






1.中软国际华南区技术总监曾老师还会来上两次课,同学们希望曾老师讲些什么内容?(认真想一想回答)
答:展示一些使用python技术进行的实际项目(不违反公司规定下)。
2.中文分词
- 下载一中文长篇小说,并转换成UTF-8编码。
2. 使用jieba库,进行中文词频统计,输出TOP30的词及出现次数。
import jieba txt = open("雪中悍刀行.txt","r",encoding='utf-8').read() a = jieba.cut(txt) counts = {} for b in a: if len(b) == 1: continue else: counts[b] = counts.get(b,0) + 1 items = list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i in range(30): b,count = items[i] print("{0:<6}{1:>3}".format(b,count))

3.排除一些词、合并同一词。
import jieba txt = open("雪中悍刀行.txt","r",encoding='utf-8').read() ex = {"女子",'袁庭山','江南','仙侠','年轻','丫鬟','武当山','古剑'} a = jieba.cut(txt) counts = {} for b in a: if len(b) == 1: continue else: counts[b] = counts.get(b,0) + 1 for a in ex: del(counts[a]) items = list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i in range(30): b,count = items[i] print("{0:<6}{1:>3}".format(b,count))

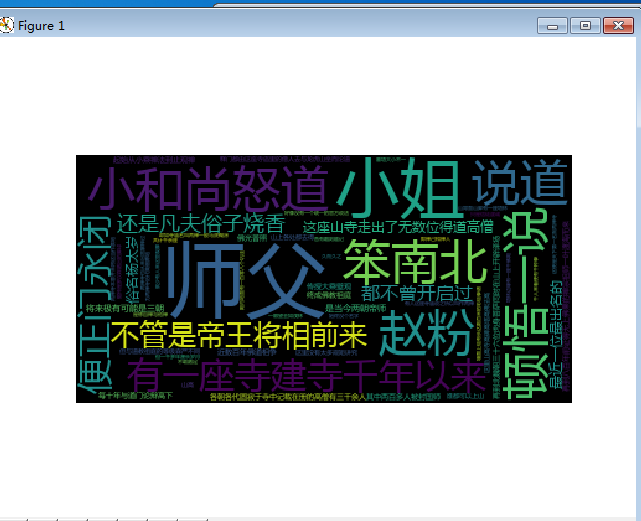
4.使用wordcloud库绘制一个词云。
from wordcloud import WordCloud import matplotlib.pyplot as plt txt = open('雪中.txt','r',encoding = 'utf-8').read() mywc = WordCloud().generate(txt) plt.imshow(mywc) plt.axis("off") plt.show()















 5456
5456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









