






在开发爬虫的使用,scrapy shell可以帮助我们定位需要爬取的资源
启动Scrapy Shell
在终端中输入以下内容即可启动scrapy shell,其中url是要爬取的页面,可以不设置
scrapy shell <url>
scrapy shell还支持本地文件,如果想用爬取本地的web页面副本,可以用以下方式。使用文件相对路径时,确保使用 “./” 或者 “../” 或者 “file://” ,直接scarpy shell index.html的方式会报错
# UNIX-style scrapy shell ./path/to/file.html scrapy shell ../other/path/to/file.html scrapy shell /absolute/path/to/file.html # File URI scrapy shell file:///absolute/path/to/file.html
Shell使用方法
可用的方法
shelp(): 打印可用的对象和方法fetch(url[, redirect=True]): 爬取新的 URL 并更新所有相关对象fetch(request): 通过给定request 爬取,并更新所有相关对象view(response): 使用本地浏览器打开给定的响应。这会在计算机中创建一个临时文件,这个文件并不会自动删除
可用的Scrapy对象
Scrapy shell自动从下载的页面创建一些对象,如 Response 对象和 Selector 对象。这些对象分别是
crawler: 当前Crawler 对象spider: 爬取使用的 Spider,如果没有则为Spider对象request: 最后一个获取页面的Request对象,可以使用 replace() 修改请求或者用 fetch() 提取新请求response: 最后一个获取页面的Response对象settings: 当前的Scrapy设置
简单示例
fetch('https://scrapy.org') response.xpath('//title/text()').get() # 输出 # 'Scrapy | A Fast and Powerful Scraping and Web Crawling Framework' from pprint import pprint pprint(response.headers)
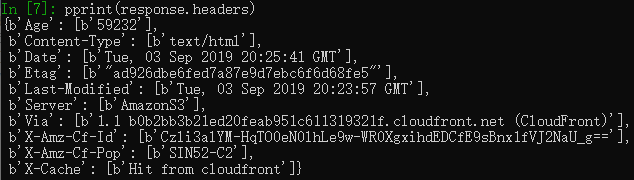
在Spider内部调用Scrapy shell来检查响应
有时你想检查Spider某个特定点正在处理的响应,只是为了检查你期望的响应是否到达那里。
可以通过使用该scrapy.shell.inspect_response功能来实现。
import scrapy class MySpider(scrapy.Spider): name = "myspider" start_urls = [ "http://example.com", "http://example.org", "http://example.net", ] def parse(self, response): # We want to inspect one specific response. if ".org" in response.url: from scrapy.shell import inspect_response inspect_response(response, self) # Rest of parsing code.
启动爬虫后我们就开始检查工作,注意这里不能使用fectch(),因为Scrapy引擎被shell阻塞了
response.xpath('//h1[@class="fn"]')
最后,按Ctrl-D(或Windows中的Ctrl-Z)退出shell并继续爬行。
实例
爬取Scrapy官方文档
fetch("https://docs.scrapy.org/en/latest/index.html")
根据页面标签,可以知道,根据标题等级,标题在h1、h2标签中
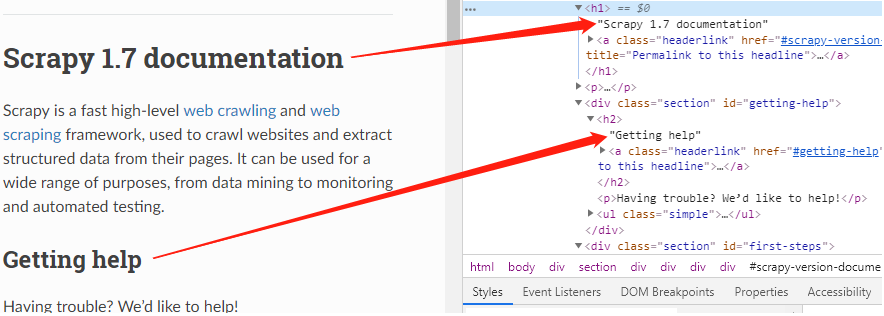
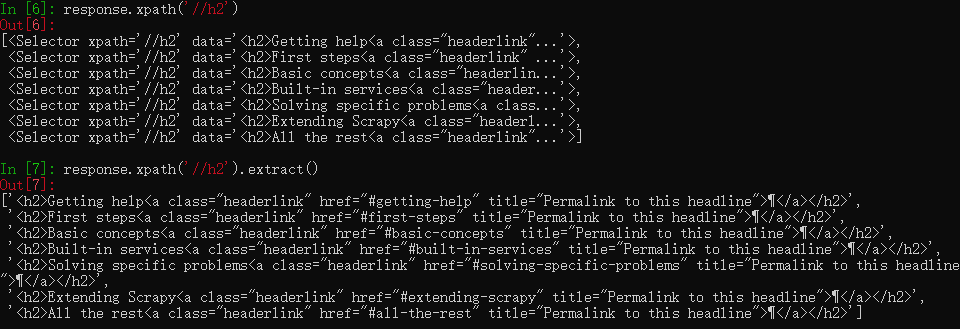
以爬取标题二为例,我们可以用xpath定位这些元素
response.xpath('//h2')
此时仍然是一个xpath对象,需要用extract()提取出来
response.xpath('//h2').extract()
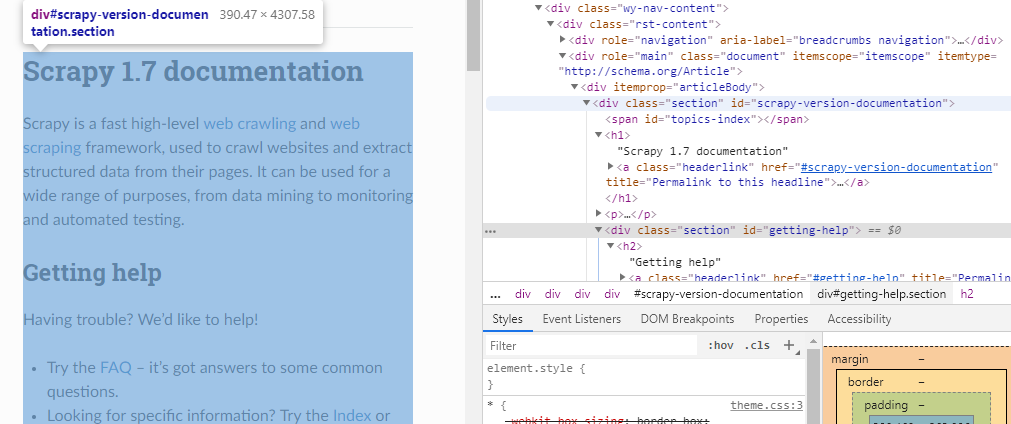
文档主体都在div标签中,class名称为“section”,如果想爬取文档内容,可以这样
response.xpath("//div[@class='section']").extract()
然后再用正则表达式提取我们需要的内容
import re data = response.xpath("//div[@class='section']").extract() # 一个列表 pattern = re.compile("(?<=<h2>).*(?=<a)") # 响应中可以看到结果为:<h2>二级标题<a class=……,用正则匹配出中间的标题 title = re.findall(pattern, data[0]) print(title)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









