






昨天OpenAI低调发布GPT-4o的现场秀一点儿都不低调。
GPT-4o参与多人场景下的语音聊天,充当翻译,现场语音辅导作业,按要求提供合理的提示而不直接抛出答案,看懂人脸表情,饱含人类感情的语音回答(那句“stop it”的回答简直了...),让我感到震撼。Google发布Gemini时制作的视频“愿景”,如今被GPT-4o实现了。
GPT-4o的这个‘o’代表Omni-全能,从现场live show的表现来看,包含了听、说、看、情感感知和情感表达能力,这和通常意义上我们期望的智能机器人所需要具备的能力还有多少差距呢?“全能”实至名归。
上Azure云看了一下,在美东地区有资源上线,于是就试用了一下。目前还只是预览版,只能通过训练场Playground方式试用。
看了一圈,好像还没有语音接口,只有上传图片的功能,可以直接贴到对话框,跟微信聊天窗贴图一样。那就测一下图片识别和对话吧。
先做了几个对话,响应速度相当快,比Azure云原有的GPT-4和 GPT-4Turbo快很多,差不多赶上3.5的速度了,体验比官方的“速度是GPT-4的两倍”的说法还好一些。
贴上一个图片,看GPT-4o是否看得懂,
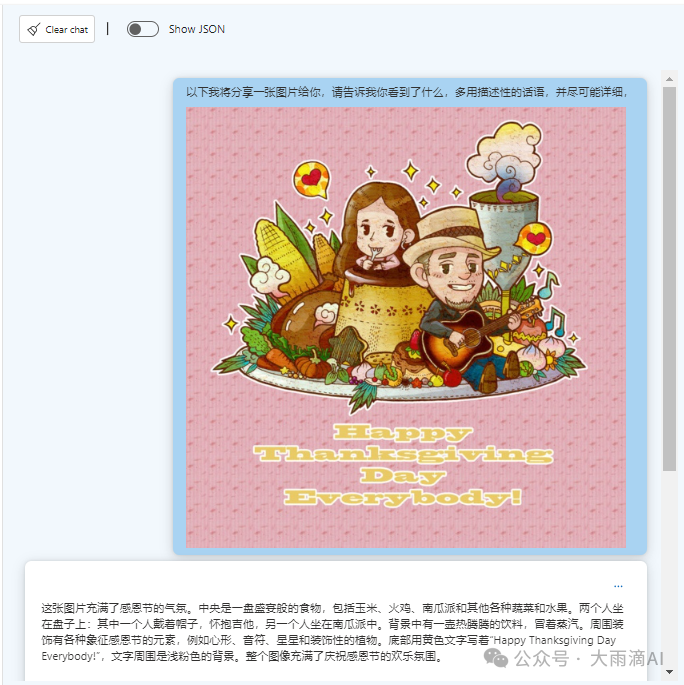
GPT-4o回复如下,
这张图片充满了感恩节的气氛。中央是一盘盛宴般的食物,包括玉米、火鸡、南瓜派和其他各种蔬菜和水果。两个人坐在盘子上:其中一个人戴着帽子,怀抱吉他,另一个人坐在南瓜派中。背景中有一壶热腾腾的饮料,冒着蒸汽。周围装饰有各种象征感恩节的元素,例如心形、音符、星星和装饰性的植物。底部用黄色文字写着“Happy Thanksgiving Day Everybody!”,文字周围是浅粉色的背景。整个图像充满了庆祝感恩节的欢乐氛围。进一步提问,
再贴一个表格图片,让GPT-4o提取文本并整理。表格是随便找的,直接看一下效果,
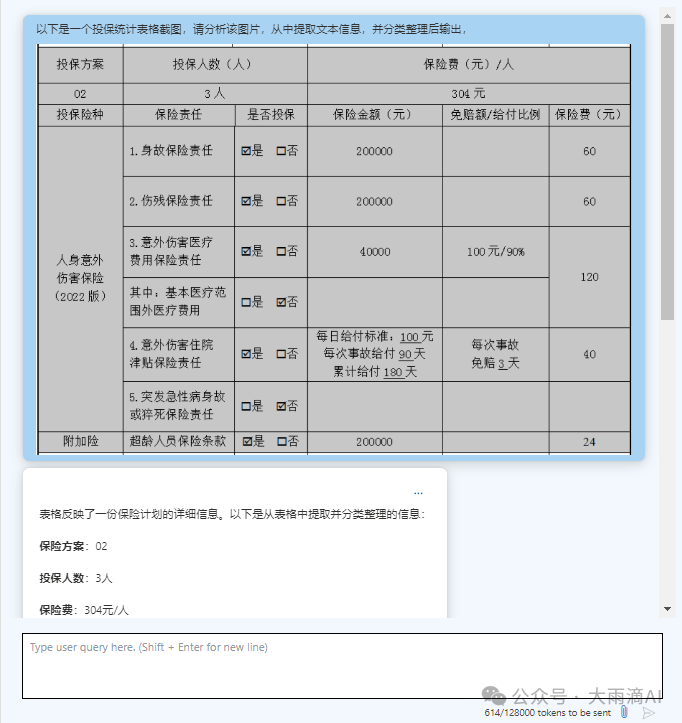
来看GPT-4o提取的信息,
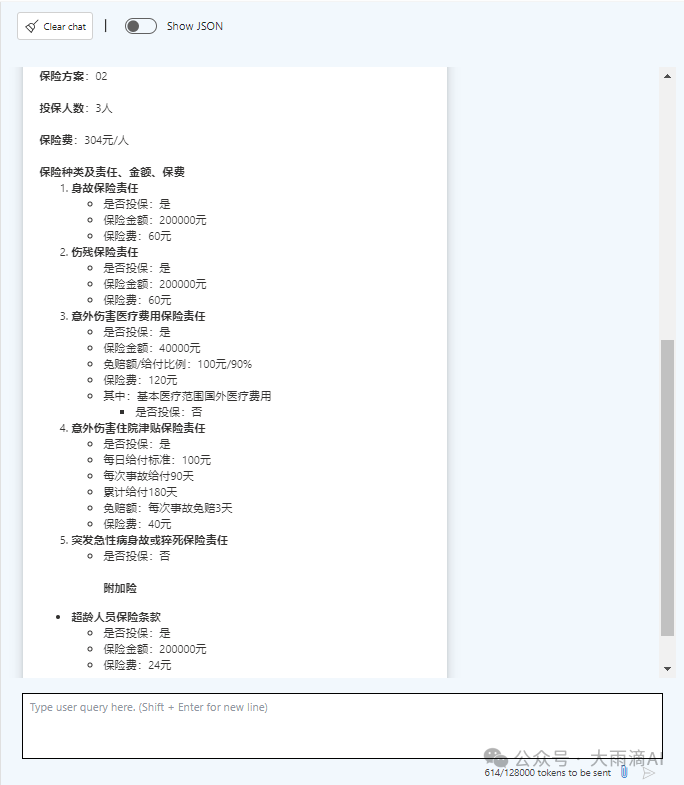
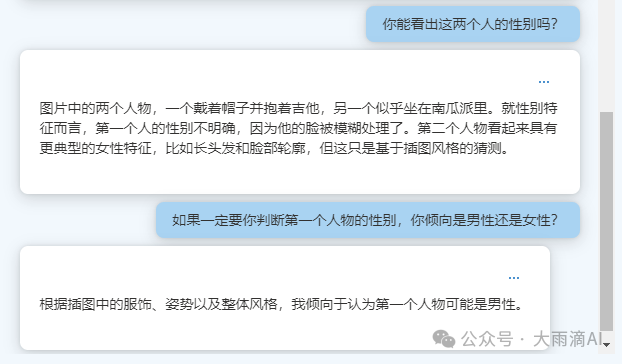
不能说perfect,但也已经接近完美了。发布会现场秀上它能读懂工程师用Marker笔在白纸上一行一行书写的数学公式,还可以理解。而从以上测试来看,GPT-4o不仅能看懂复杂图片,还能理解各部分之间的内容关系,并关联它们,这让我惊喜,也夹杂着些许危机感。
比如,表格图片的最上面两行内容,

GPT-4o识别到第一行是标题,第二行是内容,于是给出这样的输出,

再如,表格图片中通过在 “是” 和 “否” 选项前打勾来标识选择,GPT-4o也全部正确的识别并理解到,并且把标题栏中的单位都正确的带入下面每一行对应的数字中了,

还有,图片中有单元格内容的多行书写,有些是不同项,有些只是一句话的换行,

GPT-4o也不出意外的正确识别和get到了,

各位道友不要以人脑的抽象认知能力来评价AI,认为以上图片,表格的理解是很简单的。相反,让AI具有抽象识别能力是一件很难的事情。
当然通过OCR图像字符识别技术,也能够正确识别出以上所有文字内容片段,但却无法进一步关联这些片段。要进一步识别内容间的关系,需要辅助程序,即使有这样的辅助程序,也很难想象需要多么复杂的逻辑去识别和关联不同部分之间的内容,如果表格的格式再是各式各样的,那就更难了。
但是现在AI做到了,只需要1秒,还不担心表格的格式影响。一瞬间,让我感觉前一篇文章介绍的 OCR 技术不香了,再前面那篇介绍的语音识别和语音合成技术也没啥感觉了。
从一开始就坚信AI大模型一定会发展语音、图像的感知和情感交流能力,只是没想到这么快。GPT-4o的出现改变了AI的应用方式,扩展到更多的应用场景,AI应用框架也将被改写和大幅简化(这倒是好事情,只是干IT的也太甜蜜的苦逼了),不久前才学来的技术看上去已经可以丢进垃圾桶了。
嗯,容我再想想...


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









