






MySQL/Oracle数据库(一)
1.数据库的发展史
文件系统→网络模型→关系型数据库和结构化查询语言(MySQL)→”关系—对象”型
主要的关系型数据库有:Oracle、MySQL(开源)、DB2、Sybase、MS SQL、SQL Server- 关系型数据库采用组织数据,一个数据库由多个表组成,多个表之间存在着响应的关系.
2.数据库的基本要求
(1)、基本的SQL操作(CRUD)
(2)、多链表查询、分组查询以及子查询
(3)、常用数据库的单行函数
(4)、常用数据库的基本命令
(5)、常用数据库的开发工具
(6)、事物概念
(7)、索引、视图等其他对象
3.MySQL特性
- 可移植性、列类型、可伸缩性和限制以及连接性
- 基本的操作(create、add、drop、rename、modify)
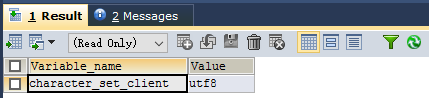
在MySQL中查询显示当前客户端的字符集:
show variables like 'character_set_client';- 常用字符集编码:ASCII、ISO-8859-1(常用于转码)、GB2312、GBK、UTF-8
4.SQL语句分类
DDL(数据库定义语言):定义数据库对象(库、表、列、索引)的操作,DDL语句是自动提交的,用于定义数据库结构,如:创建、修改或删除数据库对象,有如下SQL语句
CREAT:创建数据库表 ALTER:更改表结构,添加、删除、修改列长度等 DROP:删除表 CREATE INDEX:在表上建立索引 DROP INDEX:删除索引DML(数据操作语言):定义数据库记录的操作,需要手动提交的(如:Oracle),主要用于查询与修改数据记录,基本语句如下:
INSERT:添加数据到数据库中 DELETE:删除数据库中的数据 UPDATE:修改数据库中的数据 SELECT:选择(查询)数据,为SQL语言的基础DCL(数据控制语言):定义对数据库、表、字段、用户的访问权限和安全等级(GRANT、REVOKE),基本的SQL语句如下:
GRANT:授予访问权限 REVOKE:撤销访问权限 COMMIT:提交事物处理 ROLLBACK:事物处理回退 SAVEPOINT:设置保存点,可以直接回退到保存点 LOCK:对数据库的特定部分进行锁定- Transaction Control:事物控制(commit、rollback、savepoint)
5.SQL语句规范
- SQL语句不区分大小写(关键字建议大写);
- 字符串常量大小写敏感;
- SQL语句可单行或多行书写,以”;”表示语句结束;
- 关键词不能跨行;
- 数字与日期使用的算数运算符:
- 数字: +、-、*、/
- 日期只做加运算
- 关于注释语句:
- 在MySQL中可以使用:#或/**/;
- 在Oracle中使用:/**/或–(双横线);
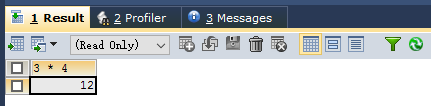
所有的查询语句均有from来源,没有的则使用dual,如:
SELECT 3*4 FROM DUAL;
6.基本的数据库操作
(1)、列出所有数据库:SHOW DATABASE
(2)、创建数据库
格式:CREDATE DATABASE 数据库名;
如:
CREATE DATABASE djh;
(3)、删除数据库
格式:DROP DATABASE 数据库名;
如:
DROP DATABASE djh;
(4)、选中数据库:可以直接使用鼠标点击相应的数据库,也可以使用SQL语句来实现数据库的切换,其语句为:
use 数据库名
如:use djh;
- 数据库对象:
- 表:基本的数据存储对象,以行和列的形式存在
- 约束:执行数据校验,保证数据库相关信息的表
- 视图:一个或多个表独居的逻辑显示
- 索引:用于提高查询的性能
- 数据字典:系统表,存放数据库相关信息的表
- 数据库对象的命名规则:
- 必须以字母开头
- 可以包含数字或三个特殊字符(#、_、$)
- 不要使用数据库的保留字
- 同一schema下的对象不能同名
- 当命名包含两个单词及以上时,建议使用下划线连接
- MySQL支持多种类型,如:
- 数值类型:
//M表示数据的总位数,D表示有几位小数
BIT(1字节)、SMALLINT(2字节)、INT(4字节)、BOOL、FLOAT(M,D)、DOUBLE(M,D)、DECIMAL
- 日期/时间类型:
DATA(4字节)、DATATIME、TIMESTAMP、TIME、YEAR
- 字符串(字符类型):
CHAR、VARCHAR、BINARY、BLOB、TEXT...
- Oracle常用的类型有:
- 数值: NUMBER(M,D)
- 字符:VARCHAR2() //在括号内注明长度
- 日期: DATE
7.SQL(Structured Query Language)— MySQL:结构化查询语言
创建和管理表:
创建表
格式:
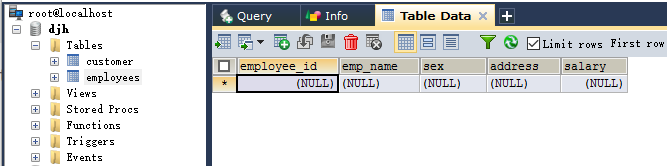
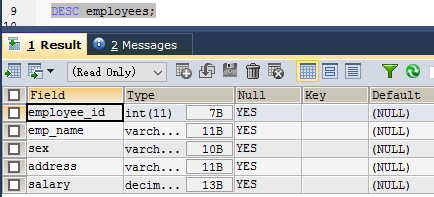
create table table_name(column1 type1, column2 type2, ...); 如: CREATE TABLE employees( employee_id INT, emp_name VARCHAR(18), sex VARCHAR(2), address VARCHAR(30), salary DECIMAL );- 使用:desc table_name;可以查看到表中所的所有列
删除表
格式:
drop table table_name; 如: drop table employees;
使用alter table语句修改表的结构
修改类型:(还有当字段只包含空值(空值不是0)时,类型和大小都可修改,否则修改可能不能成功)
格式:
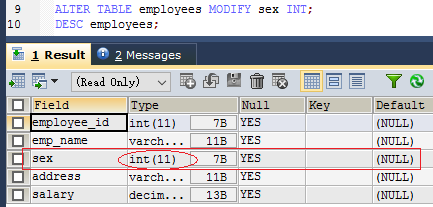
alter table 表名 modify 列名 列类型; 如: ALTER TABLE employees MODIFY sex INT;- 注意:修改默认值,只会对以后插入有作用,对前面的数据不会有影响
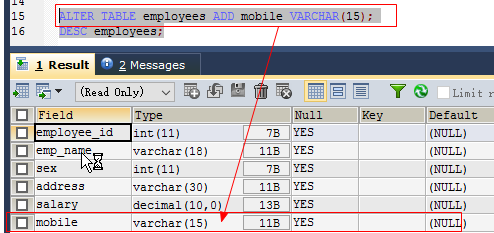
增加列(新家的字段只能加到表的最后)
格式:
alter table 表名 add 列名 列类型; 如: alter table employees add mobile varchar(15);
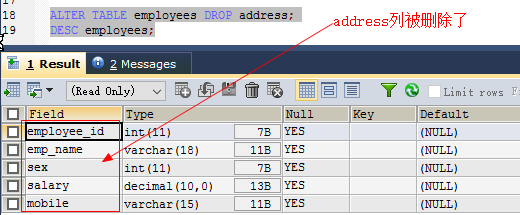
删除列:(删除大表中的字段时间较长,需要回收空间,自动释放在数据块中占用的空间)
格式:
alter table 表名 drop column 列名; alter table 表名 drop 表名; //缺省关键字column 如: alter table employees drop address;
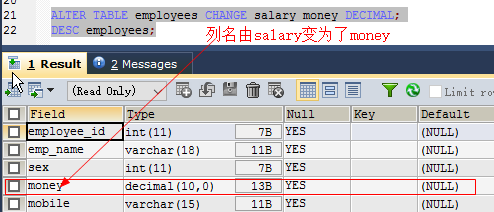
列改名:
格式:
alter table 表名 change 旧列名 新列名 列类型; 如: alter table employees change salary money decimal;
更改表名:
格式:
方法一:alter table 表名 rename 新表名 如: alter table employees reanme empts; 方法二:rename table 表名 to 新表名 如: rename table employees to empts;
约束以及DDL语法:
- 约束:用于保证数据库的完整性;当表中的数据有相互依赖性时,可以保护相关数据不被删除,数据库支持五类完整性约束,在MySQL中检查(check)约束是不起作用的
- 表级约束:在定义了所有列之后再定义约束
列级约束:在定义列的同时定义约束
not null(非空):
- 只能使用列级约束;
- 确保字段值不允许为空;
- 只能在字段级定义NULL值;
- 所有数据类型的值都可以是NULL;
- 空字符串和0不等于NULL
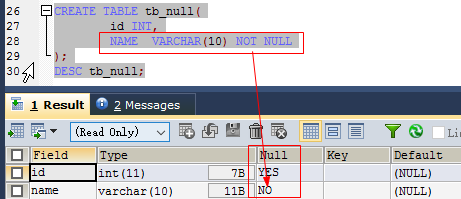
如:表示名字不能为空
create table tb_null( id int, name varchar(10) not null );
unique key(唯一键):
- 唯一性约束条件的字段允许出现多个NULL
- 同一张表内可建多个唯一约束
- 唯一约束可由多列组合而成
- 建唯一约束时MySQL会为之建立对应的索引
- 默认的唯一约束名与列名相同
- 确保所在的字段或者字段组合不出现重复
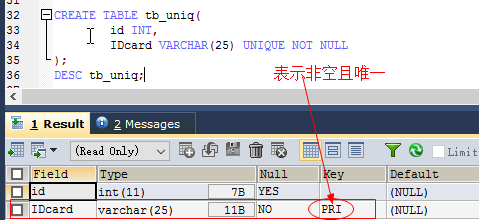
如:表示IDcard非空且唯一
create table tb_uniq( id int, IDcard varchar(25) unique not null );
primary key(主键):
- 从功能上说是非空且唯一
- 一个表中只允许一个主键
- 主键是表中唯一确定一行数据的字段
- 主键的约束名固定为primary
- 一般加上自动增长(auto_increment)
如:
create table tb_prim( id int primary key auto_increment, name varchar(5) );
foreign key(外键):
- 构建于一个表的两个字段或者两个表的字段之间的关系
- 确保相关的两个字段的关系
- 当主表的记录被字表参照时,主表记录不允许被删除
- 外键参照的只能是主键或者唯一键
格式:
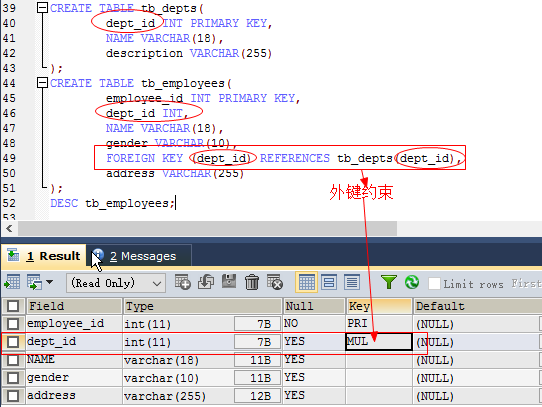
//方式一 foreign key (外键列名) references 主表名(参照列) //方式二:一般外键名由(表名+约束名)组成 constraint 外键名 foreign key (外键) REFERENCE 主表(关联列名) 如: CREATE TABLE tb_depts( dept_id INT PRIMARY KEY, NAME VARCHAR(18), description VARCHAR(255) ); CREATE TABLE tb_employees( employee_id INT PRIMARY KEY, dept_id INT, NAME VARCHAR(18), gender VARCHAR(10), FOREIGN KEY (dept_id) REFERENCES tb_depts(dept_id), #外键约束 address VARCHAR(255) );
(*):在MySQL中不起作用的约束,Oracle约束(check约束)
check(检查):
- 既可作为列级约束,也可作为表级约束
- 定义在字段上的每一条记录都要满足check条件
- 在check中定义检查的条件表达式,数据需要符合设置的条件
- 条件表达式不允许使用
如:
CREATE TABLE tb_chec( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(18), age INT CHECK(age > 18 AND age < 60) #CHECK约束 )
约束操作:
- 可增加或删除约束,但是不能直接修改
增加约束
- 可使约束启用与禁用
- 非空约束必须使用modify子句增加
- 只要是可以使用列级约束语法来定义的约束,都可以通过modify来增加该约束
格式:
ALTER TABLE table ADD [CONSTRAINT constraint] type (column); 如: #创建表 CREATE TABLE tb_stu( id INT, stnum INT, NAME VARCHAR(18), age INT, sex VARCHAR(2) ); #在后面增加主键约束 ALTER TABLE tb_stu ADD PRIMARY KEY (id) #自动增长 ALTER TABLE tb_stu MODIFY COLUMN id INT AUTO_INCREMENT
删除约束
- 约束被删除时不会对数据产生影响
- 当删除被外键参照的主键时,应该采用cascade关键字来级联删除外键,否则无法删除
格式:
alter table 表名 drop constraint 约束名 如: #创建表 CREATE TABLE tb_del( id INT PRIMARY KEY AUTO_INCREMENT, #主键约束 NAME VARCHAR(15) NOT NULL, #非空约束 sex VARCHAR(2), age INT, address VARCHAR(20) UNIQUE, del_id INT, CONSTRAINT FOREIGN KEY tb_del_fk (del_id) REFERENCES tb_main(id) #外键约束 )删除not null
格式:
ALTER TABLE 表名 MODIFY 列名 类型; 如: ALTER TABLE tb_del MODIFY NAME VARCHAR(15);
删除UNIQUE约束
格式
ALTER TABLE 表名 DROP INDEX 唯一约束名; 如:删除address的唯一性约束 ALTER TABLE tb_del DROP INDEX address
删除PRIMARY KEY约束
格式:
ALTER TABLE 表名 DROP PRIMARY KEY 如:(注意:是在没有自动增长的前提下) #先删除自动增长 ALTER TABLE tb_del MODIFY id INT #再删除主键约束 ALTER TABLE tb_del DROP PRIMARY KEY
删除FOREIGN KEY约束
格式
ALTER TABLE 表名 DROP FOREIGN KEY 外键名; 如:(注意:在MySQL中的外键名为系统自己创建的,其他数据库的外键名可以是自己创建的名字(如:tb_del_fk)) ALTER TABLE tb_del DROP FOREIGN KEY tb_del_ibfk_1
- (*)、非空约束可以通过modify来增加或删除,不能使用add constraint来增加非空约束
存储引擎
- 默认情况下,创建表不指定表的存储引擎,则会使用my.ini中的default-storage-engine=InnoDB指定的InnoDB,
可使用如下语法显示:
SHOW VARIABLES- 存储引擎的选择:
- MyISAM:应用于以读写操作为主,很少更新、删除,并对事物的完整性、并发性要求不高的情况
- InnoDB(默认值):应用于对事物的完整性要求高,在并发条件下要求数据的一致性的情况
- MEMORY:表的数据存放在内存中,访问效率高,但一旦服务关闭,表中的数据全部丢失
- MERGE:是一组MyISAM表的组合,可以突破对单个MyISAM表大小的限制,并提高访问效率
创建表时可以指定表的存储引擎:
CREATE TABLE (...) ENGINE=InnoDB 如: CREATE TABLE tb_sav( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(5), age INT )ENGINE=MYISAM
数据表的DML操作:
- insert、delete(truncate)、update、select
创建表
#创建部门表 CREATE TABLE departments( department_id INT PRIMARY KEY AUTO_INCREMENT, department VARCHAR(10) ) #创建员工表 CREATE TABLE employees( employee_id INT PRIMARY KEY AUTO_INCREMENT, first_name VARCHAR(10), last_name VARCHAR(10), salary INT, account VARCHAR(10), department VARCHAR(10) REFERENCES departments(department) );insert:
格式:
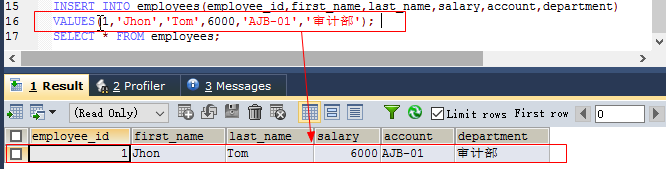
insert into 表名 [(column1, column2, ...)] values(value1, value2, ...); 如: INSERT INTO employees(employee_id,first_name,last_name,salary,account,department) VALUES(1,'Jhon','Tom',6000,'AJB-01','审计部');- 默认情况下一次插入操作只插入一行
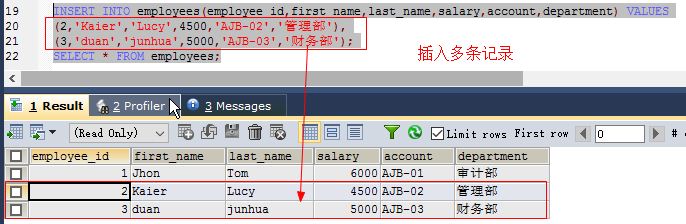
一次插入多条记录的格式:
insert into 表名 [(column1, column2, ...)] values (value1, value2, ...), (value5, value,6, ...); 如: INSERT INTO employees(employee_id,first_name,last_name,salary,account,department) VALUES (2,'Kaier','Lucy',4500,'AJB-02','管理部'), (3,'duan','junhua',5000,'AJB-03','财务部');插入子表创建表并插入数据:
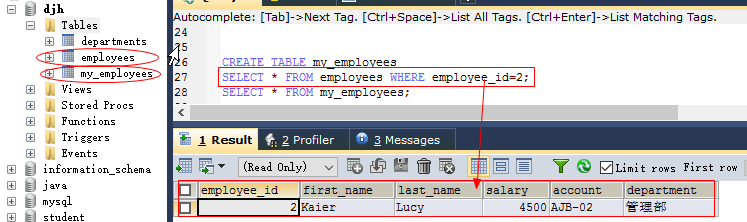
insert into 表名(列名...) selset语句 如: create table my_employees select * from employees where employee_id=2; #表示从表employees中将id=5的数据复制到表my_employees中
(“注意”):复制的是表的结构,不复制约束
delete:
- 删除不需要指出列名,因为删除总是整行的删除,where子句里是一个表达式,只有符合该条件的行才会被修改
没有where子句意味着where子句的表达式值为true 格式:
DELETE [from] table [where condition];删除可以一次删除多行,删除哪些行采用子句限定
删除某一行数据,如:
DELETE FROM employees WHERE employee_id=5;删除整个表:
DELETE FROM employees; //删除整个表,但是auto_increment不会清空TRUNCATE语句格式:(DDL语句)
TRUNCATE TABLE 表名 //表示完全清空一个表,并且将auto_increment也清空了
- 删除不需要指出列名,因为删除总是整行的删除,where子句里是一个表达式,只有符合该条件的行才会被修改
update:
格式:
SET column=value,... [WHERE condition];- 修改可以一次修改多行数据,修改的数据可用where子句限定,where子句里是一个条件表达式,只有符合
该条件的行才会被修改。没有where子句意味着where子句的表达式值为true 同时修改多列时,多列的修改中间采用逗号(,)隔开
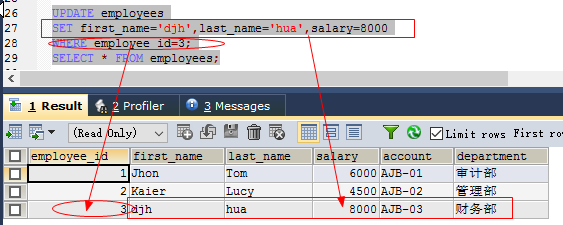
更新一行的单个数据,如:(表示更新数据表中id为5的工资选项)
UPDATE employees SET salary= 7555 WHERE employee_id=5; //或者 UPDATE employees SET salary= 7555 WHERE employee_id=5; //where判断的选项选择主键或者唯一键(unique)更新一行的多个(多列)数据
UPDATE employees SET first_name='djh',last_name='hua',salary=8000 WHERE employee_id=3;
select(查询)方式:条件查询、查询排序、聚合排序、分组排序
格式:
SELECT {参数} FROM 表名 如: SELECT * FROM tb_employees; *:表示所有的列 FROM:提供数据源(表名/视图) 默认选择所有行定义字段的别名:
- 改变列的标题头
- 用于表示结果的含义
- 作为列的别名
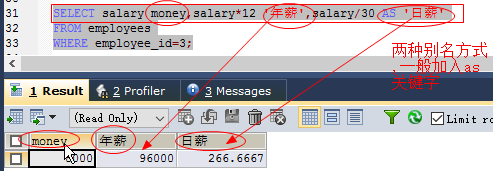
- 如果别命中使用特殊字符,或者是强制大小写敏感或有空格时,都可以通过为别名添加双引号实现
基本格式:
第一种: SELECT 列名 别名 第二种: SELECT 列名 as 别名 第三种: SELECT 列名 "别名" //或者:'别名' 如:SELECT salary money,salary*12 '年薪',salary/30 as '日薪';
缺省情况下查询显示所有行,包括重复行
SELECT 列名 FROM 表名;使用DISTINCT关键字可从查询结果中清除重复行
SELECT DISTINCT 列名 FROM 表名;DISTINCT的作用范围是后面所有字段的组合
SELECT DISTINCT 列名1,列名2 FROM 表名 WHERE condition; 如:(表示的是所有满足account=4的department) SELECT DISTINCT salary,department FROM employees WHERE account=djh-04
WHERE中的比较运算
基本格式:
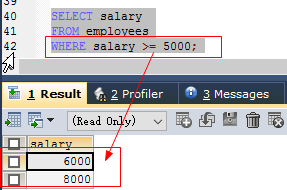
=(等于)、<>(不等于)、<(小于)、>(大于)、<=(小于等于)、>=(大于等于) SELECT 列名1,,列名2 FROM 表名 WHERE condition; 如: SELECT salary FROM employees WHERE salary >= 5000;- 有多项时使用”and”符连接,如:
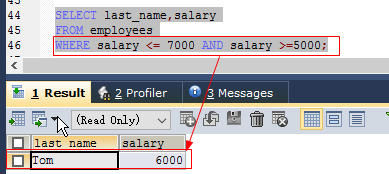
SELECT last_name,salary
FROM employees
WHERE salary <= 6000 AND salary >=5000;
其他比较运算符:
between…and… //在两个值之间(包含)
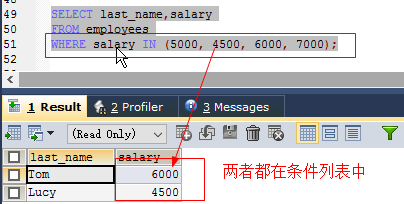
如: SELECT salary FROM employees WHERE salary between 5000 and 7000;in(list) //匹配所有列出的值
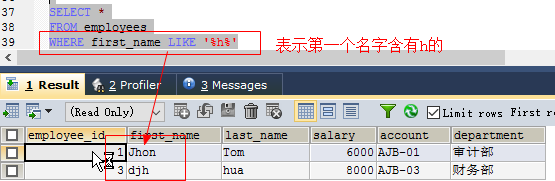
如: SELECT salary FROM employees where salary in (5000, 4500, 6000, 7000);like //匹配一个字符模式
- 使用like运算执行模糊查询
- 查询条件包含文字字符或数字
(%)可表示零或多个字符,(_)一个下划线表示一个任意字符
如: select * from employees where first_name like '%h%' //表示含有h的 或者 select first_name from employees where first_name like '__n%' //表示以n前面两个字母(两个下划线)开头的
- is null: //是空值
对结果集排序:
- 查询语句执行的查询结果,数据是按插入顺序排列
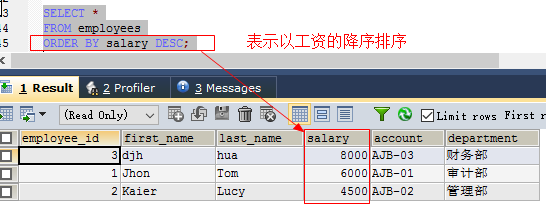
按某列排序采用:order by 列名[desc],列名…
如: 方式一:按薪资降序排列 select * from employees order by salary desc;方式二:按薪资的增序排列(默认的是增序排序) select * from employees order by salary asc;- 设定排序列的时候可以采用列名、列序号和列别名
MySQl常用函数:
常用函数分类:
字符串函数、数值函数、日期和时间函数、流程函数、其他函数、组函数字符串函数
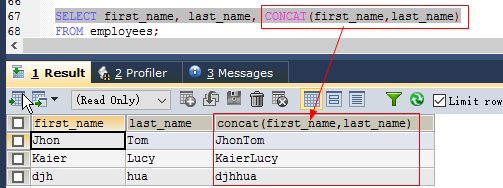
concat(str1,str2,…) //连接字符
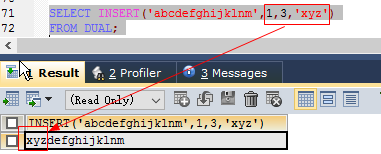
//SELECT CONCAT('abc','def') FROM DUAL; SELECT first_name, last_name, CONCAT(first_name,last_name) from employees;insert(str,pos,len,newstr) //字符串str从第pos位置开始的len个字符替换为新串newstr
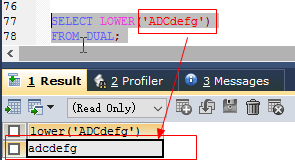
#注意这里的下角标是从1开始的 SELECT INSERT('abcdefghijklnm',1,3,'xyz') FROM DUAL;lower(str) //转成小写
select lower('ADCdefg') from dual;upper(str) //转成大写
//select upper('ADCdefg') from dual; select upper(first_name,last_name) from employees;trim(str) //去掉str字符串前缀和后缀的空格
SELECT TRIM(' abc ') FROM DUAL;replace(str,from_str,to_str) //用字符串to_str替换字符串str中的子串from_str
SELECT REPLACE('abcdefgxyz','xyz','XYZ') FROM DUAL;substring(str.ops,len) //返回从字符串str的pos位置起len个字符长度的子串
SELECT SUBSTRING('abcdXYZabcd',5,3) FROM DUAL; //返回XYZ- 注意:所有的pos都是包含的
数值常用函数:
1)、abs(x) //返回x的绝对值 2)、ceil(x) //返回不小于x的最小整数 3)、floor(x) //返回不大于x的最大整数 4)、mod(x,y) //返回x/y的模(余数) 5)、rand() //返回一个0~1之间的随机浮点数 6)、round(x,y) //返回参数x的四舍五入的有y位小数的值日期和时间常用函数:
- curdate() //返回当前日期
- curtime() //返回当前时间
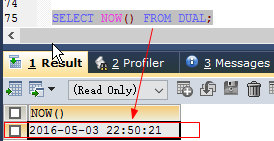
‘now()’ //返回当前的日期和时间
SELECT NOW() FROM DUAL; //格式如:2016-04-14 09:20:48- week(date) //返回指定日期为一年中的第几周
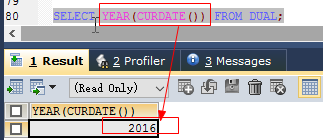
year(date) //返回日期的年份
SELECT YEAR(CURDATE()) FROM DUAL;- hour(time) //返回time的小时值
- minute(time) //返回time的分钟值
monthname(time) //返回date的月份名
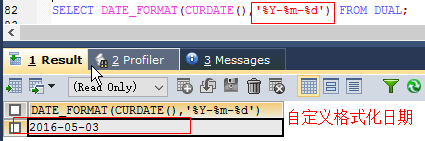
SELECT MONTHNAME(CURDATE()) FROM DUAL;‘date_format(date,fmt)’ //返回按字符串fmt格式化日期date值
SELECT DATE_FORMAT(CURDATE(),'%Y-%m-%d') FROM DUAL; //Y表示四位数的年份SELECT DATE_FORMAT(CURDATE(),'%y-%m-%d') FROM DUAL; //y表示两位数的年份- datediff(expr1,expr2) //返回起始时间expr1和结束时间expr2之间的天数
聚合函数(组合函数):
一组数值进行运算,并返回单个值
统计行数
count(*)或者count(列名) //注意,count不统计NULL值平均值
avg(数值类型列名)求和
sum(数值类型列名)
最大值
max(列名)最小值
min(列名)如:
SELECT AVG(salary) AS AVG,SUM(salary) AS SUM,MAX(salary) AS MAX, MIN(salary) AS MIN,COUNT(salary) AS COUNT FROM employees;
- 除了count()以外,聚合函数否会忽略null值.
对查询出来的数据进行分组
group by- 分组的含义:把该列具有相同值的多条记录当成一组记录处理,最后只输出一条记录
格式
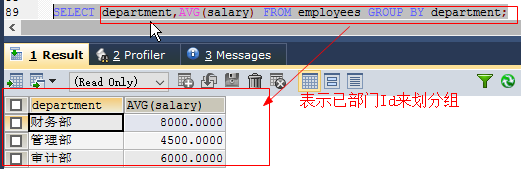
select column1,...,group_function from 表名 [where condition] [group by group_by_expression] [order by column];分组函数规则:
如果使用了分组函数,或者使用group by的查询:出现在delect列表中的字段,要么出现在组合
函数里,要么出现在group by子句中如: SELECT department,AVG(salary) FROM employees GROUP BY department;- group by子句的字段可以不出现在select列表当中
- 使用集合函数可以不适用group by子句,此时所有的查询结果作为一组
如:
SELECT department,SUM(salary),MAX(salary),AVG(salary) FROM employees GROUP BY department;
限定组的结果:
having子句用来对分组后的结果再进行条件过滤
格式:
select column,group_function from 表名 [where condition] [group by broup_by_expression] [having group_condition] [order by column];where和having都是用来做条件限定的,但是having只能用在group by之后;
where子句中不能使用组函数,不能在where子句中限制组
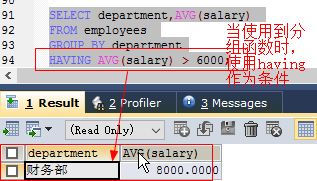
-如:SELECT department,AVG(salary) FROM employees GROUP BY department HAVING AVG(salary) > 6000;
MySQL特有—>查询结果限定(常用来分页)
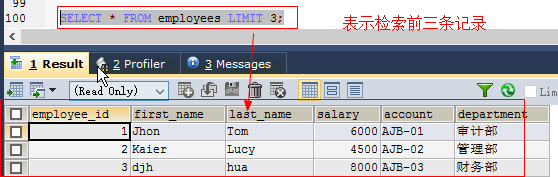
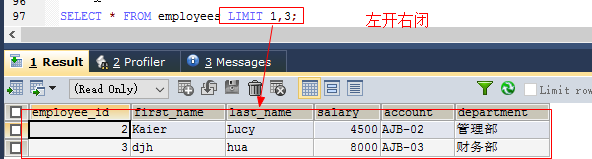
格式:
select ... limit offset_start,row_count; //offset默认为0,表示第一个返回记录行的偏移量 //row_count表示要返回记录行的最大数目 如: select * from employees limit 3; //检索前3个记录select * from employees limit 1,3; //检索记录行5~7(左开右闭)
多链表查询
- 使用单个select语句从多个表中取出相关的数据,通过多表之间的关系,构建相关数据查询
- 多表链接通常是建立在相互关系的斧子表上的
多表链接查询语法:
select ... from join_table join_type join_table on join_condition where where_condition //join_table:参与连接的表 //join_type:连接类型(内连接、外连接、交叉连接、自连接) //join_condition:连接条件 //where_condition:where过滤条件不加入条件时会产生笛卡尔积
其语法格式为:
select ... from join_table cross join join_table2; 等效于:select ... from table1, table2; //这种条件下返回的是两张表记录的乘积如:
//方式一(标准方式) ELECT * FROM tb_emp CROSS JOIN tb_dept; //方式二 SELECT * FROM tb_emp,tb_dept;
内连接:
语法格式:
select ... from join _table [inner] join join_table2 [on join_codition] where where_definition //连接条件就是主外键关联- 内连接只列出这些连接表中与连接条件相匹配的数据航
- 内连接分类:
- 等值连接:在连接条件中使用等号(=)运算符来比较被连接列的列值
- 非等值连接::在连接条件中使用除等号运算符以外的其他比较运算符来比较被连接的列的列值
- 自然连接:在等值连接的基础上,使用选择列表指出查询结果集合中所包含的列,并删除连接表中的重复列
如:
//方式一: SELECT * FROM tb_emp,tb_dept WHERE tb_emp.DEPTNO = tb_dept.DEPTNO; //主外键关联DEPTNO //方式二:(标准方式) SELECT * FROM tb_emp INNER JOIN tb_dept ON tb_emp.DEPTNO = tb_dept.DEPTNO; //主外键关联DEPTNO
外连接:
语法格式:
select ... from join_table (left|right|full) [outer] join join_table2 on join_codition where where_definition- 不仅列出与连接条件相匹配的行,还列出左表(左外连接)、右表(右外连接)或两个表(全外链接)中所有符合where过滤条件的数据行
自连接: 参与连接的两个表来自同一张表
如:
select c.name '类别名' c2.name '父类别名' from tb_course c left join tb_course c2 on c.pid=c2.id
子查询:
简介:
- 进行查询时,需要的条件时另一个select语句的结果时,使用子查询
用于子查询的关键字主要包含:
in、not in、=、<>(表示不等于)
- 一般子查询的效率低于连接查询,表连接都可以用子查询替换,但反过来却不一定
如:
//查询工资bi'艾伦'高的所有员工信息 SELECT * FROM tb_emp WHERE sal > ( SELECT sal FROM tb_emp WHERE ename='艾伦' );any 与子查询返回的每一个值比较(小于子查询的任意一个结果),如:
select * from tb_emp where sal<any( select sal from tb_emp where job='市场销售' );all 与子查询返回的所有值比较(要小于子查询所有的结果),如:
SELECT * FROM tb_emp WHERE sal<all( SELECT sal FROM tb_emp WHERE job='市场销售' );
索引
- 概念:
- 模式(schema)中的一个数据库对象
- 在数据库中用来加速对表的查询
- 通过使用快速路径访问方法快速定位数据,减少磁盘I/O
- 与表独立存放,但是不能独立存在,表被删除时,该表的索引自动被删除
创建索引
- 自动创建:自动在主键和唯一键上创建索引
- 手动创建:在一列或者多列上创建索引
语法格式:
create index 索引名 on table(column1,...);如:
CREATE INDEX emp_list_name_idx ON employees(first_name,last_name);
表的列很少,不适合建立索引,查询数据库时优先查找索引页;当执行过多次的insert、delete、update后;会出现索引碎片;影响查询速度;应该对索引进行重组,如:
drop index index_name; create index index_name on table(column,...);
- 概念:
视图:
- 优点:
- 限制对数据的访问
- 使复杂的查询变得简单
- 提供了数据的独立性
- 提供了对相同数据的不同显示
创建视图:
基本格式语法:
create view 视图名 as select 列名 [as 别名],... from 表名 [where condition];如:创建视图名为emp_v_10的视图,包括10号部门的所有雇员信息
create view emp_v_10 as select employee_id,last_name,salary from employees where department=10;
查询视图结构:
desc emp_v_10;或者describe emp_v_10;查询视图参数:
select * from emp_v_10;修改视图:
create or replace view;如:
create or replace view emp_v_10 (id,name,sal,dept) as //为每个列指定列名 select employee_id,last_name,salary,department from employees where department=10;
在create view语句中字段与子查询中的字段必须一一对应,否则就别指定别名,或在子查询中指定别名,创建复杂视图,如:从两个表中查询数据
create view dept_emp_dv_10 (部门,最低工资,最高工资,平均工资) as select d.name,min(e.sal),max(e.sal),avg(e.sal) from tb_emp e, tb_emp d where e.deptno = d.deptno; and e.deptno=10; //查询视图数据 select * from dept_emp_dv_10;
- 优点:
- 关于DROP、TRUNCATE以及DELETE
- delete删除数据,保留表结构,可以回滚,如果数据量大,很慢(两步操作:删除、备份),回滚就是备份删除的数据
- truncate删除所有数据,保留表结构,不可以回滚,一次删除所有数据,速度相对很快
- drop删除数据和表结构,删除熟读最快(直接从内存移除数据)
软件的项目开发周期一般为:
需求分析→概要设计→详细设计→代码编辑→软件测试→安装部署(发表)
















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









