






目录
1. 传统缓存策略
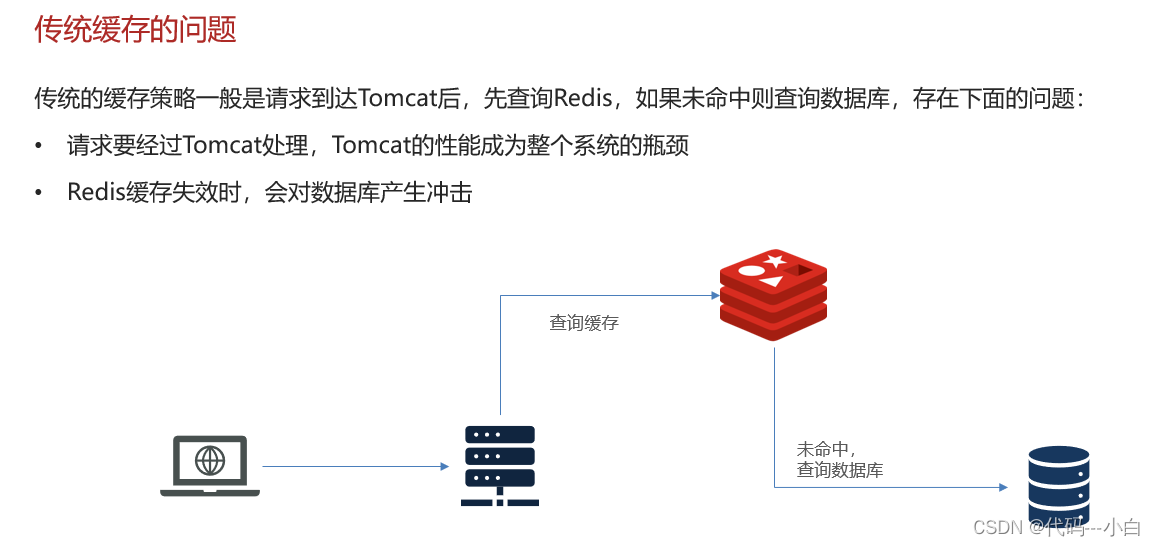
存在下面的问题:
•请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
•Redis缓存失效时,会对数据库产生冲击
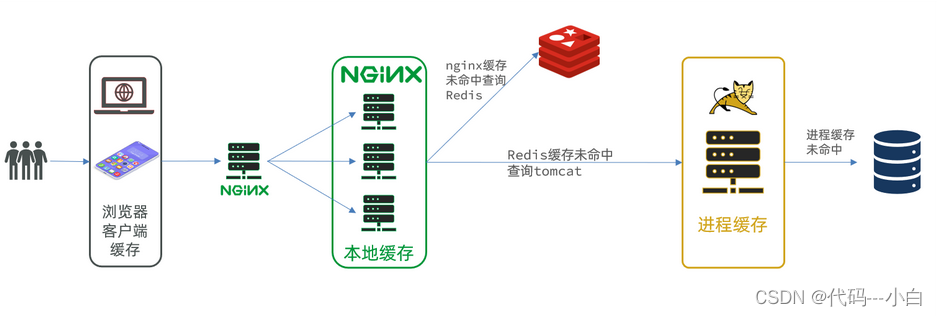
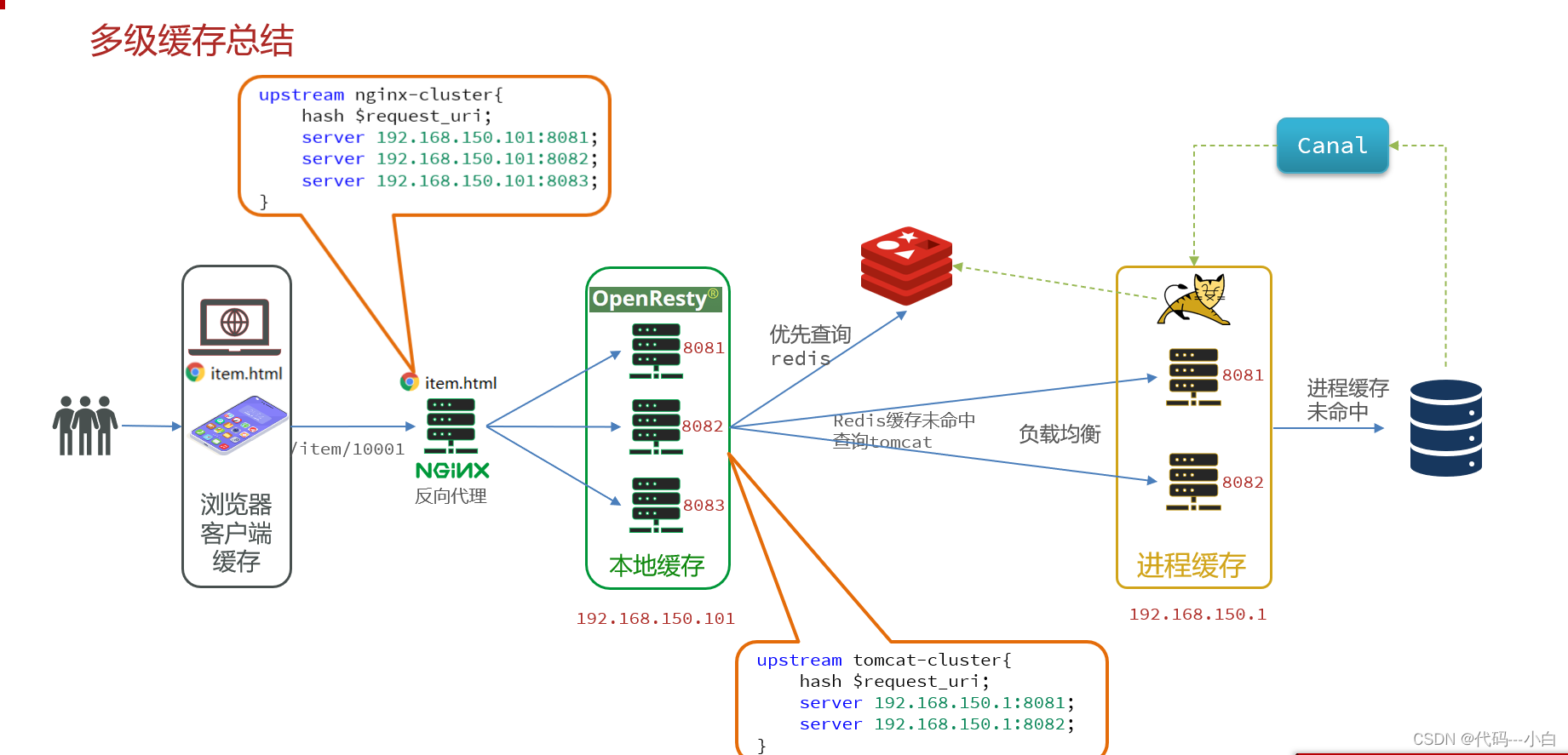
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
- 浏览器访问静态资源时,优先读取浏览器本地缓存
- 访问非静态资源(ajax查询数据)时,访问服务端
- 请求到达Nginx后,优先读取Nginx本地缓存
- 如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
- 如果Redis查询未命中,则查询Tomcat
- 请求进入Tomcat后,优先查询JVM进程缓存
- 如果JVM进程缓存未命中,则查询数据库
2. 多级缓存方案
在多级缓存架构中,Nginx内部需要编写本地缓存查询、Redis查询、Tomcat查询的业务逻辑,因此这样的nginx服务不再是一个反向代理服务器,而是一个编写业务的Web服务器了。
因此这样的业务Nginx服务也需要搭建集群来提高并发,再有专门的nginx服务来做反向代理,如图:
另外,我们的Tomcat服务将来也会部署为集群模式:

可见,多级缓存的关键有两个:
-
一个是在nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询
-
另一个就是在Tomcat中实现JVM进程缓存
其中Nginx编程则会用到OpenResty框架结合Lua这样的语言。
3. JVM进程缓存
3.1 初识Caffeine
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
- 分布式缓存,例如Redis:
- 优点:存储容量更大、可靠性更好、可以在集群间共享
- 缺点:访问缓存有网络开销
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 进程本地缓存,例如HashMap、GuavaCache:
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
我们今天会利用Caffeine框架来实现JVM进程缓存。
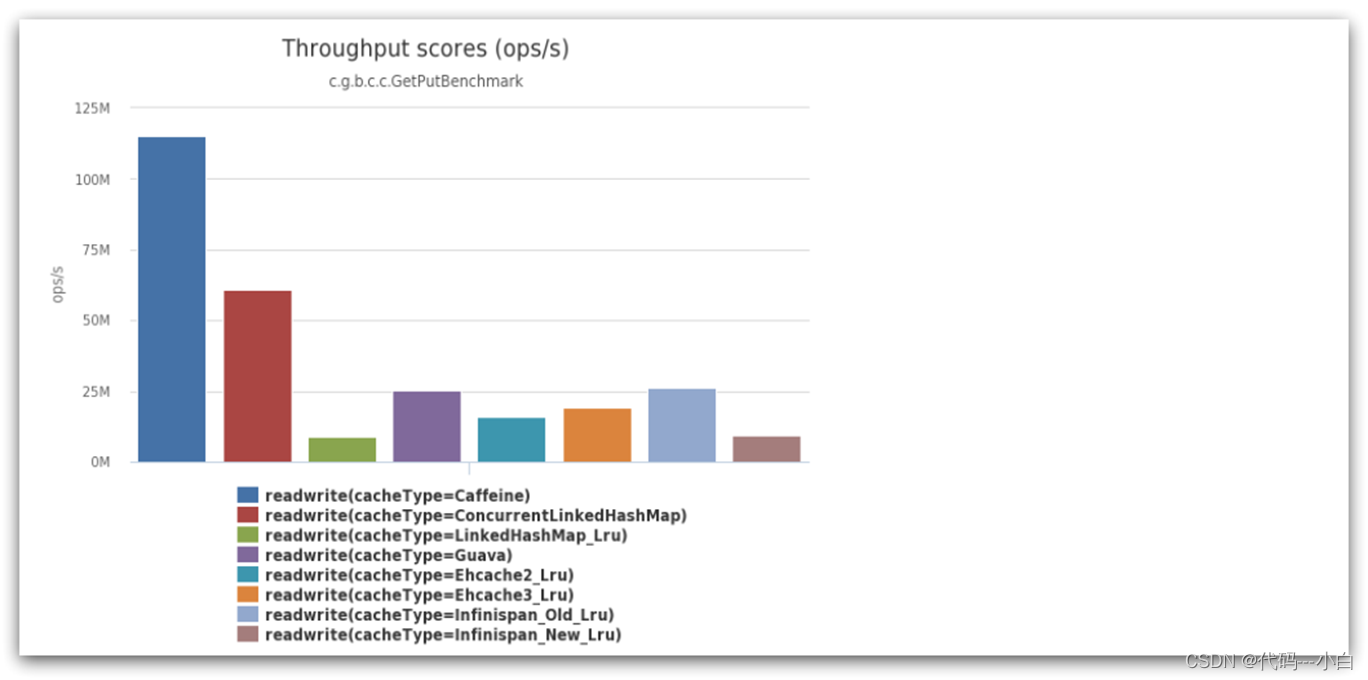
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。GitHub地址:https://github.com/ben-manes/caffeine
Caffeine的性能非常好,下图是官方给出的性能对比:
4. 实现进程缓存
多级缓存的实现离不开Nginx编程,而Nginx编程又离不开OpenResty。
4.1 安装OpenResty
OpenResty® 是一个基于 Nginx的高性能 Web 平台,用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。具备下列特点:
- 具备Nginx的完整功能
- 基于Lua语言进行扩展,集成了大量精良的 Lua 库、第三方模块
- 允许使用Lua自定义业务逻辑、自定义库
官方网站: https://openresty.org/cn/
4.2.Redis缓存预热
添加Redis缓存的需求
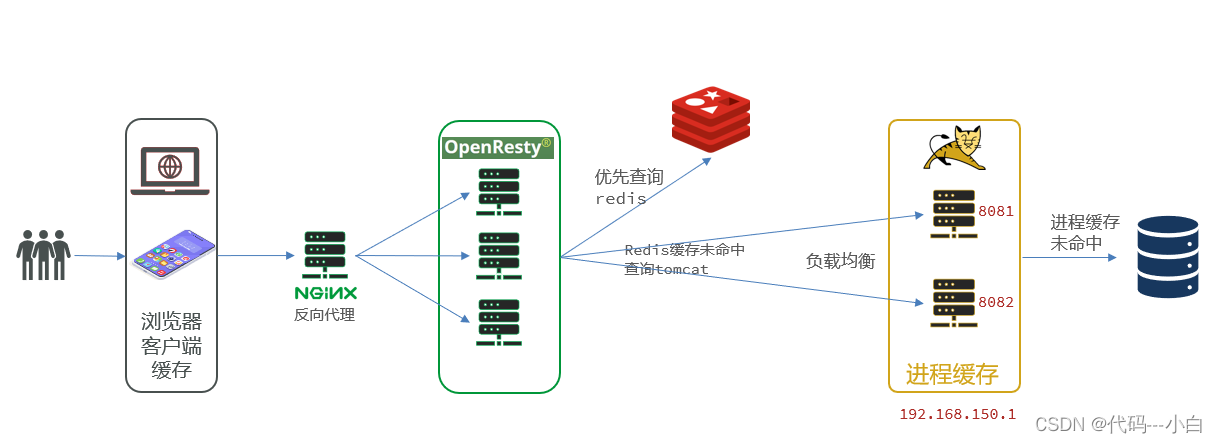
冷启动与缓存预热
Redis缓存会面临冷启动问题:
冷启动:服务刚刚启动时,Redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力。
缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到Redis中。
数据量较少时,并且没有数据统计相关功能,目前可以在启动时将所有数据都放入缓存中。
4.3.缓存同步
大多数情况下,浏览器查询到的都是缓存数据,如果缓存数据与数据库数据存在较大差异,可能会产生比较严重的后果。
所以我们必须保证数据库数据、缓存数据的一致性,这就是缓存与数据库的同步。
4.3.1 缓存数据同步策略
缓存数据同步的常见方式有三种:
而异步实现又可以基于MQ或者Canal来实现:
1)基于MQ的异步通知:
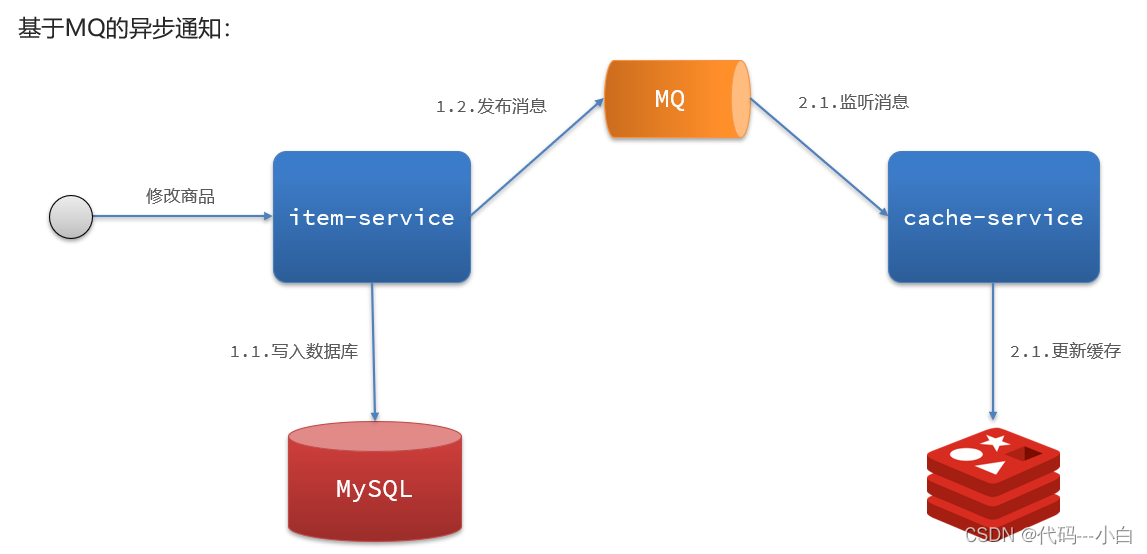
解读:
- 商品服务完成对数据的修改后,只需要发送一条消息到MQ中。
- 缓存服务监听MQ消息,然后完成对缓存的更新
依然有少量的代码侵入。
2)基于Canal的通知
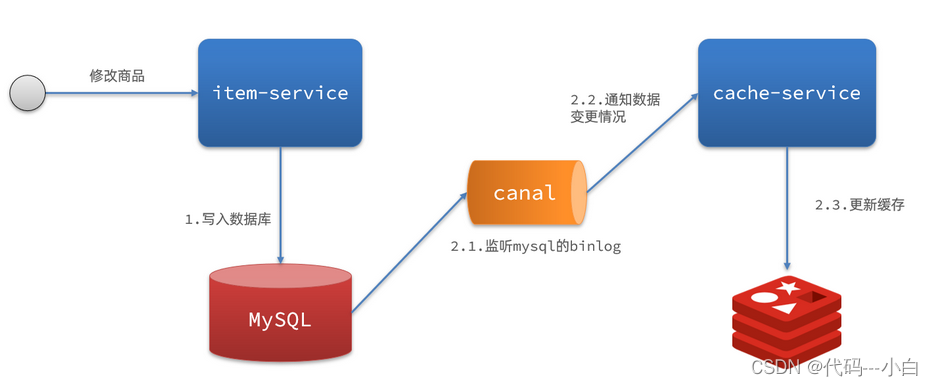
解读:
- 商品服务完成商品修改后,业务直接结束,没有任何代码侵入
- Canal监听MySQL变化,当发现变化后,立即通知缓存服务
- 缓存服务接收到canal通知,更新缓存
代码零侵入
4.3.2 Canal介绍
Canal [kə'næl],译意为水道/管道/沟渠,canal是阿里巴巴旗下的一款开源项目,基于Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。GitHub的地址:https://github.com/alibaba/canal
Canal是基于mysql的主从同步来实现的,MySQL主从同步的原理如下:
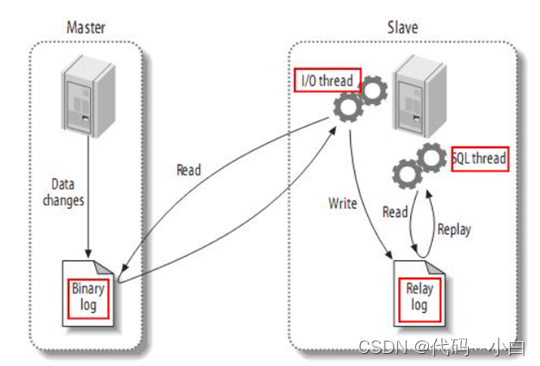
- 1)MySQL master 将数据变更写入二进制日志( binary log),其中记录的数据叫做binary log events
- 2)MySQL slave 将 master 的 binary log events拷贝到它的中继日志(relay log)
- 3)MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
而Canal就是把自己伪装成MySQL的一个slave节点,从而监听master的binary log变化。再把得到的变化信息通知给Canal的客户端,进而完成对其它数据库的同步。
4.3.3 监听Canal
Canal提供了各种语言的客户端,当Canal监听到binlog变化时,会通知Canal的客户端。
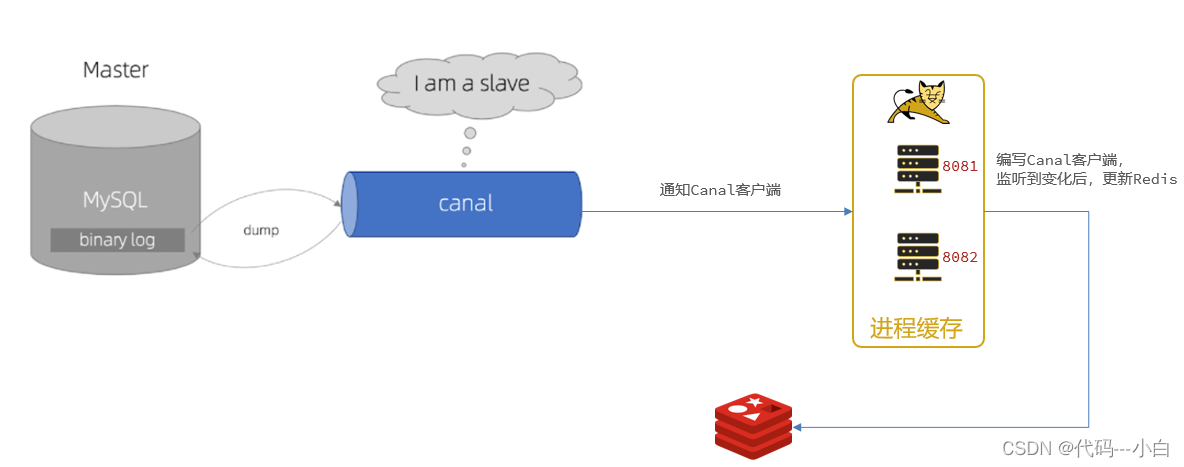
我们可以利用Canal提供的Java客户端,监听Canal通知消息。当收到变化的消息时,完成对缓存的更新。
不过这里我们会使用GitHub上的第三方开源的canal-starter客户端。地址:https://github.com/NormanGyllenhaal/canal-client
与SpringBoot完美整合,自动装配,比官方客户端要简单好用很多。
总结:
参考文献:
黑马程序员Redis入门到实战教程,深度透析redis底层原理+redis分布式锁+企业解决方案+黑马点评实战项目_哔哩哔哩_bilibili















 1379
1379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









