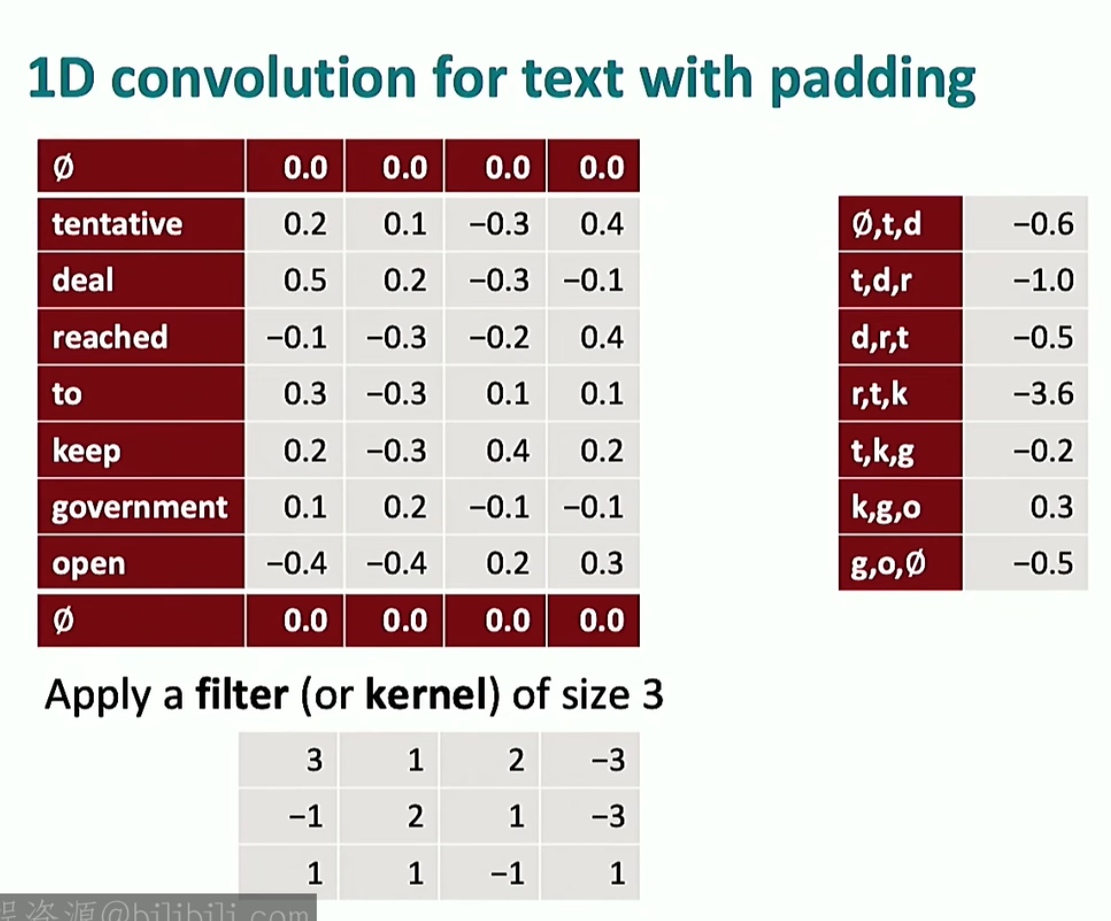
当然也可以得到多个通道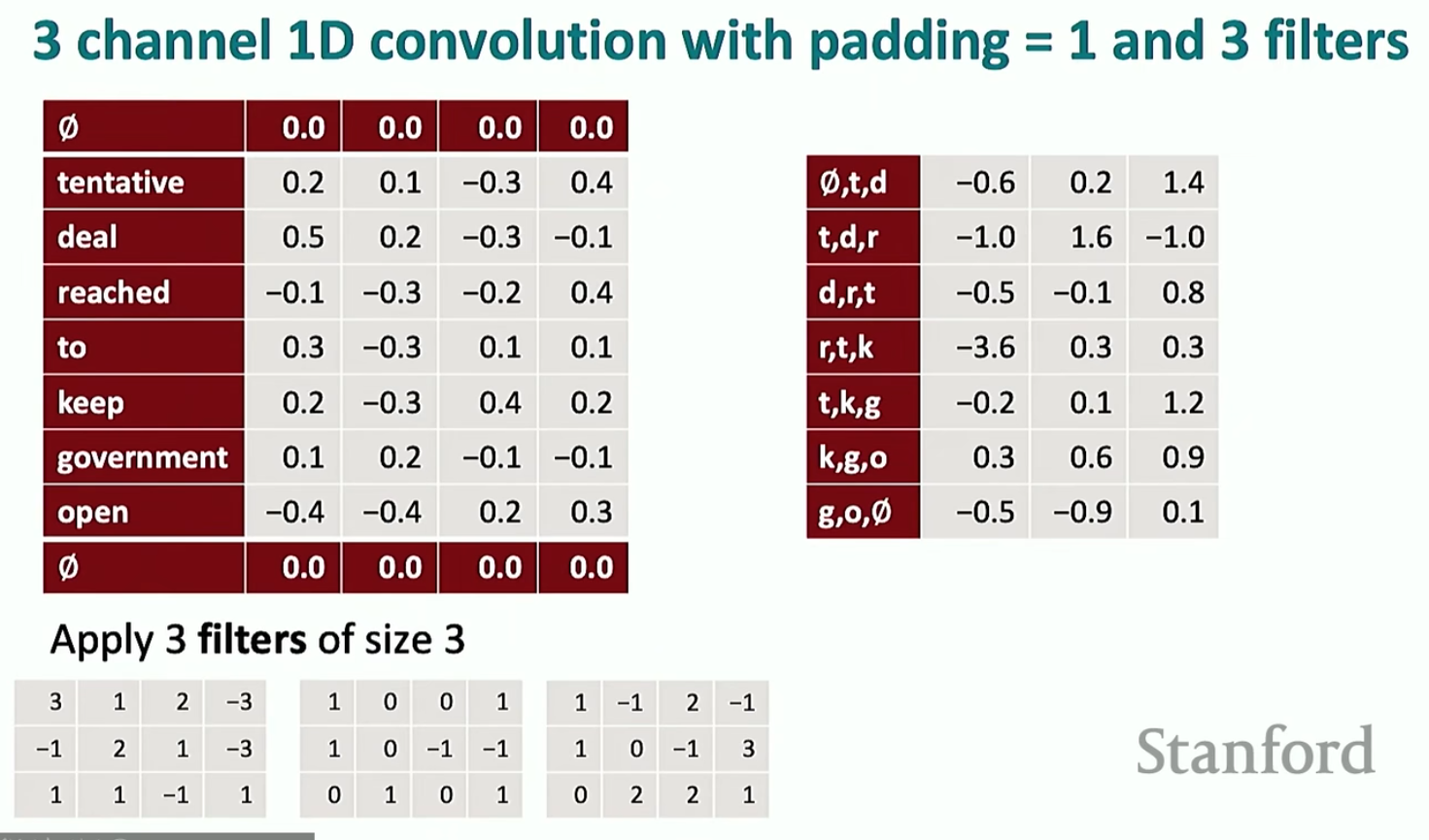
当然也有池化。注意池化跟CV里面的一样,是按照通道池化的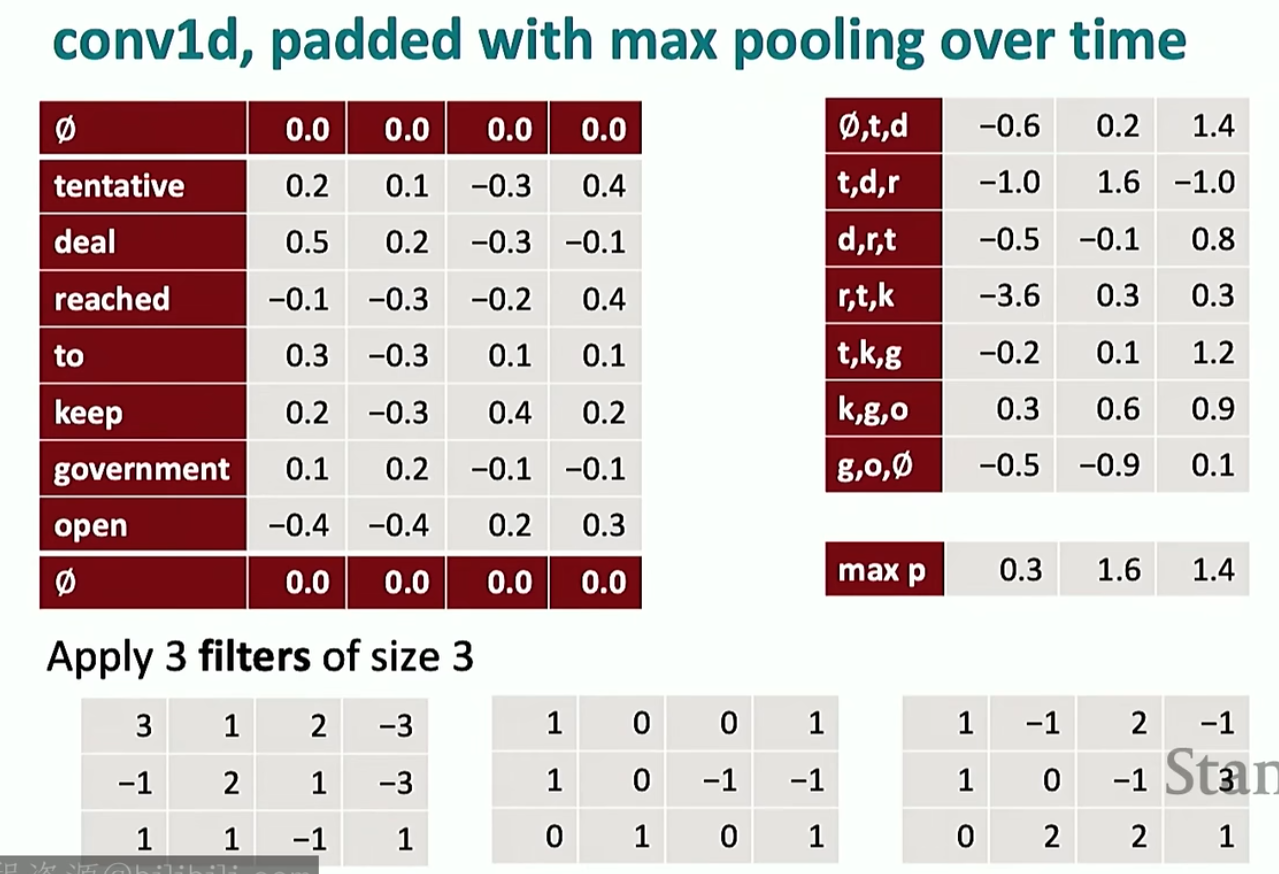
这里的卷积核跟CV里的作用也是一样的,可能一些卷积核检测代词,另一个检测动词等(最大池化层导致了特征出现在任何位置都可以检测到;当然也可以用平均池化层,这个时候考虑的是整体水平,比如这个句子的整体口语化水平)
代码如下
可以看到代码里面也有步长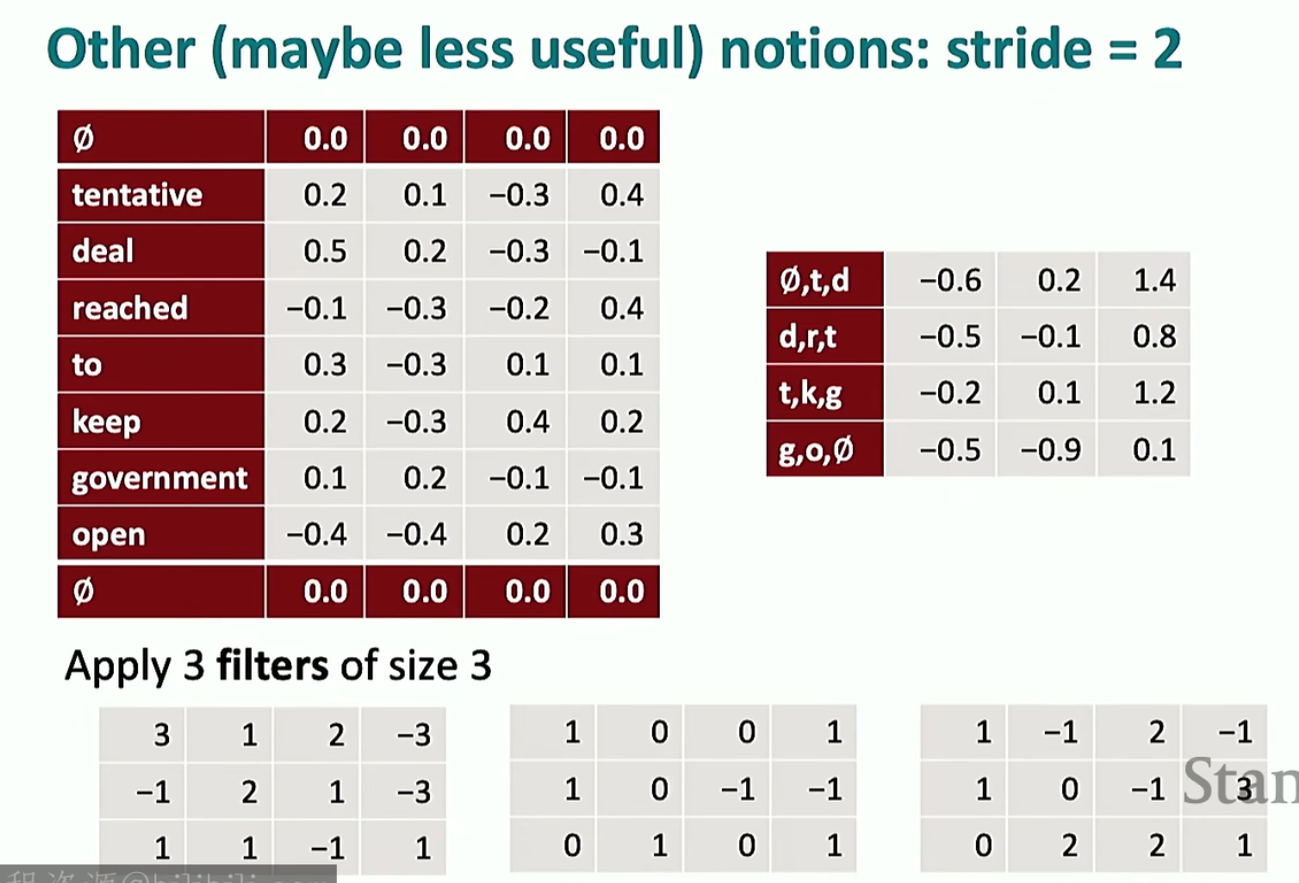
也可以在池化层上面设置步长(此时就可以检测多个位置的特征)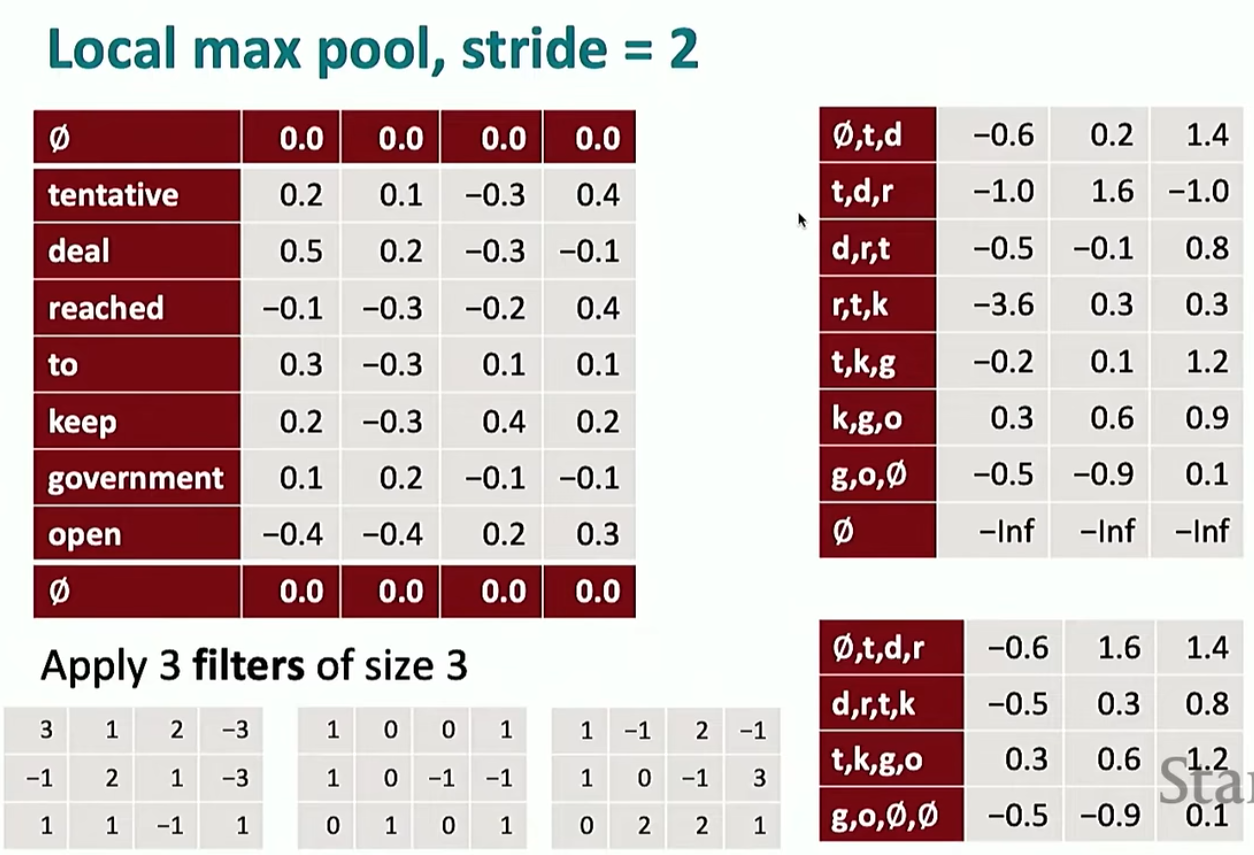
还可以保留每个特征若干个最大值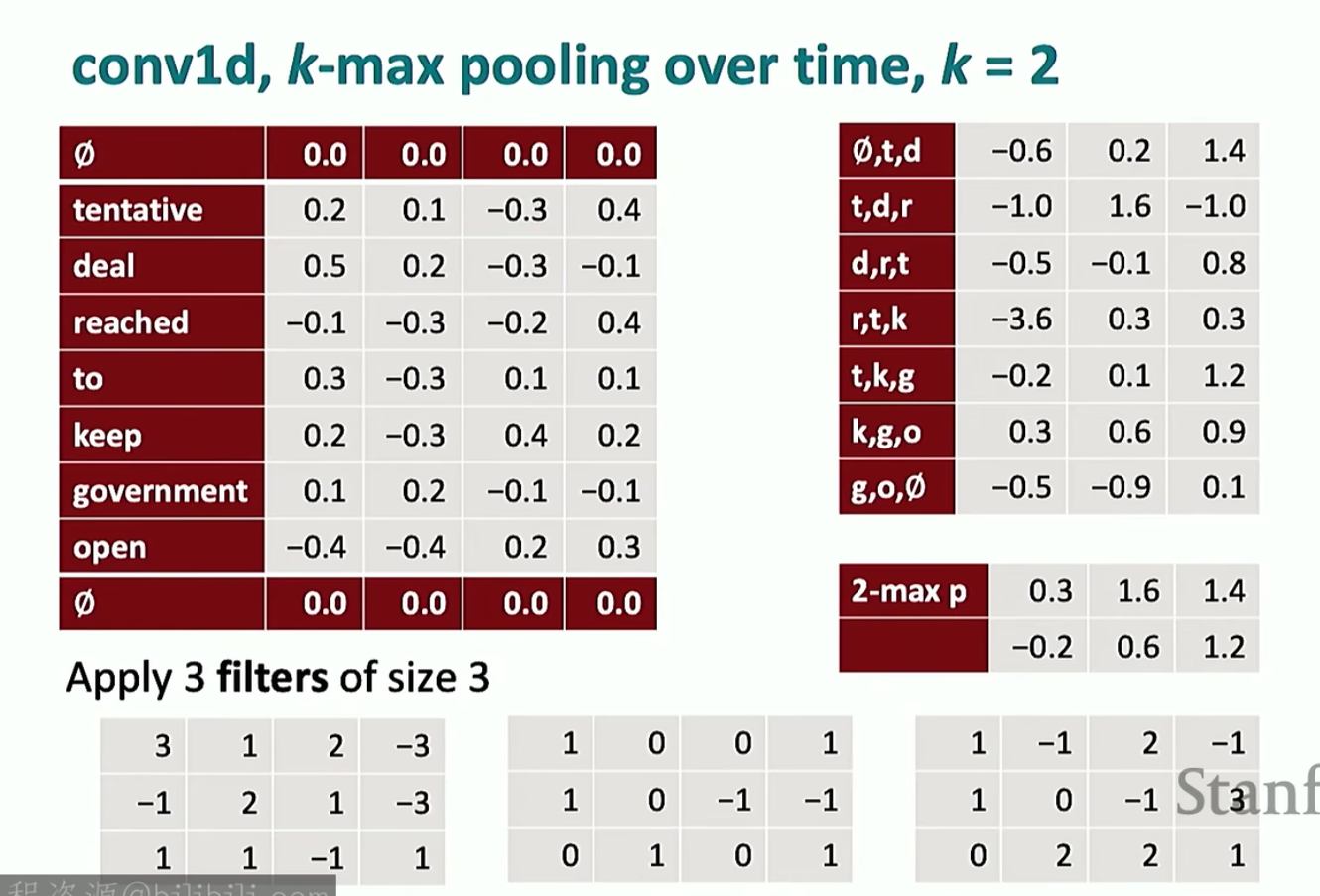
还可以不选相邻的位置做卷积,而是跳着做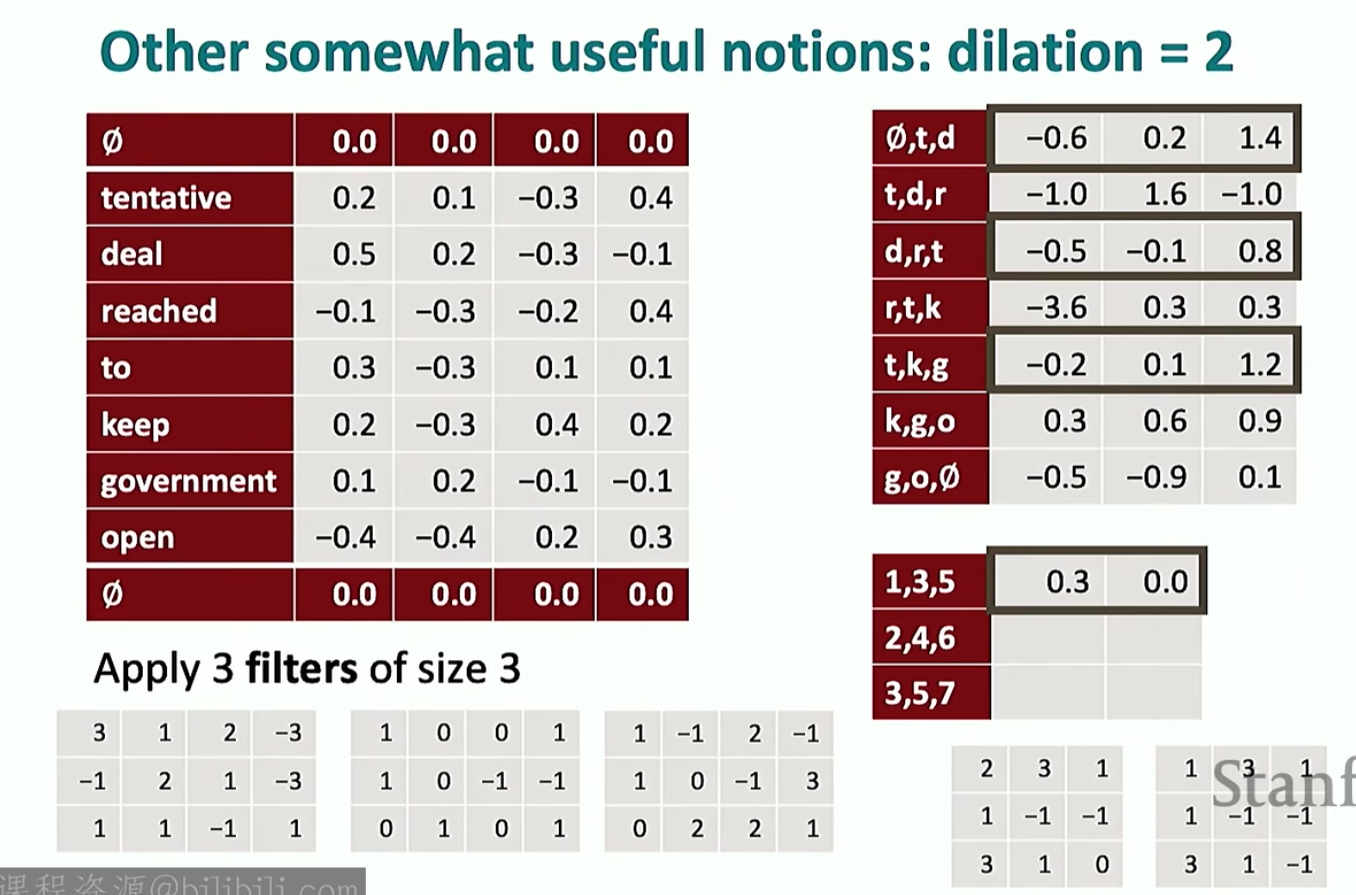
讲一个在预训练词向量+神经网络(在Transformer中一般不会出现这种问题)微调中的bug,如下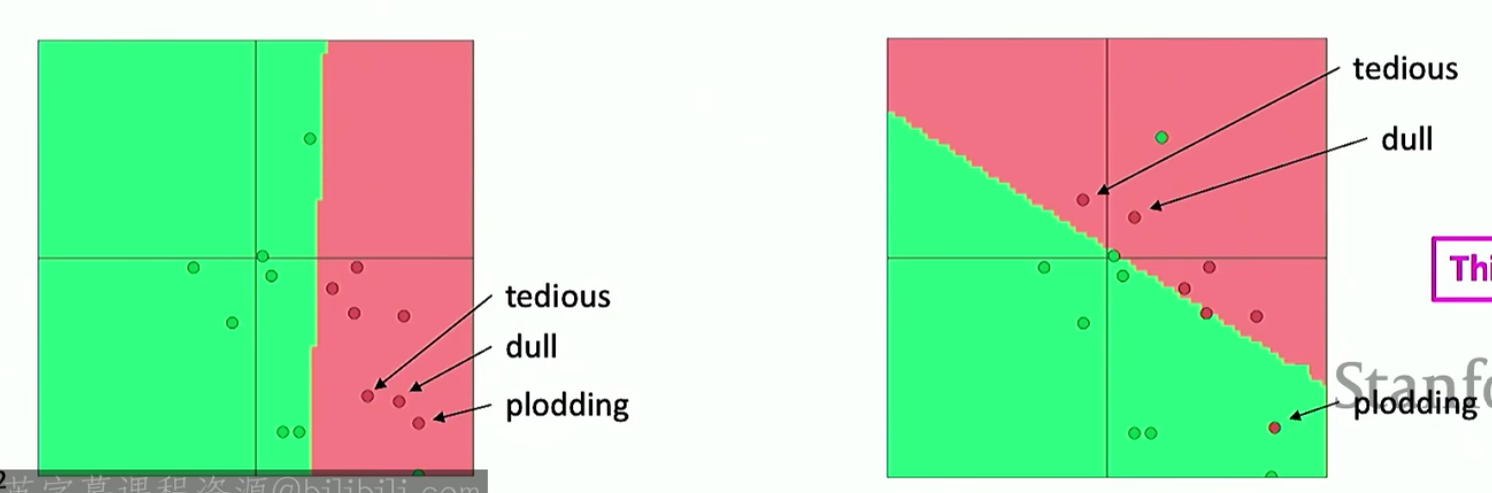
左图是我们预训练之后的词向量,右图是我们微调之后的词向量。在训练过程中,我们的数据集没有涉及到plodding这个词,导致其没有移动,而剩下两个词移动了,导致plodding被归到正向词语里面了。这就是说微调反而导致了更差的结果。解决方法就是直接将通道数翻倍,其中一半通道数将预训练词向量冻结,另一半可以微调,具体见下(下面在做情感分析)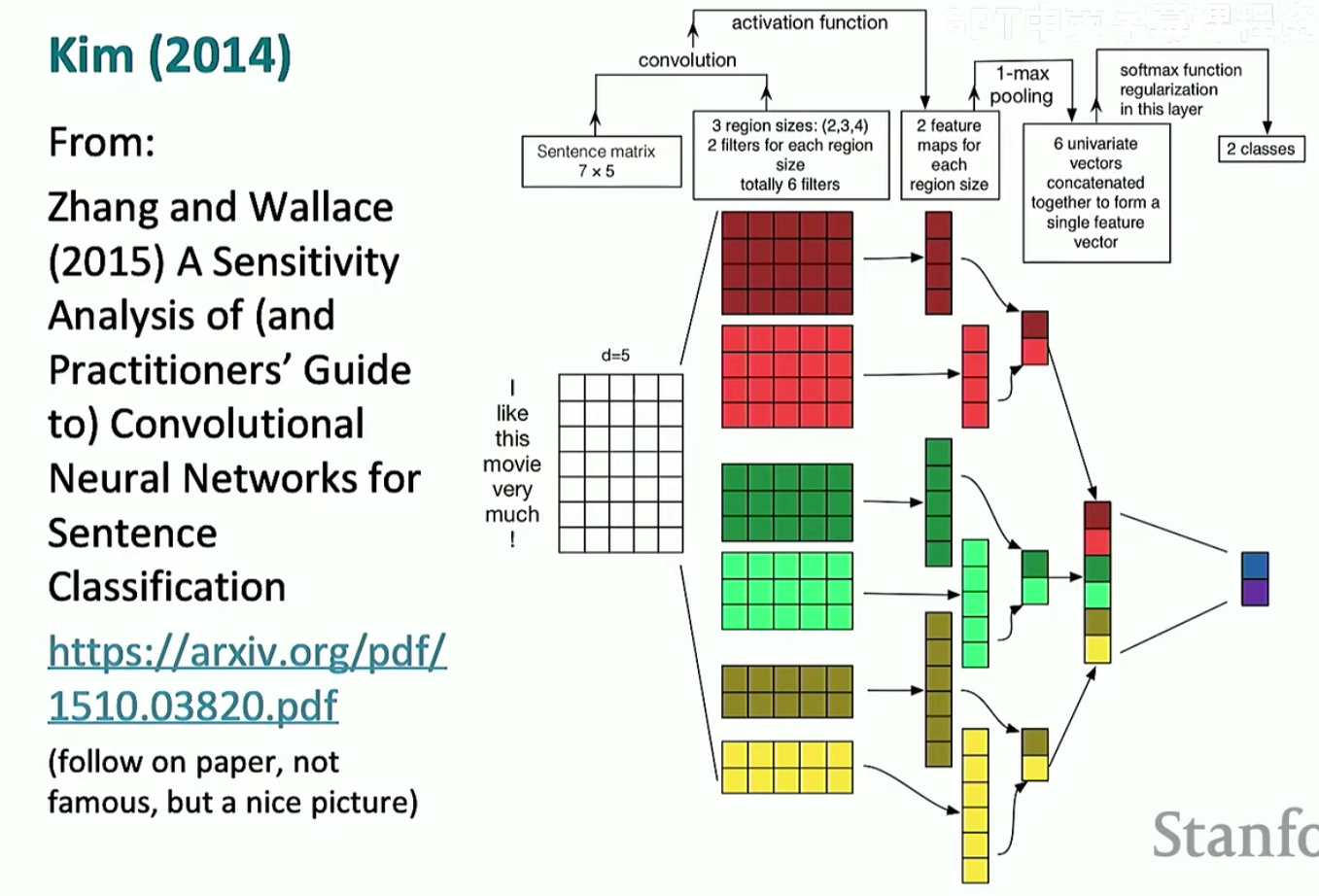
可以看到,每一个尺寸的卷积核都有两个一模一样的。这个模型的训练结果见下(但是要提一嘴,下面结果中的其他模型大部分都没有使用暂退法,但是上述模型使用了,所以这种比较当然不是很公平;但是,这还是可以说明尽管只是很简单的网络结构依然可以取得很好的效果)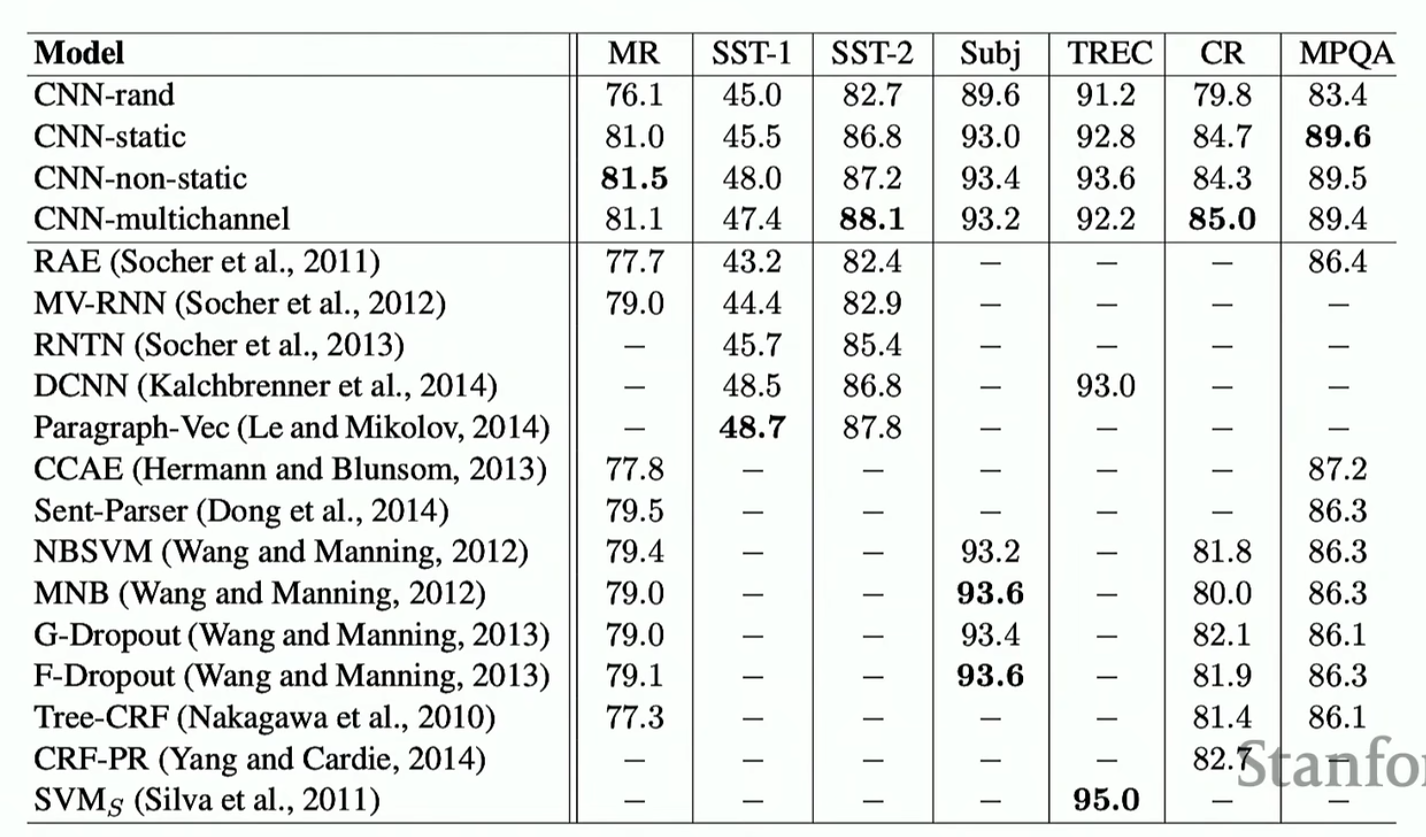
CNN的一大好处就是高度并行化
当然也存在大小为\(1\)的卷积层,与CV中的一样,这相当于一个全连接层,可以用来创建新的特征,如下
在2017年的时候,Transformer还没有出来,NLP用的都是LSTM,但是LSTM的深度不能搭建得很深,但是当时的CV可以,所以有人想把CV中的CNN借鉴到NLP里面来,然后就在文本分类任务中搭建了非常深的CNN,叫做VD-CNN,架构如下(注意,图中的\(16\)维嵌入不是下载的预训练词向量,而是相当于nn.Embedding,随机初始化然后进行训练,所以这个架构是不依赖于预训练的词向量的)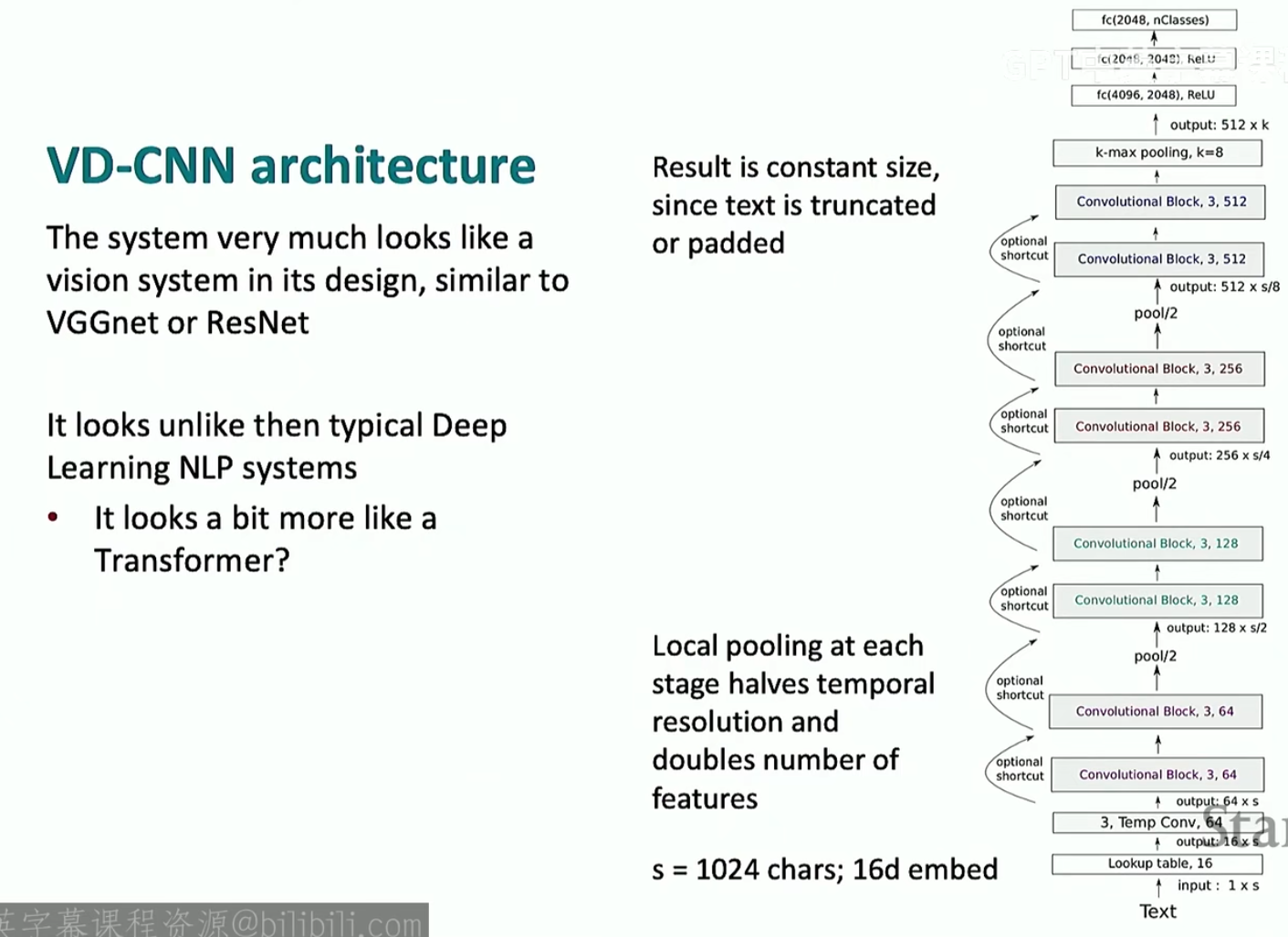

来看一下效果(最上面那张表是在用VD-CNN之前的模型能够取得的最好效果)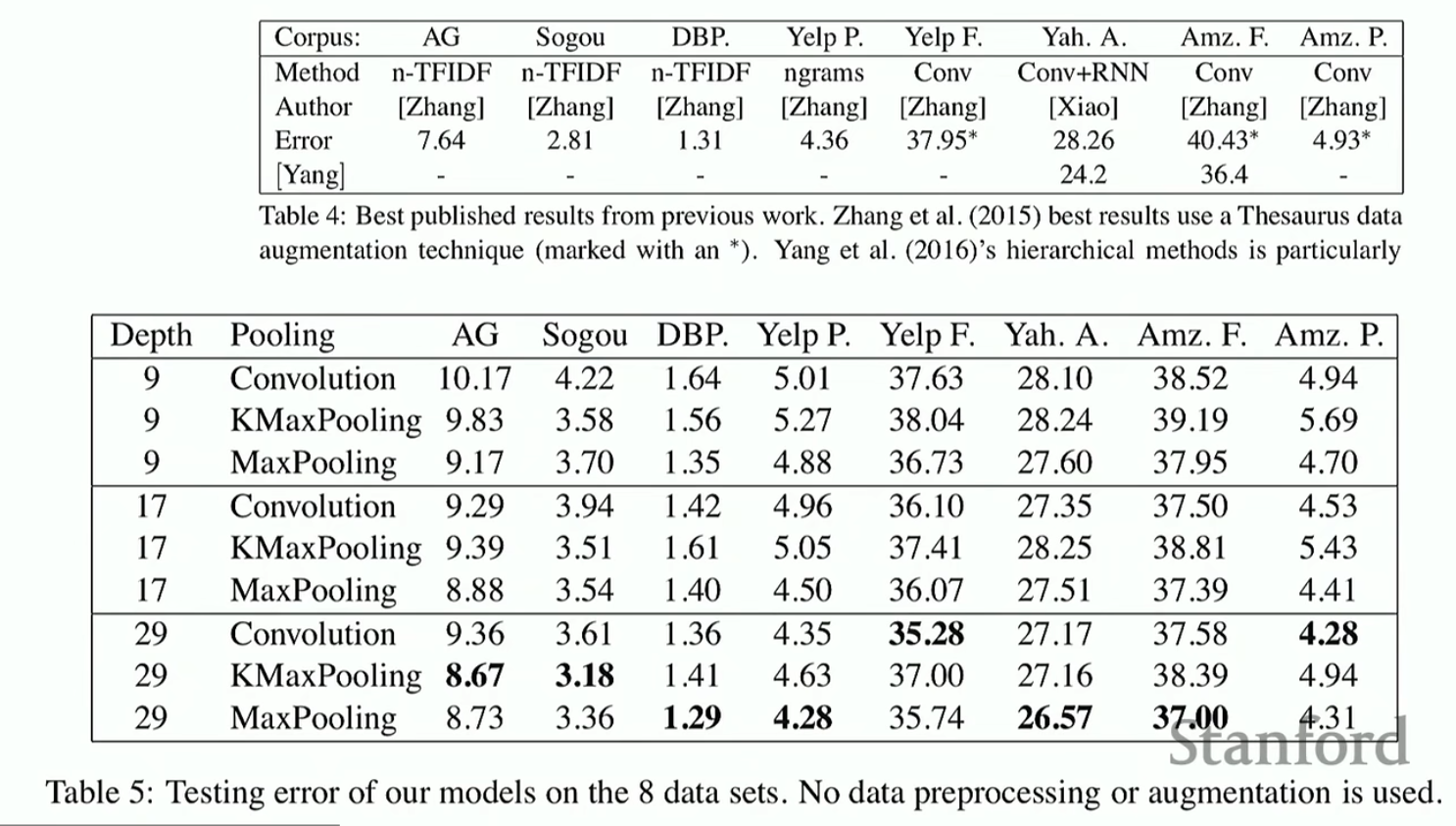
介绍来介绍另一个比较极端的方向:树状递归神经网络。这个想法的灵感来源于人类句子本身就具有递归的结构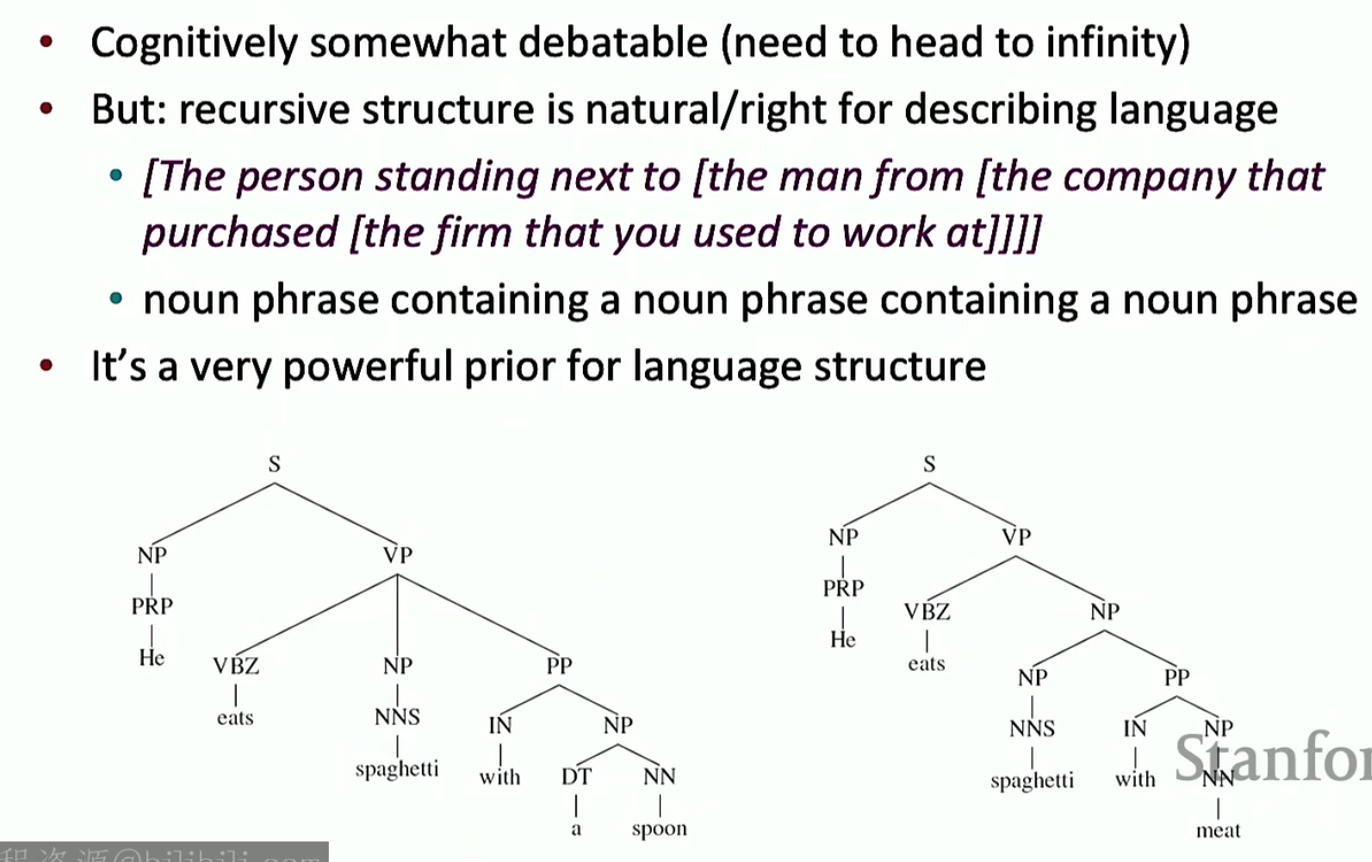
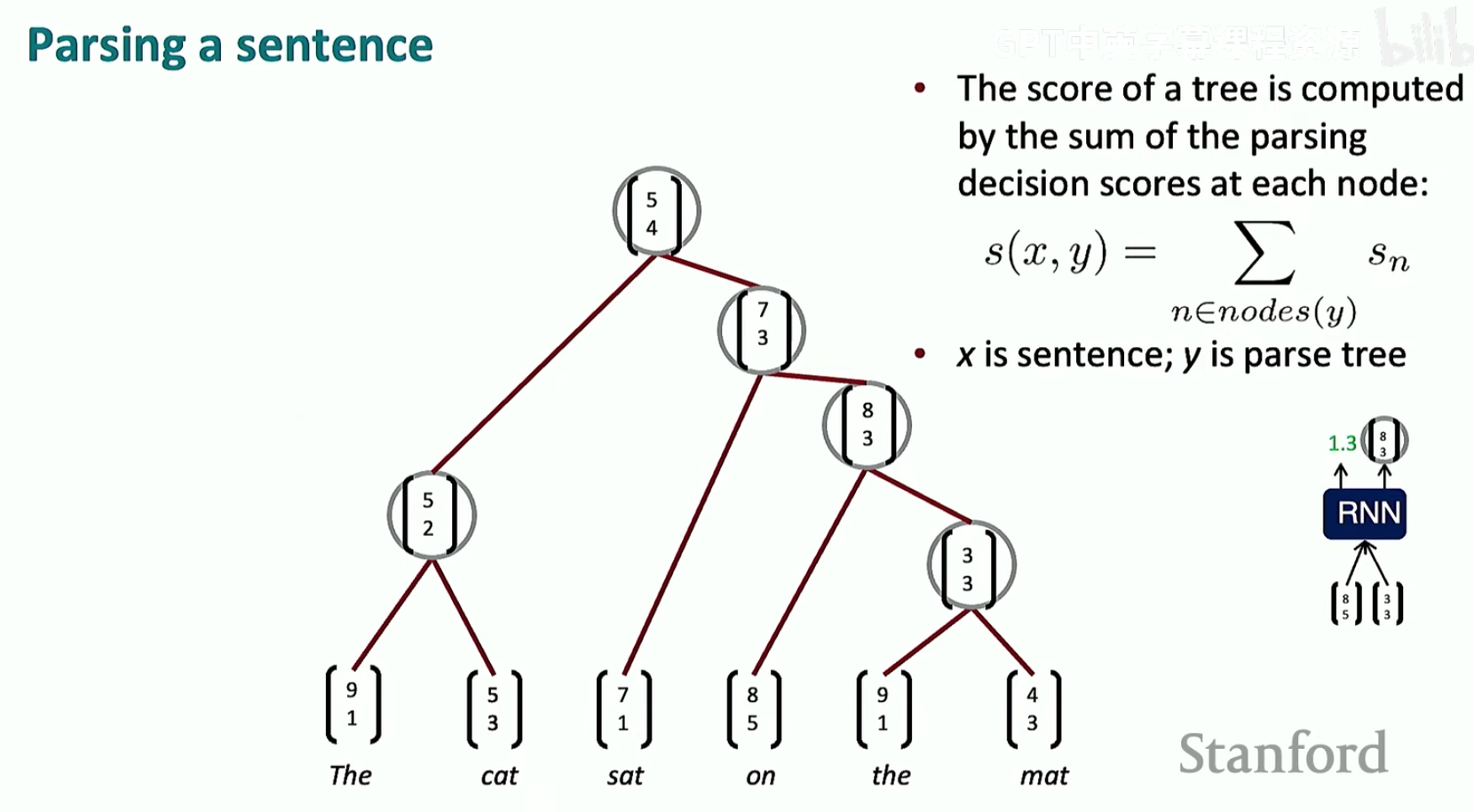
现在我们想要将句子嵌入到词向量空间中,我们使用之前讲过的语言树的形式进行建模(利用CNN)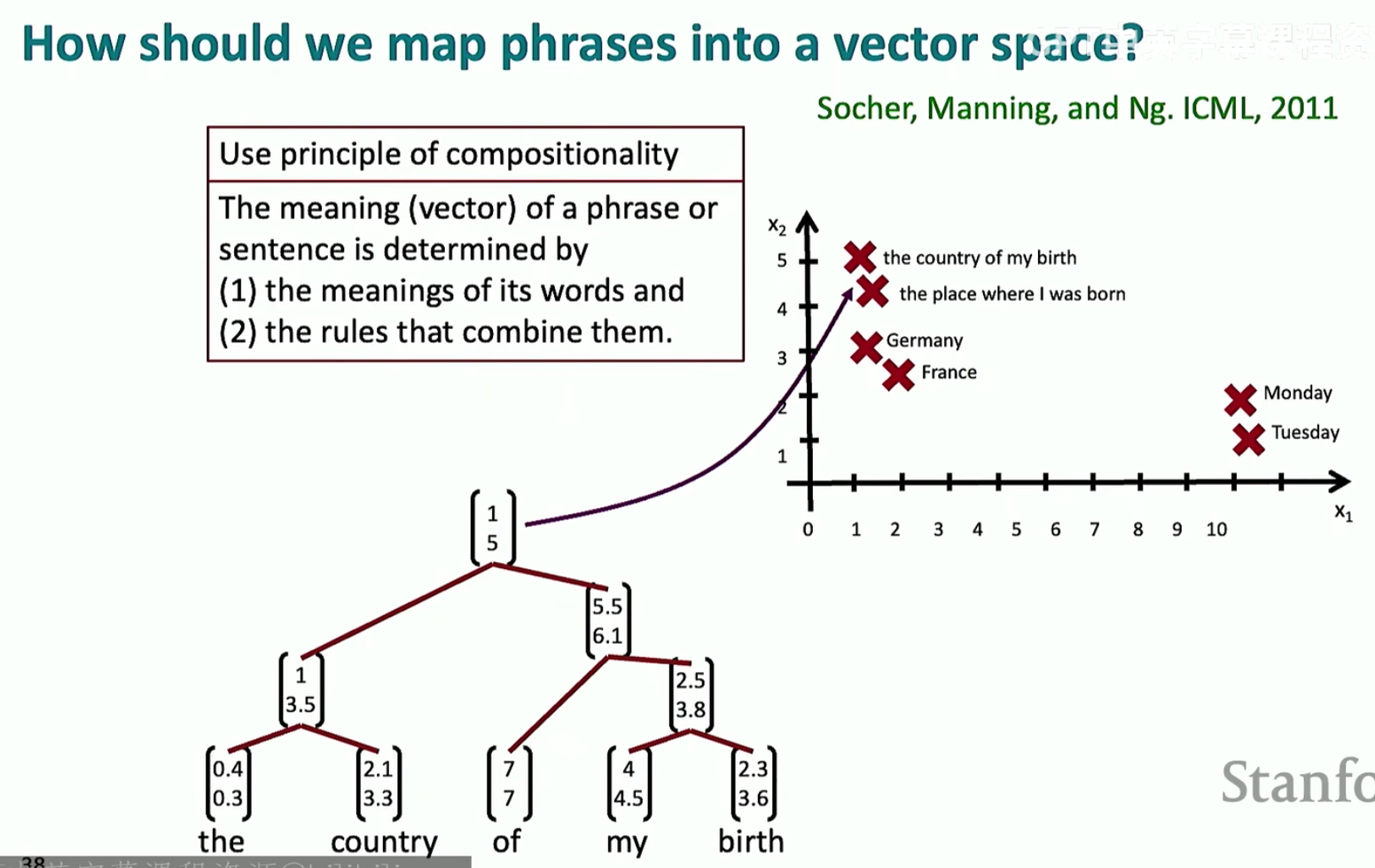
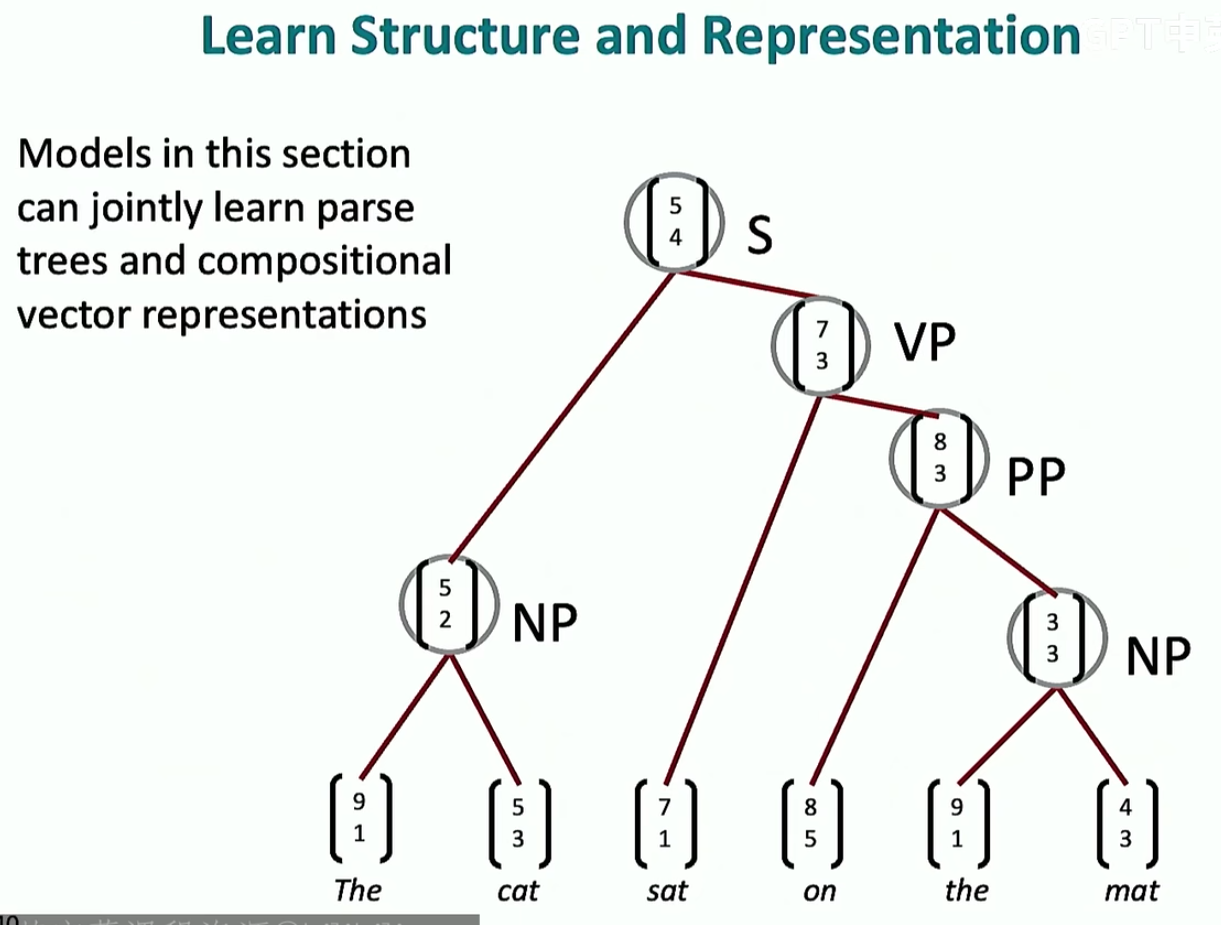
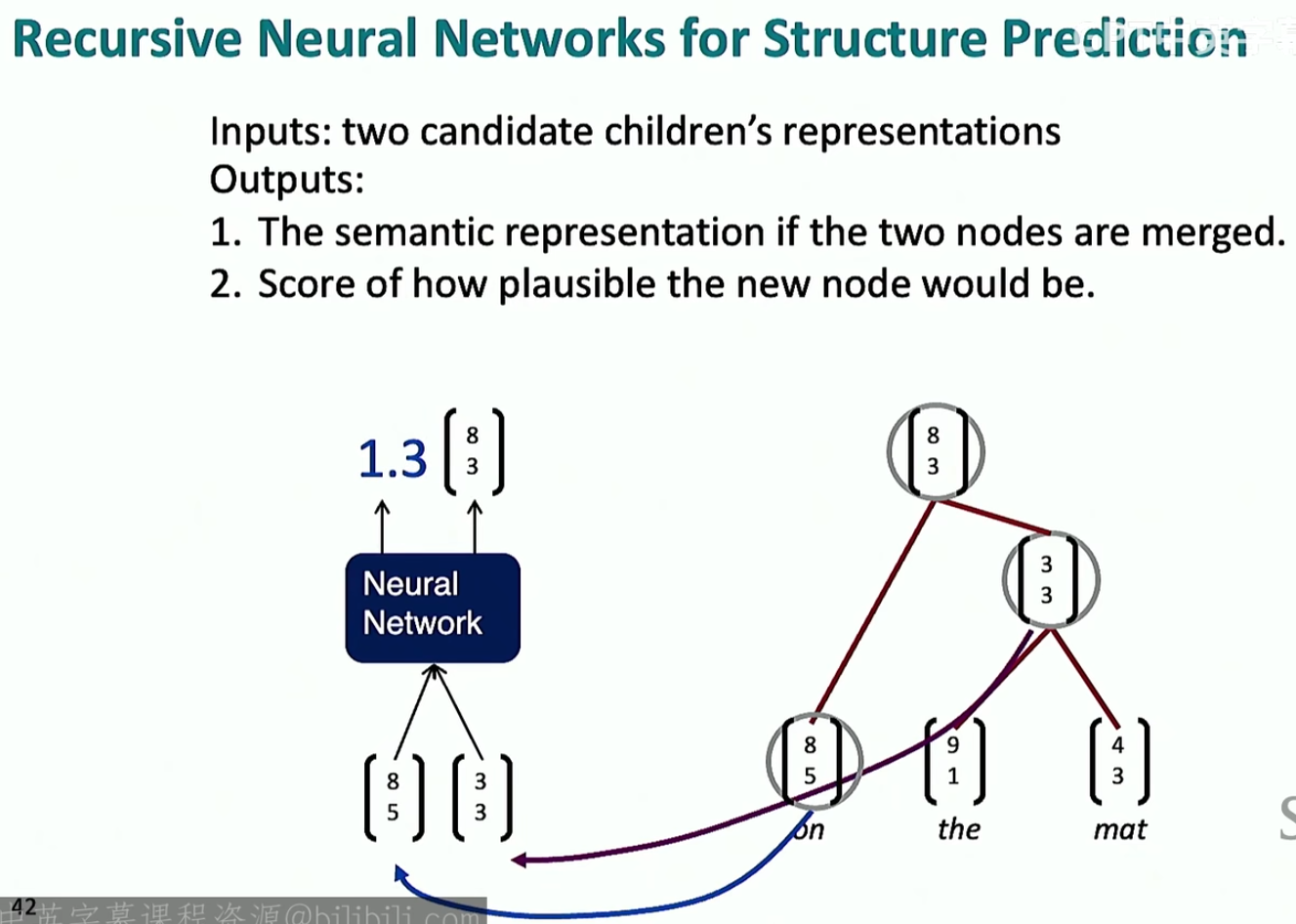
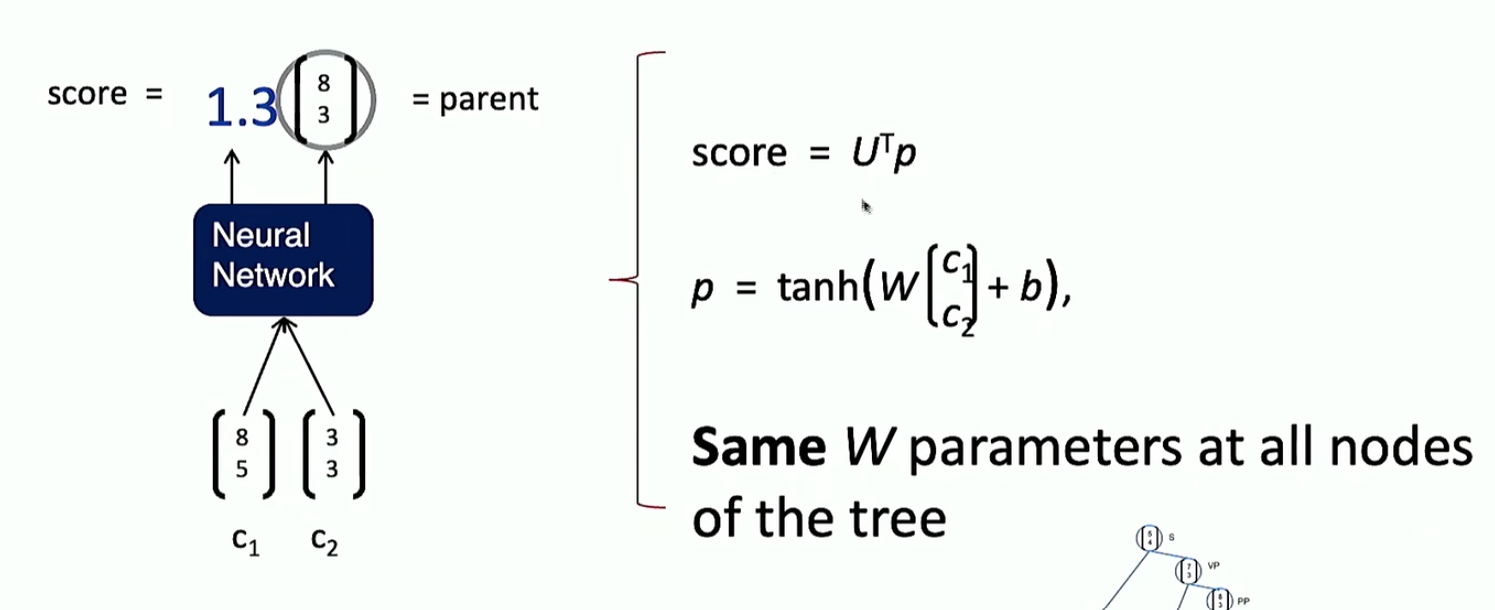
score这个东西就是来看两个词向量之间的结构是否良好的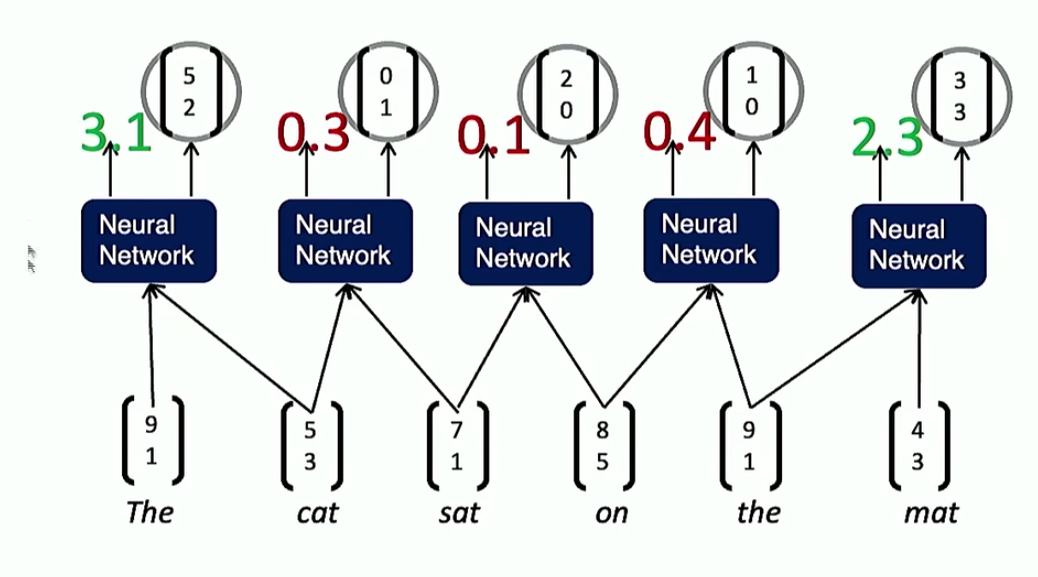
如图,合并最开始两个词,并让新合成的词与相邻的词进行卷积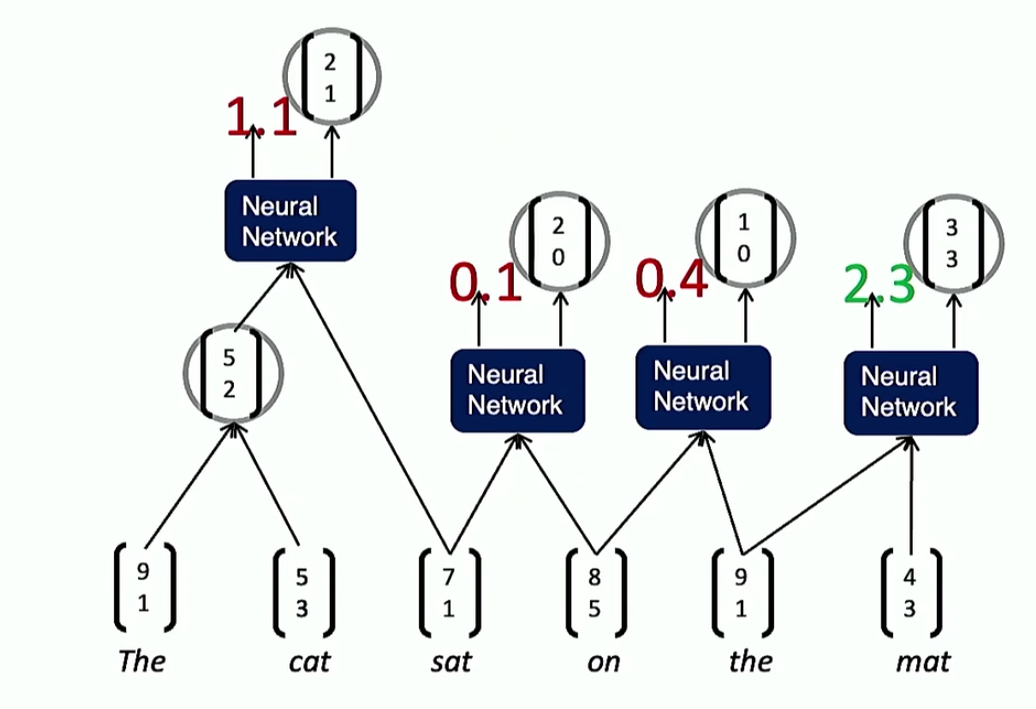
然后,合并最后两个词,并让新合成的词与相邻的词进行卷积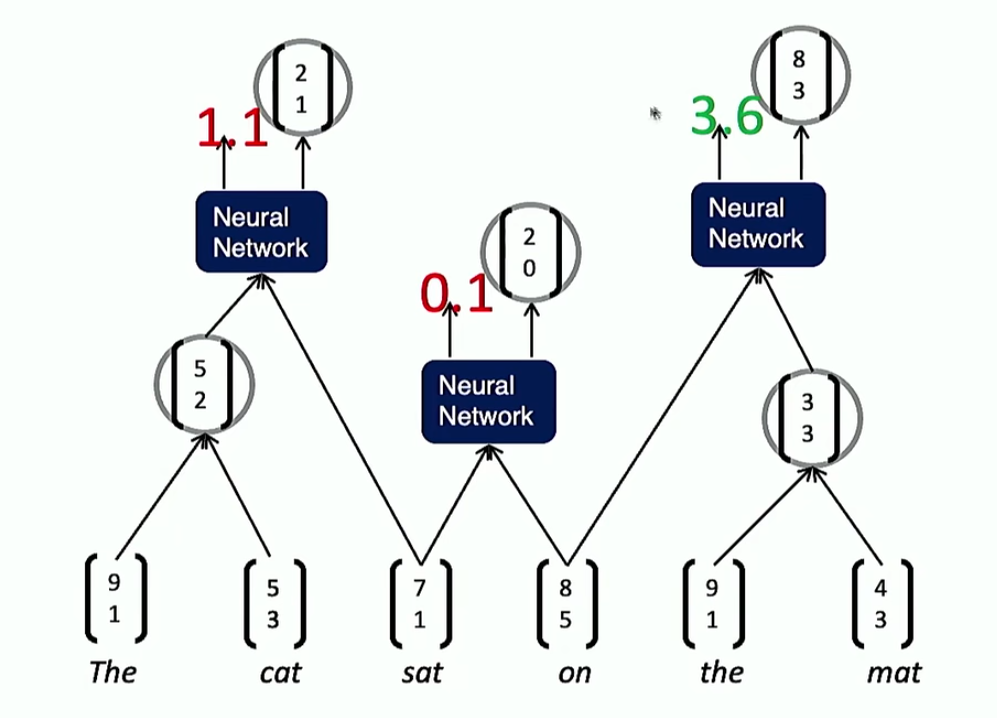
但是这种方法也有一些局限
然后还介绍了个下面的东西,但是没太听懂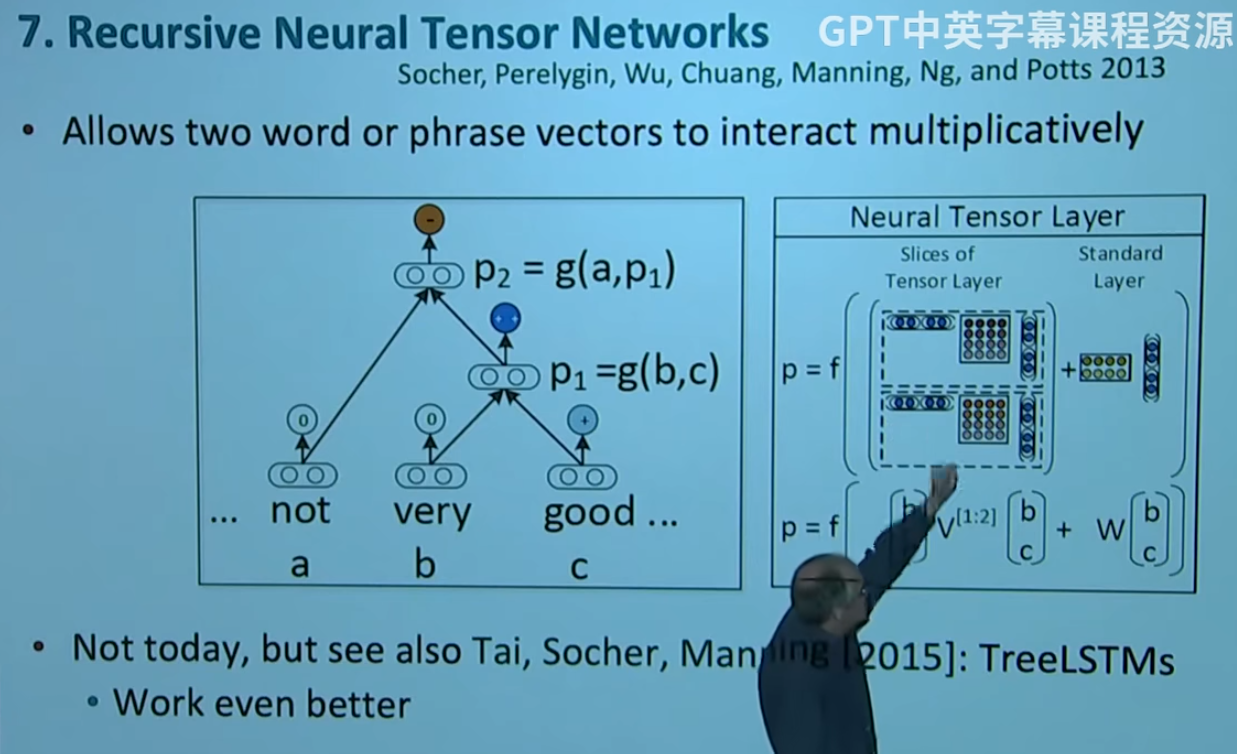


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









