







本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:5万字带你领略Post-Training的5大范式 | DeepSeek-R1领衔构建LLM后训练新生态

大语言模型(LLMs)的出现从根本上改变了自然语言处理领域,使它们在从对话系统到科学探索的各个领域变得不可或缺。然而,它们的预训练架构在特定领域往往存在局限性,包括推理能力受限、伦理不确定性以及特定领域性能不佳。这些挑战需要High-Level后训练语言模型(PoLMs)来解决这些不足,如OpenAI-o1/o3和DeepSeek-R1(统称为大型推理模型,简称LRMs)。本文首次全面概述了PoLMs,系统地追踪了它们在五个核心范式中的演变:微调,提高特定任务的准确性;对齐,确保伦理一致性和与人类偏好的对齐;推理,尽管奖励设计存在挑战,但推进多步推理;效率,在日益复杂的背景下优化资源利用;以及集成和适应,在解决连贯性问题的同时扩展跨多样式的功能。
从2018年ChatGPT的基础对齐策略到2025年DeepSeek-R1的创新推理进步,作者展示了PoLMs如何利用数据集来减轻偏差、深化推理能力并提高领域适应性。作者的贡献包括对PoLM演变的开创性综合、一个结构化的分类法,将技术和数据集进行分类,以及一个战略议程,强调LRMs在提高推理能力和领域灵活性方面的作用。作为该领域首次此类规模的调查,这项工作巩固了最近的PoLM进展,并为未来的研究建立了一个严谨的智力框架,促进LLMs在科学和社会应用中的精确性、伦理稳健性和多功能性发展。
1 引言
人们普遍认为,真正的智能赋予作者推理能力,使作者能够检验假设,并为未来的可能情况做好准备。
语言模型(LMs)[1, 2]代表了一种复杂的计算框架,旨在模拟和生成人类语言。这些模型通过使机器能够以接近人类认知的方式理解、生成和与人类语言互动,从而彻底改变了自然语言处理(NLP)[3]领域。与人类通过互动和接触语境环境自然习得语言技能不同,机器必须经过大量的数据驱动训练才能发展出类似的能力[4]。这提出了一个重大的研究挑战,因为使机器能够理解和生成人类语言,同时进行自然、语境适当的对话,不仅需要庞大的计算资源,还需要精细的模型开发方法[5, 6]。
大语言模型(LLMs)如GPT-3 [7]、InstructGPT [8]和GPT-4 [9]的出现标志着语言模型(LM)演变过程中的一个转型阶段。这些模型以其广泛的参数化和High-Level学习能力而著称,旨在捕捉大量数据集中的复杂语言结构、上下文关系和细微模式。这使得LLMs不仅能够预测后续单词,还能在包括翻译、问答和摘要在内的广泛任务中生成连贯、上下文相关的文本。LLMs的发展引发了显著的学术兴趣 [5, 6, 10],可以分为两个主要阶段:预训练和后训练。
预训练。预训练的概念源于计算机视觉(CV)任务中的迁移学习[10]。其核心目标是利用大量数据集开发一个通用模型,这有助于为各种下游应用进行轻松微调。预训练的一个显著优势是能够利用任何 未标注 的文本语料库,从而提供丰富的训练数据来源。然而,早期的静态预训练方法,如神经网络语言模型(NNLM)[11]和Word2vec[12],在适应不同的文本语义环境方面存在困难,这促使动态预训练技术如BERT[2]和XLNet[13]的发展。BERT通过利用Transformer架构并在大规模 未标注 数据集上采用自注意力机制,有效地解决了静态方法的局限性。本研究建立了“预训练和微调”学习范式,激发了后续许多研究,这些研究引入了包括GPT-2[14]和BART[15]在内的各种架构。
训练后。训练后是指模型经过预训练后所采用的技巧和方法,旨在对模型进行细化和适应,以满足特定任务或用户需求。随着GPT-3 [7]的发布,其拥有175亿个参数,训练后领域经历了显著的兴趣和创新的增长。出现了各种方法来提升模型性能,包括微调[16, 17],使用 Token 数据集或特定任务数据调整模型参数;对齐策略[18, 19, 20],优化模型以更好地与用户偏好对齐;知识适应技术[21, 22],使模型能够融入特定领域的知识;以及推理改进[23, 24],增强模型进行逻辑推理和决策的能力。这些技术统称为训练后语言模型(PoLMs),它们导致了GPT-4 [9]、LLaMA-3 [25]、Gemini-2.0 [26]和Claude-3.5 [27]等模型的发展,标志着LLM能力的重大进步。然而,训练后的模型通常难以适应新任务,而无需重新训练或进行重大参数调整,这使得PTM开发成为一个活跃的研究领域。
如前所述,预训练语言模型(PLM)的主要目标是提供通用知识和能力,而PoLM则专注于将这些模型适应于特定的任务和需求。这一适应的一个显著例子是最新的大语言模型(LLM)DeepSeek-R1 [28],它展示了PoLM在增强推理能力、与用户偏好保持一致以及提高跨多个领域的适应性方面的演变 [29]。此外,开源LLM(例如LLaMA [30]、Gemma [31]和Nemotron [32])以及特定领域的的大型数据集(例如PromptSource [33]和Flan [34])的日益可用,正推动学术研究行人和行业从业者开发PoLM的趋势。这一趋势强调了在PoLM领域对定制化适应日益增长的认识。
在现有文献中,预训练语言模型(PLMs)已被广泛讨论和综述[10, 35, 36, 37],而后训练语言模型(PoLMs)则很少被系统性地回顾。为了推进这些技术,深入考察现有研究成果以识别关键挑战、差距和进一步改进的机会是至关重要的。本综述旨在填补这一空白,通过提供一个结构化的框架来概述后训练领域的研究进展。如图1所示,它探讨了后训练的多个阶段,特别关注ChatGPT到DeepSeek所采用的方法。这些技术涵盖了广泛的方法,包括微调、大语言模型对齐、推理增强和效率提升。图中的蓝色部分特别突出了DeepSeek所应用的后训练方法集,强调了其成功适应用户偏好和特定领域需求的创新策略。
1.1 主要贡献
本文对PoLMs进行了首次全面综述,对领域内的最新进展进行了全面、结构化的探讨。虽然之前的综述通常关注LLM发展的特定方面,如偏好对齐[38]、参数高效的微调[39]和LLM的基础技术[40],但它们主要集中在狭窄的子主题上。相比之下,本综述采取了一种整体方法,提供了对在训练后常用核心技术的全面回顾,并对它们进行了系统分类。此外,作者调查了与这些方法相关的数据集和实际应用,如图2所示,并确定了未来研究的开放挑战和有希望的方向。
本综述的主要贡献如下:
-
• 全面历史综合。作者提供了对PoLMs的首次深入综合分析,追溯了其从ChatGPT的初始基于人类反馈的强化学习(RLHF)到DeepSeek-R1的创新冷启动RL方法的演变过程。这一综合分析涵盖了关键技术(即微调、对齐、推理、效率和集成与适应),分析了它们的发展及其相关挑战,如计算复杂性和伦理考量。通过将这一进展呈现为一个连贯的叙事,并丰富以关键POST-TRAINING-OF-LLM,作者为研究行人提供了近年来后训练演变的全面概述,为该领域提供了基础性资源。
-
• 结构化分类和框架。作者引入了一个结构化分类,如图2所示,将训练后方法分为五个不同的类别,并将数据集组织为七种类型,同时将应用框架构建在专业、技术和交互式领域。这个框架阐明了这些方法的相互关系和实际影响,提供了一个系统性的发展视角。通过提供明确的分类和分析洞察,作者提高了新手和专家的可访问性和理解度,为导航训练后研究的复杂性提供了一个全面的指南。
-
• 未来方向。作者强调了新兴趋势,特别是大型推理模型(LRMs)如o1[41]和DeepSeek-R1[28]的兴起,这些模型利用大规模强化学习来推动推理的边界。作者强调,持续进步对于进一步增强推理能力和领域适应性至关重要。作者的分析确定了关键挑战,包括可扩展性限制、伦理一致性风险和多模态集成障碍。作者提出了如自适应强化学习框架和公平性感知优化等研究途径。这些方向旨在推动模型在训练后的进一步发展,确保大型推理模型达到更高的精度和可靠性,以满足未来的需求。
1.2 组织结构
本调查系统地组织了对后训练语言模型(PoLMs)的全面探索,涵盖了其历史演变、方法、数据集、应用和未来发展趋势。第二章提供了PoLMs的历史概述。第三章探讨了微调,包括第三章1.1节中的监督微调(SFT)和第三章3.3节中的强化微调(RFT)。第四章讨论了对齐问题,涵盖了第四章1.1节中的人反馈强化学习(RLHF)、第四章2.1节中的AI反馈强化学习(RLAIF)和第四章3.1节中的直接偏好优化(DPO)。第五章专注于推理,包括第五章1.1节中的自我改进方法和第五章2.1节中的推理强化学习。第六章概述了效率提升方法,包括第六章1.1节中的模型压缩、第六章2.2节中的参数高效微调(PEFT)和第六章3.1节中的知识蒸馏。第七章研究了集成和适应,包括多模态方法、领域适应和模型合并。第八章回顾了后训练中使用的数据集。第九章探讨了大语言模型(LLM)的应用。第十章评估了开放问题和未来方向。最后,第十一章以总结和研究展望结束。
2 概述
2.1 PoLMs的历史
LLM的进步构成了自然语言处理(NLP)中的一个关键章节,其中后训练方法在它们从通用预训练架构向专用、任务自适应系统演变的过程中起到了关键的催化作用。本节概述了后训练语言模型(PoLMs)的历史轨迹,从BERT [2] 和GPT [1] 等基础预训练里程碑的发展,到当代模型如01 [41] 和DeepSeek-R1 [28] 所体现的复杂后训练范式。如图3所示,这一进展反映了从建立广泛的语用能力到增强任务特定适应性、伦理一致性、推理复杂性和多模态集成等方面的转变,标志着LLM能力的变革性旅程。
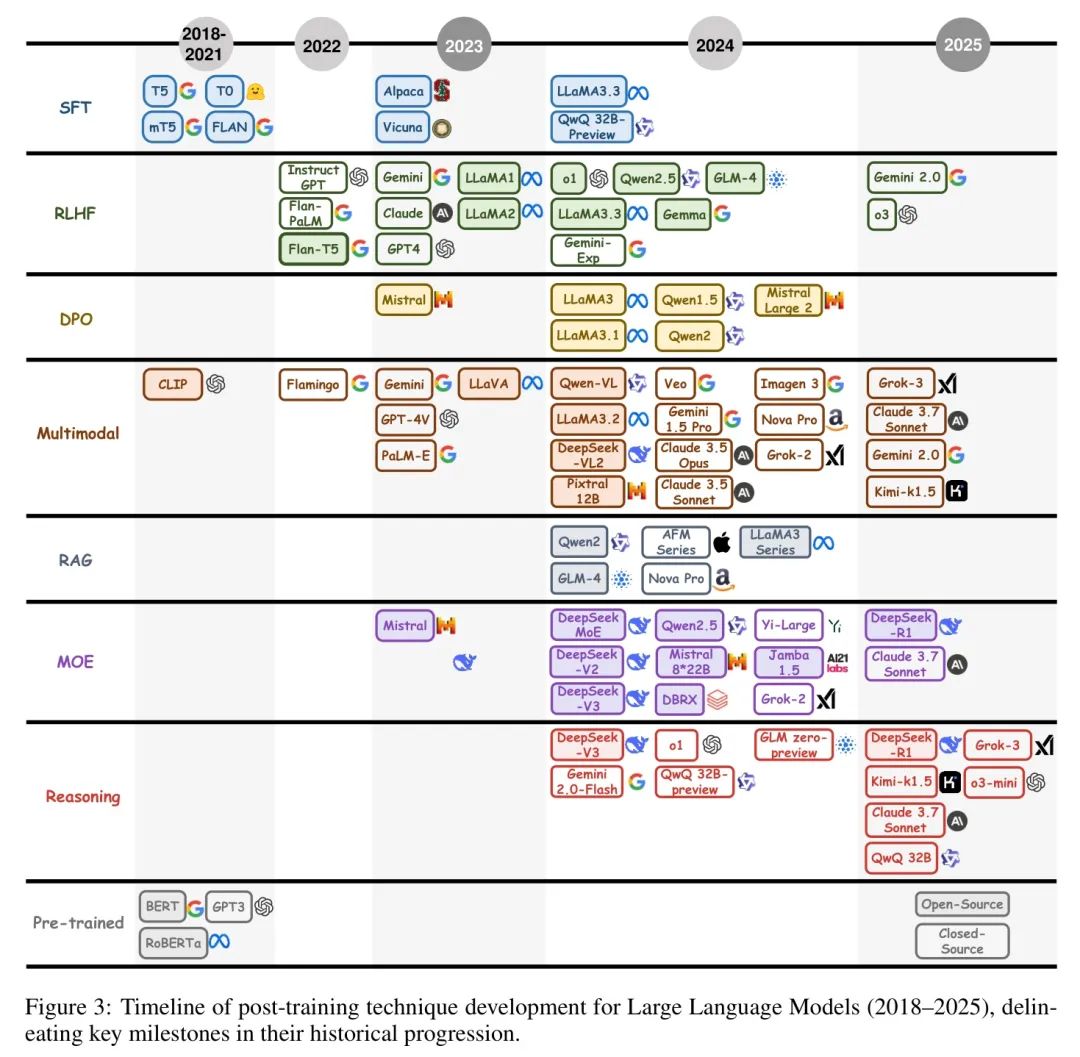
现代PoLMs的起源与2018年的预训练革命相吻合,这一革命由BERT[2]和GPT[1]的发布引领,重新定义了NLP基准。BERT的双向自编码框架,利用transformer架构和自注意力机制,在捕获问答等任务中的上下文依赖关系方面表现出色,而GPT的自回归设计优先考虑生成连贯性,为文本生成设定了先例。这些模型确立了“预训练和微调”范式,随后在2019年通过T5[42]进行了改进,该模型将各种任务统一在文本到文本的框架下,促进了多任务学习,并为训练后的进步奠定了坚实的基础。
从2020年开始,PoLMs的领域开始发生显著演变,这一演变是由对高效地将预训练模型适应于数据有限的各种任务的需求不断增长所驱动的。早期的创新,如prefix-tuning[43]和prompt-tuning[44],引入了轻量级的适应策略,通过修改模型输入而不是重新训练整个架构,实现了多任务灵活性,从而在拓宽适用性的同时节省了计算资源。这一时期还见证了用户中心优化的重要转变,2021年 Reinforcement Learning from Human Feedback (RLHF) [45] 的出现标志着这一转变,该技术利用人类评估来使模型输出与主观偏好对齐,增强了在对话场景中的实用性。到2022年,随着Proximal Policy Optimization (PPO) [46] 的采用,RLHF成熟起来,优化了对齐稳定性并减轻了对噪声反馈的过拟合。2022年末ChatGPT的发布[9]将这些进步具体化,展示了RLHF在创建响应式、用户对齐的LLM方面的变革潜力,并催化了PoLMs研究的激增。同时,Chain-of-Thought (CoT) prompting [47] 作为一种推理增强策略出现,鼓励模型在复杂任务中阐述中间步骤,从而提高透明度和准确性,尤其是在逻辑推理和问题解决领域。
2022年至2024年间,PoLMs在解决领域特异性、伦理鲁棒性和多模态集成方面进行了多样化发展,反映了LLM精炼方法日益精细化的趋势。领域自适应技术,如检索增强生成(RAG)[48],出现以整合外部知识库,为特定领域提供语境丰富的输出,无需全面重新训练——这对于需要最新信息的专业应用来说是一项关键进步。伦理一致性努力在2023年加强,直接偏好优化(DPO)[49]通过直接优化模型输出以符合人类偏好,绕过中间奖励建模,提高了效率和鲁棒性。同时,对多模态能力的追求也取得了进展,PaLM-E [50]和Flamingo [51]等模型开创了视觉-语言集成,随后BLIP-2 [52]和LLaVA [53]将这些努力扩展到更广泛的领域,如医学成像。效率创新与这些发展并行,特别是通过专家混合(MoE)架构;2022年,谷歌的Switch-C Transformer [54]引入了在2048个专家中Sparse激活1.6万亿参数,而Mixtral [55]则进一步优化了这一范式,平衡了可扩展性和性能。在此期间,推理增强,如自我博弈[56]和蒙特卡洛树搜索(MCTS)与CoT [57]的集成,通过模拟迭代推理路径,进一步增强了LLM的决策能力,为以推理为重点的High-Level模型奠定了基础。
随着专家混合(MoE)模型的出现,在计算效率优化和参数规模扩展方面取得了显著的架构进步。这些模型与传统密集架构不同,通过动态激活选择性参数子集,从而在平衡资源需求与性能提升之间找到了平衡点。这一范式由谷歌在2022年推出的Switch-C Transformer [54] 领先提出,该模型拥有1600亿个参数,分布在2048个专家中,开创了一种突破性的方法。后续的迭代,如Mixtral [55] 和DeepSeek V2.5 [58]——后者利用了2360亿个总参数,其中210亿个参数在160个专家中活跃——进一步优化了这一框架,在LMSYS基准测试中取得了最先进的结果,并证明了SparseMoE架构在可扩展性和有效性方面可以与密集模型相媲美。这些进展强调了向以效率为导向的PoLMs转变,使LLM能够以较低的计算开销处理复杂任务,这是扩大其实际应用范围的关键一步。到2025年,DeepSeek-R1 [28] 作为PoLMs创新的里程碑出现,摆脱了对传统监督微调(SFT)的依赖,转而采用思维链(CoT)推理和探索性强化学习(RL)策略。以DeepSeek-R1-Zero为例,该模型集成了自我验证、反思和扩展的CoT生成,验证了在开放研究范式下,RL驱动的推理激励,并引入了蒸馏技术 [28] 将复杂的推理模式从大架构转移到小架构。这种方法不仅比独立RL训练提供了更优越的性能,而且预示了一个以推理为中心的可扩展范式,为LLM解决训练后方法中持续的计算效率和任务适应性挑战做好了准备。
2.2 PoLMs的公式基础
2.2.1 政策优化原理
近端策略优化(PPO)算法[46]是一种关键的强化学习技术,尤其在需要保持稳定性和效率的设置中非常有用,例如带有人类反馈的强化学习(RLHF)[45]。PPO通过限制策略更新的规模来实现这些目标,确保模型行为的变化是渐进和可控的,从而防止性能的灾难性转变。这在微调大规模语言模型时尤为重要,因为剧烈的策略更新可能导致不可接受或不可预测的行为。

2.2.2 强化学习与人类反馈的原理
强化学习结合人类反馈(RLHF)是一种通过在学习过程中利用人类生成的反馈来使模型与人类偏好对齐的关键方法。这种方法结合了一个奖励函数,该函数明确捕捉人类输入,使模型能够更好地适应用户偏好和现实世界应用。

该目标函数代表了一个标准的强化学习问题,其中模型通过与环境交互,在人类反馈的指导下学习最大化预期奖励。
2.2.3 DPO原则
直接偏好优化(DPO)在强化学习与人类反馈(RLHF)的基础上,通过直接根据人类偏好优化模型输出,这些偏好通常以成对比较的形式表达。DPO消除了传统奖励函数的需求,转而通过最大化基于偏好的奖励来优化模型行为。

2.2.4 GRPO原理
组相对策略优化(GRPO)算法是强化学习中近端策略优化(PPO)算法的一种变体,首次在DeepSeek的先前工作中提出,即《DeepSeekMath:推动开放语言模型中数学推理的极限》[64]。GRPO省略了评论员模型,而是使用组分数估计 Baseline ,与PPO相比,这显著降低了训练资源消耗。

3 PoLMs用于微调
微调是适应预训练大语言模型(LLMs)到特定任务的关键,通过有针对性的参数调整来提升其能力。这个过程利用 Token 或特定任务的语料库来优化性能,弥合通用预训练和特定领域需求之间的差距。本章探讨了三种主要的微调范式:监督式微调(3.1),它使用标注数据集来提高特定任务的准确性;自适应微调(3.2),通过指令调整和基于 Prompt 的方法定制模型行为;以及强化式微调(3.3),它将强化学习集成到迭代优化输出中,基于奖励信号,通过动态交互促进持续改进。
3.1 监督微调
监督微调(SFT)[45]通过利用特定任务的 Token 数据集来调整预训练的大语言模型。与依赖于指令 Prompt 的指令调整不同,SFT直接使用标注数据调整模型参数,从而产生既精确又符合语境的模型,同时保留广泛的泛化能力。SFT弥合了预训练期间编码的广泛语言知识与针对应用的具体需求之间的差距[36]。通过接触大量语料库,预训练的大语言模型获得了通用的语言模式,减少了在微调过程中对大量领域特定数据的依赖。模型选择至关重要:在资源受限且数据集有限的设置中,较小的模型如T5[42]表现出色,而较大的模型,如GPT-4[9],则利用其优越的容量在复杂且数据丰富的任务中表现出色。
3.1.1 SFT数据集准备
构建高质量的SFT数据集是一个多方面的过程,对于微调的成功至关重要。

3.1.2 SFT过程
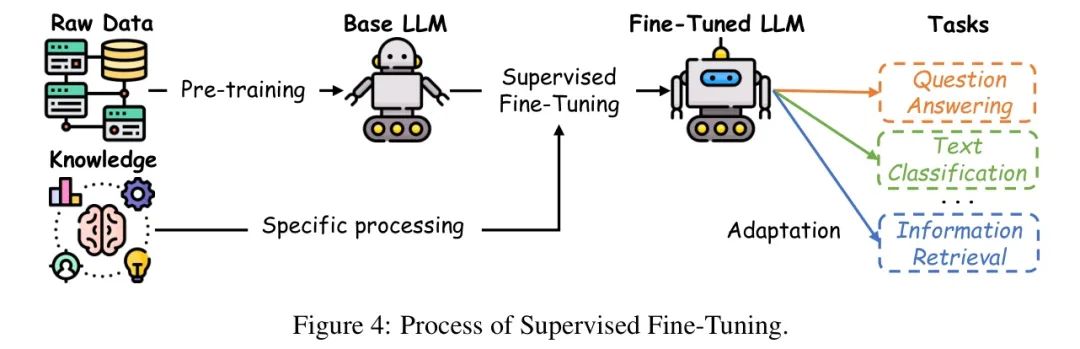
如图4所示,一旦数据集准备就绪,微调过程便以预训练的LLM开始,通常通过在大规模原始数据集上的无监督或自监督预训练获得。这一预训练阶段的目标是获取适用于各种任务的通用特征表示[36]。随后,在微调阶段,使用特定任务的标注数据调整模型参数,使模型符合特定应用的需求。此阶段常用的目标函数是交叉熵损失。对于一个具有N个样本和C个类别的分类任务,它可以表示为:

一个突出的例子是BERT模型[2],它在广泛的语料库(如BooksCorpus和Wikipedia)上进行了广泛的预训练。在微调阶段,这些广泛的表示通过特定任务的数据(例如,用于情感分析的IMDB数据集[91])进行细化,使BERT能够专门从事情感分类和问答等任务。
3.1.3 全参数微调
全参数微调是指调整预训练模型所有参数的过程,与仅修改参数子集的参数高效方法(如LoRA [92] 或 Prefix-tuning [43])相对。全参数微调通常适用于需要高精度的任务,例如医疗和法律领域 [93] 的任务,但它涉及到大量的计算开销。例如,微调一个包含65亿参数的模型可能需要超过100 GB的GPU内存,这在资源受限的环境中会带来挑战。为了缓解这些限制,引入了内存优化技术,如LOMO [93],它可以减少梯度计算和优化器状态的内存占用。模型的参数根据以下规则进行更新:

GPT-3到InstructGPT。全参数微调的一个显著例子是从GPT-3到InstructGPT [45],在该过程中,模型的所有参数集都使用针对指令跟随任务设计的语料库进行了微调。这种方法能够达到最佳性能,但由于需要更新所有参数,因此计算成本较高。
3.2 自适应微调
自适应微调通过修改预训练模型的行为,以更好地满足用户特定需求和处理更广泛的任务。这种方法引入了额外的线索来指导模型输出生成,提供了一个灵活的框架来定制模型的响应。自适应微调中的显著方法包括指令微调和基于 Prompt 的微调,这两种方法都通过引入特定任务的指导,显著增强了大语言模型的可适应性。
3.2.1 指令微调
指令微调[96]是一种通过在特别构建的指令数据集上微调基础LLM来精炼其的技术。这种方法显著提升了模型在多种任务和领域中的泛化能力,提高了其灵活性和准确性。如图5所示,该过程首先将现有的NLP数据集(例如文本分类、翻译和摘要的数据集)转换为自然语言指令,这些指令包括任务描述、输入示例、预期输出和示例演示。像Self-Instruct[86]这样的技术通过自动生成额外的指令-输出对,进一步增强了这些数据集的多样性,扩大了模型对更广泛任务的接触。微调过程调整模型的参数以与这些特定任务的指令相一致,从而产生一个在熟悉和之前未见过的任务上都能稳健执行的LLM。例如,InstructGPT[45]和GPT-4[7]在广泛的应⽤中展示了显著的指令遵循能力改进。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









