







一、前言
scrapy是基于twisted的异步处理框架,与传统的requests爬虫程序执行流程不同,scrapy使用多线程,将发送请求,提取数据,保存数据等操作分别交给Scheduler(调度器),Downloader(下载器),Spider(爬虫),Pipeline(管道)等爬虫“组件”来完成。多线程的运行框架使得爬虫的效率大大提升,让爬虫程序变得更快,更强。基于以上特点,本文将以爬取豆瓣图书信息为例,简要阐述基于scrapy框架下的爬虫实现流程。
二、爬虫流程以及代码实现
(一)分析需要爬取的网页结构
在编写一个爬虫项目之前,我们需要对所需爬取的网页有一个清晰的认识。爬虫的本质是在响应中的字符串提取所需信息,即只有我们提取到的响应中存在我们所需要的数据时,我们才能进行爬虫。我们访问豆瓣读书,发现豆瓣图书标签中存在许多大分类(文学,文化...),大分类中存在许多小分类(小说,外国文学...)。点开每个小分类标签,会呈现出不同类型的书的列表清单,且不止一页。我们要做的就是提取豆瓣所有类型书籍下的所有书籍的简要信息,包括图书作者,书名,图书价格,豆瓣评分,书籍评论人数等。网页的页面如下图所示:

图1.豆瓣的图书标签页
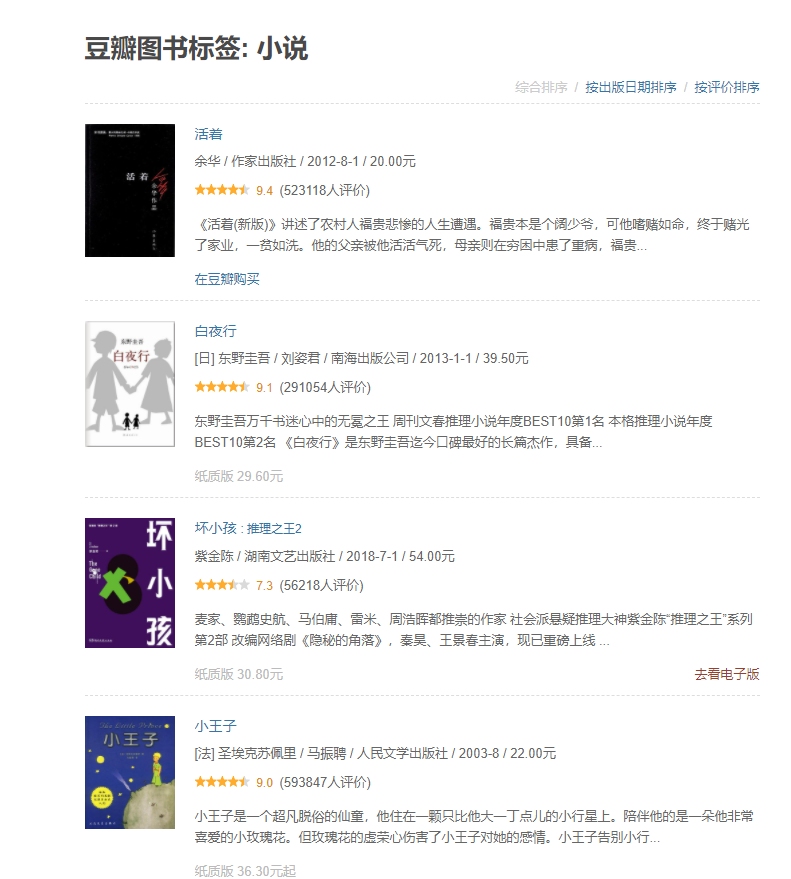
图2.豆瓣每个小标签下的url页面
(二)创建scrapy项目
创建scrapy项目十分简单,首先打开命令提示符,通过cd命令路径,将工作路径定位到我们需要创建项目的路径下,然后创建一个scrapy项目,用到的程序如下:
scrapy startproject douban_books #创建一个名字为douban_books的爬虫项目
cd douban_books #定位到项目文件夹内
scrapy genspider book book.douban.com #创建爬虫所需的脚本文件book.py;book.douban.com设置允许爬取的网页范围(allow_domains)
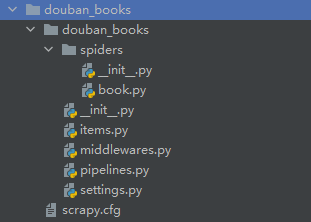
图3.scrapy项目内容显示
(三
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









