






2019软件工程第三次作业
数独游戏
戳这里进入Github项目
第一眼看到要做数独的时候,脑海里的第一反应就是用深搜。现在好了,确定了算法,接下来就是要去实现它,可是对于将近半年没写过深搜的我要写一个如此经典的深搜还是有些难度(花了一个下午写bug改bug,弱鸡实锤)。
| psp表格 |
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10min | 10min |
| Estimate | 估计这个任务需要多少时间 | 25h | 27h |
| Development | 开发 | 5h | 5h |
| Analysis | 需求分析 (包括学习新技术) | 30min | 30min |
| Design Spec | 生成设计文档 | 1h | 45min |
| Design Review | 设计复审 | 1h | 1h |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 2h | 3h |
| Design | 具体设计 | 30min | 15min |
| Coding | 具体编码 | 4h | 4h |
| Code Review | 代码复审 | 5h | 5h |
| Test | 测试(自我测试,修改代码,提交修改) | 1h | 1h |
| Reporting | 报告 | 3h | 3h |
| Test Report | 测试报告 | 30min | 30min |
| Size Measurement | 计算工作量 | 30min | 30min |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 1h | 2h |
| 合计 | 25h | 27h |
由于之前没有做计划评估的习惯,所以对这些工作流程的时间观念还是有些差。第一次做出了计划,实施完之后发现还是有些高估了自己,实际用时超出了预计。
| 计算模块接口的设计与实现过程 |
对于这个题目首先想到的就是深搜+回溯的算法,算法复杂度约O($n^{2n}$),我打算将大体结构分为一个求解数独的函数、一个查找当前位置可能存在的解的search()函数用于在数独求解过程中,当查找不到解时进行回溯操作然后再继续搜索…
先是头文件和全局变量:
#include "stdafx.h"
#include<iostream>
#include<fstream>
#include<string.h>
#include<math.h>
using namespace std;
int mark[10][10][10] = { 0 };
int n_size = 0;
int sgle[10][10][10] = { 0 };
int sudo[10][10] = { 0 };
bool success = false;
int times;以下为查找可能存在的解的函数:
bool search(int x, int y)//查找当前位置可能存在的解{
for (int i = 0; i < n_size; i++) {
mark[x][y][sudo[i][y]] = 1;//判断列
}
for (int i = 0; i < n_size; i++) {
mark[x][y][sudo[x][i]] = 1;//判断行
}
if (n_size == 4 || n_size == 6 || n_size == 8 || n_size == 9) {
if (n_size == 4 || n_size == 9) {
int n = (int)sqrt(n_size);
int k1 = x / n;
int k2 = y / n;
k1 *= n;
k2 *= n;
for (int i = k1; i < k1 + n; i++)
for (int j = k2; j < k2 + n; j++) {
mark[x][y][sudo[i][j]] = 1;
}
}
else if (n_size == 6) {
int k1 = x / 2;
int k2 = y / 3;
k1 *= 2;
k2 *= 3;
for (int i = k1; i < k1 + 2; i++)
for (int j = k2; j < k2 + 3; j++) {
mark[x][y][sudo[i][j]] = 1;
}
}
else if (n_size == 8) {
int k1 = x / 4;
int k2 = y / 2;
k1 *= 4;
k2 *= 2;
for (int i = k1; i < k1 + 4; i++)
for (int j = k2; j < k2 + 2; j++) {
mark[x][y][sudo[i][j]] = 1;
}
}
}
for (int i = 1; i <= n_size; i++) {
if (mark[x][y][i] == 0) {
return true;
}
}
return false;
}其中我将这个search函数设置为bool类型,目的是查找到当前格不存在解的时候就返回false告诉数独求解函数,使求解函数进行回溯从而尝试其他可能存在的解。
以下为数独求解函数::
void sudoku(int x, int y, char*o) //深度优先搜索,数独求解函数{
for (int i = 1; i <= n_size; i++)
{
mark[x][y][i] = 0;
}
if (x == n_size) {
success = true;
ofstream InFire(o, ios::app);
for (int i = 0; i < n_size; i++) {
for (int j = 0; j < n_size; j++)
InFire << sudo[i][j] << ' ';
InFire << endl;
}
InFire << endl;
}
else if (x < n_size&&y < n_size && !sudo[x][y]) {
if (search(x, y)) {
for (int k = 1; k <= n_size; k++) {
if (!mark[x][y][k]) {
sudo[x][y] = k;
if (y < n_size - 1) {
sudoku(x, y + 1, o);
}
else if (x < n_size) {
sudoku(x + 1, 0, o);
}
sudo[x][y] = 0;
}
}
}
else
return;
}
else if (x < n_size&&y < n_size&&sudo[x][y]) {
if (y < n_size - 1) {
sudoku(x, y + 1, o);
}
else if (x < n_size) {
sudoku(x + 1, 0, o);
}
}
}比较经典的深度优先搜索题目(如开头所说,改了好久的BUG)这里就不在赘述了。我用了一个bool变量success来判断数独是否有解,由于之前作业上写明数独确保仅有一个解所以我在程序找到一个解以后就通过success的值判断退出,后来想要尝试求解多解数独,于是将if(x==n_size)里的return;删除,这样就求出了数独的多解。
接下来就是主函数:
int main(int argc, char*argv[]) {
FILE *fp;
char *file_path = { "./" }, *output = { "./" };
for (int i = 0; i < argc; i++)//读取命令行参数(这里借鉴了李承泽同学的方法)
{
if (strlen(argv[i]) == 1)
{
if (i == 2)
n_size = atoi(argv[i]);
if (i == 4)
times = atoi(argv[i]);
}
if (i == 6)
file_path = argv[i];
if (i == 8)
output = argv[i];
}
fopen_s(&fp,file_path, "r");
if (fp == NULL)
return -1;
for (int t = 1; t <= times; t++)//读入盘面
{
for (int i = 0; i < n_size; i++) {
for (int j = 0; j < n_size; j++)
fscanf_s(fp, "%d", &sudo[i][j]);
}
cout << endl;
single();//判断初始盘面中存在的唯一解
ofstream InFire(output, ios::app);
InFire << "盘面" << t << ":" << endl;
sudoku(0, 0, output);
if (!success)
InFire << "No answer!!" << endl;
success = false;//完成一次盘面计算后数据重新初始化
memset(sudo, 0, sizeof(sudo));
memset(mark, 0, sizeof(mark));
memset(sgle, 0, sizeof(sgle));
}
return 0;
}| 优化 |
能不能在现有的基础上进一步优化算法呢?如果在现有的盘面上有的格子有且仅有一个解,则直接将唯一解填入,数独是可以产生连锁反应的,一个地方填入唯一解就可能使得其他地方所存在的可能解的数量减少,从而大大减少求解时间。于是我写了一个判断地方格唯一解的函数。
void single() {
int count = 0;
for (int i = 0; i < n_size; i++) {
for (int j = 0; j < n_size; j++) {
for (int k = 0; k<n_size; k++)//判断行
if (sudo[k][j] && !sgle[i][j][sudo[k][j]]) {
count++;
sgle[i][j][sudo[k][j]] = 1;
}
for (int k = 0; k < n_size; k++) //判断列
if (sudo[i][k] && !sgle[i][j][sudo[i][k]]) {
count++;
sgle[i][j][sudo[i][k]] = 1;
}
if (n_size == 4 || n_size == 6 || n_size == 8 || n_size == 9)//判断宫
{
if (n_size == 4 || n_size == 9) {
int n = (int)sqrt(n_size);
int k1 = i / n;
int k2 = j / n;
k1 *= n;
k2 *= n;
for (int k = k1; k < k1 + n; k++)
for (int l = k2; l < k2 + n; l++)
if (sudo[k][l] && !sgle[i][j][sudo[k][l]]) {
count++;
sgle[i][j][sudo[k][l]] = 1;
}
}
else if (n_size == 6) {
int k1 = i / 2;
int k2 = j / 3;
k1 *= 2;
k2 *= 3;
for (int k = k1; k < k1 + 2; k++)
for (int l = k2; l < k2 + 3; l++)
if (sudo[k][l] && !sgle[i][j][sudo[k][l]]) {
sgle[i][j][sudo[k][l]] = 1;
count++;
}
}
else if (n_size == 8) {
int k1 = i / 4;
int k2 = j / 2;
k1 *= 4;
k2 *= 2;
for (int k = k1; k < k1 + 4; k++)
for (int l = k2; l < k2 + 2; l++)
if (sudo[k][l] && !sgle[i][j][sudo[k][l]]) {
sgle[i][j][sudo[k][l]] = 1;
count++;
}
}
}
if (count == n_size - 1)\\即只剩余一个解 {
for (int k = 1; k <= n_size; k++)
{
if (!sgle[i][j][k] && !sudo[i][j]) {
sudo[i][j] = k;
break;
}
}
}
count = 0;
}
}现在来将改良版与初始版本进行对比:
以下是没有加入single()函数的性能测试结果:
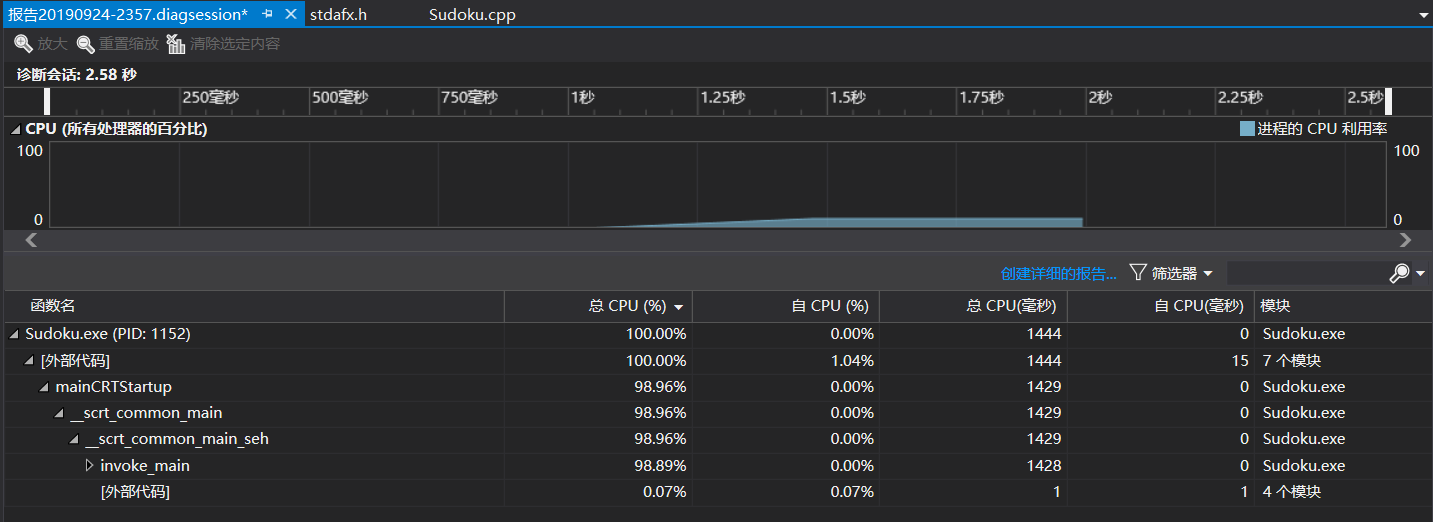
以下是加入single()函数之后的性能测试结果:
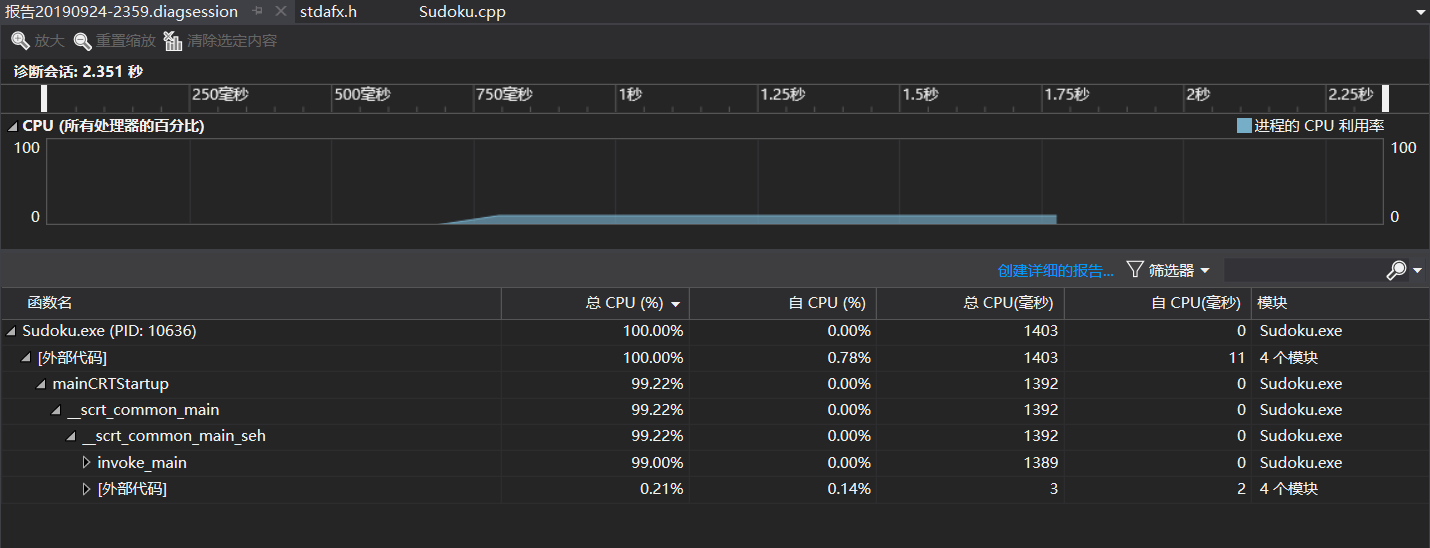
可以看出加入single()函数后程序CPU占用增加但是运行的时间成功减少,程序在一定程度上得到了优化。
|
|
首先是九宫格的求解:
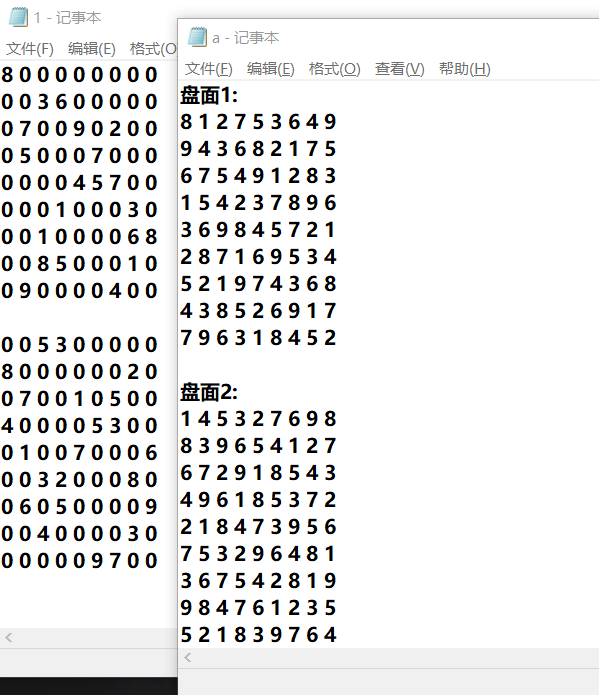
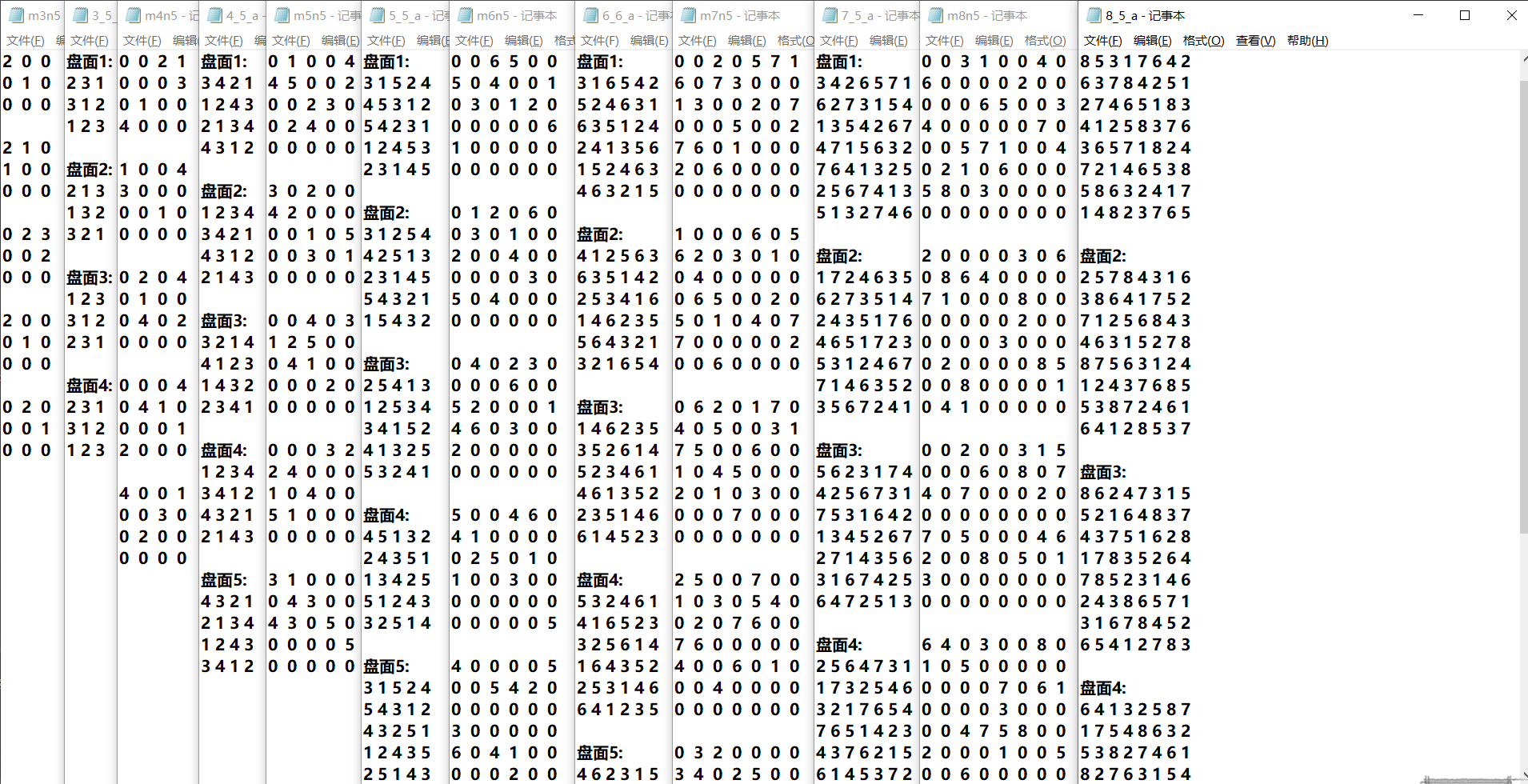
接下来就是3、4、5、6、7、8宫格的求解结果辽。先附上cmd运行图例:

下面是数据集和程序得出的数据集解:
| 最后来总结一下 |
之前大一大二没有那么注重代码的规范问题,遇到了编译成功后编译器提出的警告也是选择性无视2333,都是一切以编译成功,能正确运行就“大功告成”了,这是与现在最大的区别之处,通过这次的作业我也学到了不仅要确保代码正确运行,提升代码的鲁棒性也是同样重要的,这在以后的学习或是工作过程中都是不可或缺的环节。















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









