






目录
前言
在机器学习中,通常有多种学习算法可选择。而选择哪一个算法、使用哪一种参数配置就是机器学习中的模型选择问题。模型选择本质上是选择出泛化误差小的模型,而泛化误差需要用到一系列的实验评估方法获得某种性能度量指标。
性能度量是机器学习中非常重要的概念之一。这是因为性能度量本质是衡量模型泛化能力好坏的标准,反映了任务需求。
一、常见的性能度量
1.错误率和精度
在分类任务中,即预测离散值的问题,最常用的是错误率(Error Rate)和精度(Accuracy)表示。
- 错误率是分类错误的样本数占样本总数的比例,定义为
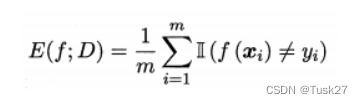
- 精度是分类正确的样本数占样本总数的比例,定义为
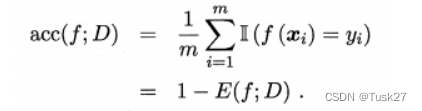
2.混淆矩阵
错误率和精度虽然常用,但是不适用与所有的任务需求。这时就需要用查准率(precision)和查全率(revall)来解决问题。
混淆矩阵(Confusion Matrix)是一种常用的评价分类模型性能的方法。 它基于模型预测结果和真实分类结果之间的交叉比对。
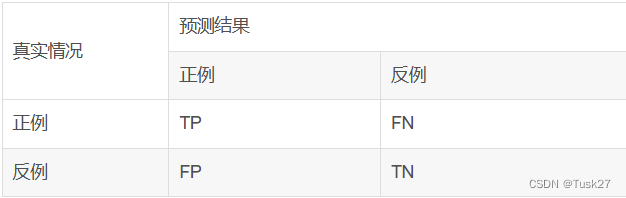
- TP:True Positive, 把正类预测为正类
- FP:False Positive,把负类预测为正类
- TN:True Negative, 把负类预测为负类
- FN:False Negative,把正类预测为负类
查准率(Precision)又称为精确率:在所有被预测为正类的样本中真实结果也为正类的占比。
查全率(Recall) 又称为召回率:所有实际为真的样本被预测为真的的概率
查准率和查全率往往是一对矛盾量的:当我们试图提高查准率时,可能会降低查全率; 反之亦然。 这是因为调整模型的预测策略,如提高分类阈值,可以增加预测为正例的准确性,但也可能过滤掉一些真正的正例,从而降低查全率; 相反,降低分类阈值可以捕捉更多正例,但也可能导致误报增加,从而降低查准率。
3.P-R曲线
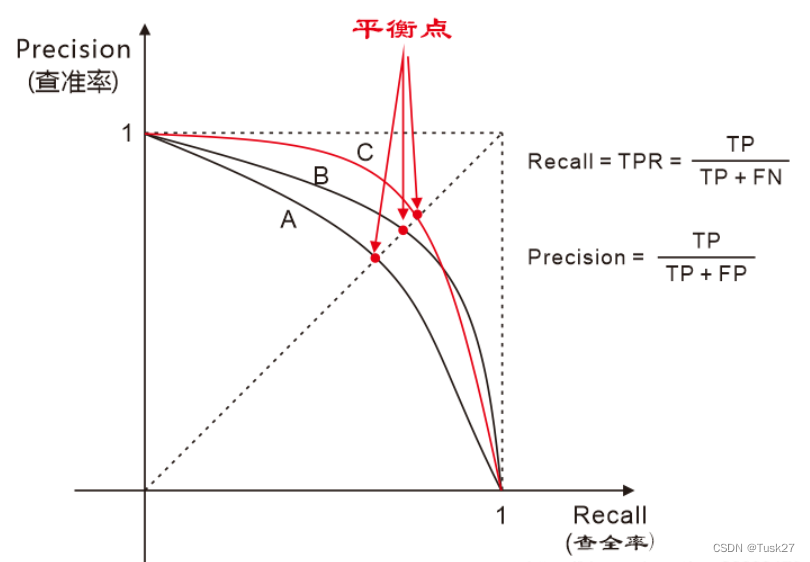
正因为查准率和查全率往往是一对矛盾量,而我们想要得到查准率和查全率都较高的值,这时就可以使用的度量方法就是绘制P-R曲线。
在 P-R 曲线中,横轴表示查全率(Recall),纵轴表示查准率(Precision)。 每个点代表着使用不同阈值得到的查准率和查全率的组合。 通过在不同阈值上调整模型的预测策略,可以得到一系列不同的查准率和查全率值,进而绘制出 P-R 曲线。
另外P-R曲线可以比较学习器的性能
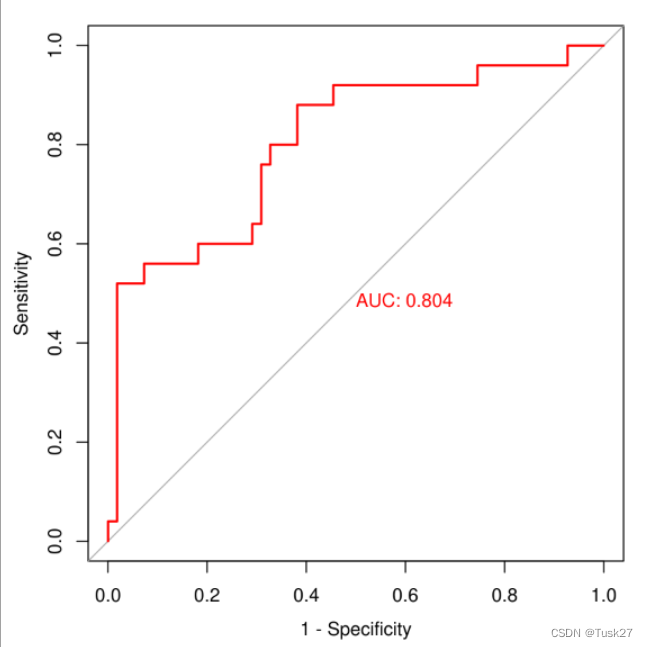
如果一个学习器的P-R曲线被另一个学习器的P-R曲线完全包住,则可断言后者的性能优于前者。但更常用的是平衡点或者是F1值。平衡点(BEP)是P=R时的取值,如果这个值较大,则说明学习器的性能较好。而F1 = 2 * P * R /( P + R ),同样,F1值越大,我们可以认为该学习器的性能较好。如图:
4.ROC曲线
在ROC 曲线中,横轴表示假正例率(FPR),纵轴表示真正例率(TPR)。 每个点代表着使用不同阈值得到的 FPR 和 TPR 的组合。 根据模型的预测结果,通过在不同阈值上调整判断是否为正例的条件,可以得到一系列不同的 FPR 和 TPR 值,进而绘制出 ROC 曲线。
真正例率:被预测为正例占真实正例的比例(与查全率相同)
假正例率:被预测为正例占真实反例比例
ROC 曲线的特点是 FPR 和 TPR 都在 [0, 1] 的范围内,并且随着阈值的变化而变化。
ROC曲线下的面积(AUC,Area Under the Curve)可以作为模型性能的度量。
ROC曲线同样可以比较学习器的性能。
若一个学习器的 ROC 曲线被另 一个学习器的曲线完全"包住", 则可断言后者的性能优于前者;
若两个学习器的 ROC 曲线发生交叉,则难以-般性地断言两者孰优孰劣 . 此时比较 AUC 。
需要注意的是ROC 曲线在处理类别不平衡问题时相对于 P-R 曲线有一定的局限性。 由于 ROC 曲线只关注真正例率和假正例率,并不直接考虑类别分布。而 P-R 曲线则更能反映出在正例样本中的预测准确性和覆盖能力。
二、实现P-R曲线
1.生成数据集
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
# 生成样本数据集
X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, n_redundant=5, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)使用了 make_classification 函数来生成一个二分类的合成数据集。参数 n_samples 表示生成的样本数量,n_features 表示特征的数量,n_informative 表示有信息的特征数量,n_redundant 表示冗余特征的数量,random_state 是一个随机种子,用于确保可重复性。
参数 test_size 表示测试集占总样本的比例,这里设置为 0.2 表示将 20% 的数据作为测试集,而剩下的 80% 作为训练集。random_state 是一个随机种子,用于确保可重复性。函数会返回训练集和测试集的特征矩阵及对应的标签。
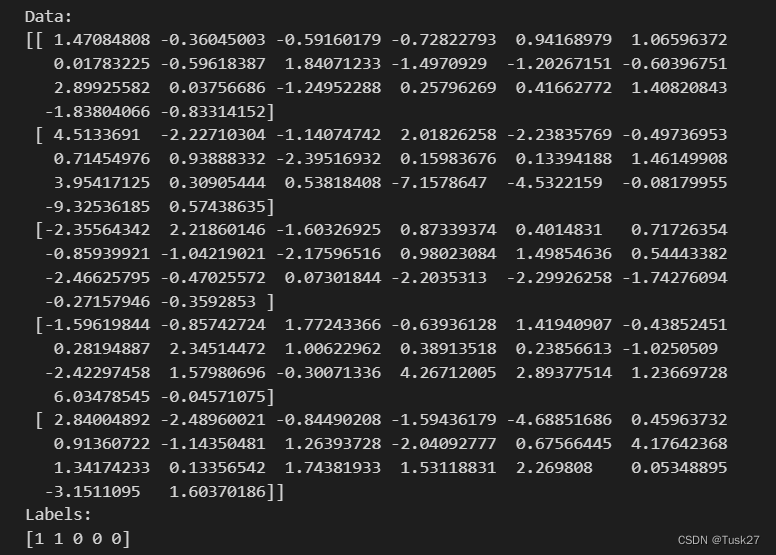
部分数据集
2.训练模型
# 训练KNN模型
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = knn.predict(X_test)使用K-最近邻(KNN)分类器,并在测试集上进行了预测。
3.计算混淆矩阵
# 计算混淆矩阵
def calculate_confusion_matrix(y_true, y_pred):
tp = np.sum((y_true == 1) & (y_pred == 1))
fp = np.sum((y_true == 0) & (y_pred == 1))
fn = np.sum((y_true == 1) & (y_pred == 0))
tn = np.sum((y_true == 0) & (y_pred == 0))
return tp, fp, fn, tn
tp, fp, fn, tn = calculate_confusion_matrix(y_test, y_pred)
通过混淆矩阵手动计算精确率(Precision)和召回率(Recall)
def calculate_precision_and_recall(tp, fp, fn):
precision = tp / (tp + fp)
recall = tp / (tp + fn)
return precision, recall
precision, recall = calculate_precision_and_recall(tp, fp, fn)4.绘制P-R曲线
# 绘制P-R曲线
precision_curve, recall_curve, _ = precision_recall_curve(y_test, y_pred)
plt.plot(recall_curve, precision_curve, marker='.', label='KNN')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('P-R Curve')
plt.legend()
plt.show()
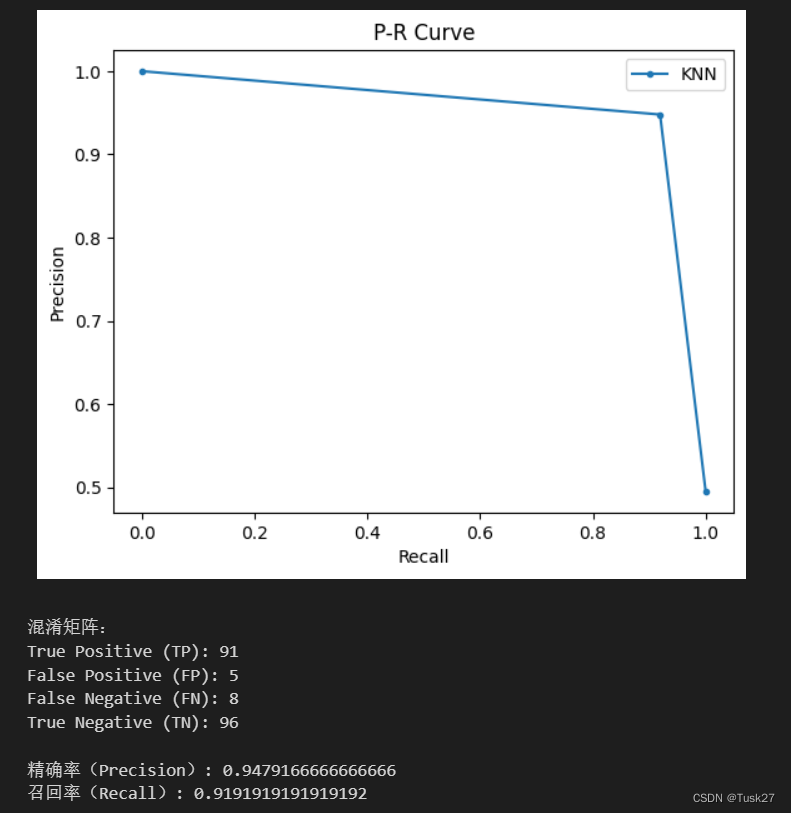
print("混淆矩阵:")
print("True Positive (TP):", tp)
print("False Positive (FP):", fp)
print("False Negative (FN):", fn)
print("True Negative (TN):", tn)
print("\n精确率(Precision):", precision)
print("召回率(Recall):", recall)
运行结果:可以看出本次实验的精确率和召回率较高。
三、实现ROC曲线、
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
# 生成样本数据
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5,
n_redundant=0, n_classes=2, weights=[0.3, 0.7], random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练模型
clf = LogisticRegression()
clf.fit(X_train, y_train)
# 得到预测概率
y_score = clf.predict_proba(X_test)[:, 1]
# 计算fpr和tpr
fpr, tpr, _ = roc_curve(y_test, y_score)
# 计算AUC
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.figure(figsize=(8,6))
lw = 2
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
1. 生成数据集
和绘制P-R曲线一样同样使用make_classification生成数据集,并划分训练集和测试集。
2.训练模型
创建一个LogisticRegression分类器,使用训练数据X_train和y_train来拟合(训练)模型。
3.计算出FPR、TPR和AUC
roc_curve函数计算接收者操作特征(ROC)曲线的假FPR和TPR。另外使用auc函数计算ROC曲线下的面积,得到AUC值。
4.绘制ROC曲线
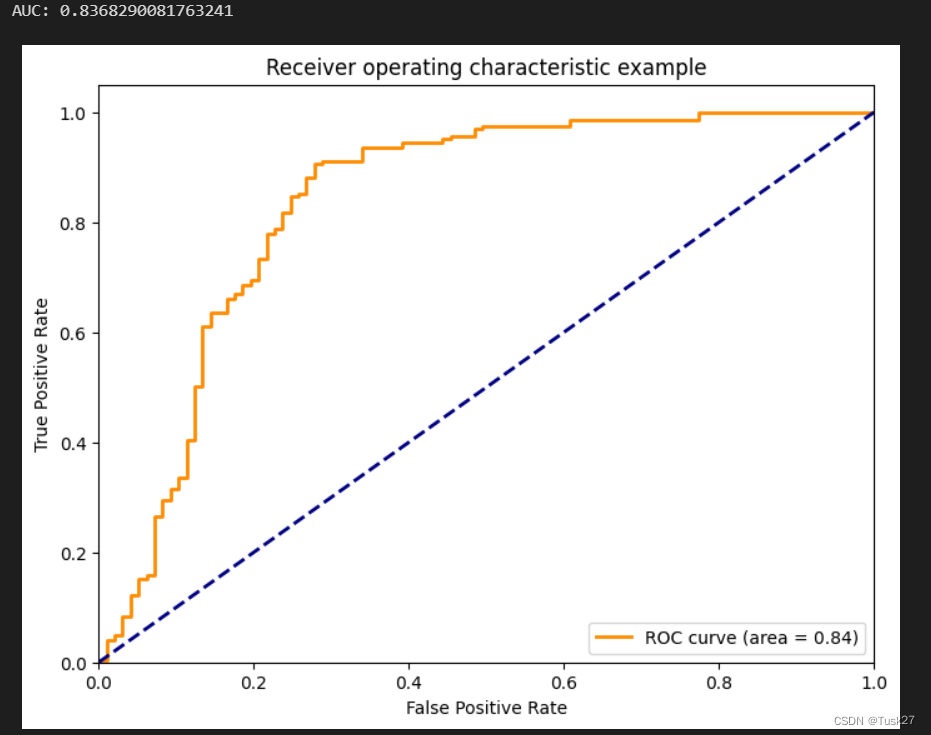
运行结果:AUC的值为0.8368290081763241,可以看出此次运行的结果较好。















 3151
3151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









