






>>> from sklearn.preprocessing import OneHotEncoder
>>> enc = OneHotEncoder()
>>> enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
>>> enc.n_values_
array([2, 3, 4])
>>> enc.feature_indices_
array([0, 2, 5, 9]) >>> enc.transform([[0, 1, 1]]).toarray() array([[ 1., 0., 0., 1., 0., 0., 1., 0., 0.]])注意:仅仅是数值型字段才可以,如果是字符类型字段则不能直接搞定
需要使用pandas get_dummies搞定
例如:
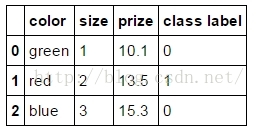
Using the get_dummies will create a new column for every unique string in a certain column:使用get_dummies进行one-hot编码
- pd.get_dummies(df)
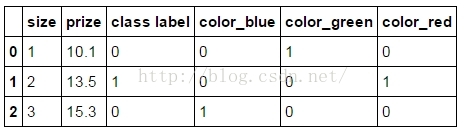
还可以:
import pandas as pd import numpy as np from sklearn_pandas import DataFrameMapper from sklearn.preprocessing import OneHotEncoder data = pd.DataFrame({'text':['aaa', 'bbb'], 'number_1':[1, 1], 'number_2':[2, 2]}) # number_1 number_2 text # 0 1 2 aaa # 1 1 2 bbb # SomeEncoder here must be any encoder which will help you to get # numerical representation from text column mapper = DataFrameMapper([ ('text', SomeEncoder), (['number_1', 'number_2'], OneHotEncoder()) ]) mapper.fit_transform(data)















 1811
1811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









